Data Enrichment
The following topics provide information about data enrichment:
• Lookups
Temporary Targets
When data has to be pre-processed or staged before writing to its destination, there are two recommended ways:
• Use a process design workflow with two or more transformation map steps: For large maps when complex transformation logic is required because it is easier to build and maintain.
• Use a temporary target within a single transformation map: For smaller maps when less complex logic is required.
A good example of using temporary targets is for the lookup use case. When you need to enrich a row of data from one source with a few fields of data from a second source, you can quickly build the lookup functionality using a temporary target. The temporary target (temp table) provides a graphical user interface for drag-and-drop mapping, which reduces the amount of scripting required and generally make it easier to build the transformation map.
You can also use multiple temporary targets but there are practical considerations:
• You must consider if the map is easier to build and maintain by dividing it into two different maps.
• You must consider the amount of data that will be managed within the temporary target as that is being stored in memory. If the amount of data exceeds the available RAM, then you must consider staging the data to a local disk and using two transformation steps in a process workflow to avoid thrashing.
Lookups
Using the Lookup functionality depends on a few dimensions such as size/number of records, frequency of change, and ease of implementation. For best results, see:
In most cases, you do not have to use the scripting functions to achieve the objective. From the Sources tab in the Map Editor, add a new source and select Lookup as the type.

Flatfile Lookups
Use Flat File Lookup for small and static lookup tables. You must manage the data in a flat file similar to any configuration file. At runtime, the engine loads the data into memory and indexes the table for maximum efficiency. These are suitable for small and predictable code tables (that is, state codes).
Incore Lookups
Use Incore Lookups for large and static lookup tables. These tables are dynamically built when the function is called so it will have the current data values stored in memory for efficiency. Also, there are several functions that allow you to dynamically iterate through and manage the table during runtime if you need more control than the temporary target provides.
Dynamic SQL Lookups
Use Dynamic SQL Lookups for very large and dynamic lookup tables. These are generally slower but will always return the most current value because a direct lookup is made to the database server when the function is called. Two ways to improve performance when using Dynamic SQL Lookups are:
• Use a View for efficiency on the server
• Use a Table with a clustered index
Performance
Regardless of the lookup type implemented, you can help to improve performance following these general rules:
• Minimize the overall size of the lookup table by only storing the rows and columns you need.
• Reduce the total number of lookup calls by sorting the source data and using the GroupStarted event condition.
If you choose to implement lookups using your own scripting functions, you must include the following guidelines:
• Use the TransformationStarted event to perform as many operations as possible to initialize and build the lookup table so it happens only once.
• If you make changes to the lookup table during execution, use events that mitigate the number of times the operations will occur such as GroupStarted or UserDefinedEvent.
• Make sure to use the TransformationEnded event to destroy object variables or close connections to reduce memory use and database sessions.
Aggregating Data
Use the built-in aggregation functions to quickly perform common data aggregation and leverage the returned values in scripts or add them to additional target fields. Gather metrics such as Count, Average, Min, Max, and Sum for an entire data set or groups of sorted data using a GroupStarted or GroupEnded event condition depending on your requirements.
Another use case for a Temporary Target is saving the aggregated data until the end of the transformation and using it to output a summary record.
Transformation and Process Objects
Most users will find the wizards and script editor prompts suffice for tasks such as building lookup objects and user-defined functions. However, the scripting language provides system object types for deep, low-level control of the integration. Power users can essentially control all aspects of the transformation, process, error, and system objects through the scripting language.
Web Service APIs
The speed and frequency at which new APIs are available in today's market makes the prior generation of "connectors" impractical when integrating data to any of these end-points. The DataConnect Studio API invoker provides a standardized and consistent approach to use the web service APIs. Any RESTful or SOAP based API can be exercised and leveraged as part of an integration workflow.
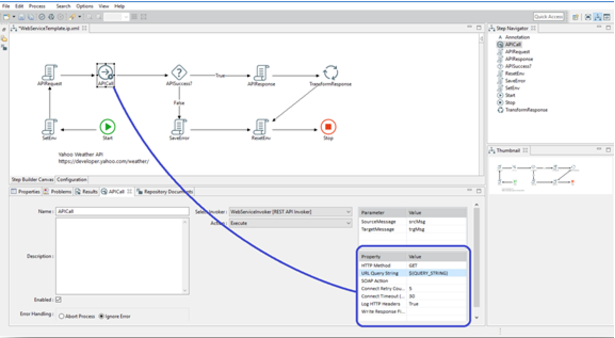
An example of using a REST interface with the invoker includes extracting data from a financial website such as Intrinio to update your Salesforce CRM data. In this case, you can design a process that uses the invoker to extract raw JSON data and pass that data to a map step that uses the JSON connector on the source and the Salesforce connector on the target.
The Salesforce connector is built to read and write data to existing Salesforce objects and is very powerful. However, the Studio API invoker can be more useful. For example, you can use the Studio API invoker to invoke any of the Salesforce API calls such as findDuplicates() or merge(). You can also extract metadata from Salesforce and use that metadata to replicate the structure in a relational database such as Microsoft SQL Server.
Custom Java objects
When functionality outside the scope of the integration language is required, you can call custom Java objects for specialized processing. For example, calling Java code to generate a global unique identifier that is specific to your environment or calling a Natural Language Processor such as OpenNLP to parse unstructured text.
While this example is relatively simple, instantiating and using the JVM and Java object is straightforward:
'Declare objects
public objJVM As JavaVM
public obJava As JavaObject
'Instantiate
objJVM = New javavm()
objJava = objJVM.new Numbers()
'Set variables
int1 = 201
int2 = 403
'Call method
objJava.addNumbers(cint(int1),cint(int2)))
Note: Actian cannot provide direct support for using these third-party objects. However, the scripting language provides the ability to make these external calls. For details, see Java Objects in Scripts.
There may be some performance overhead for which the engine may not have any control, but you can modify the default Java Argument settings and provide additional class path information in the runtime configuration artifact for maps and processes. Additionally, you can make these modifications in the cosmos.ini file to optimize the solution. Make sure to modify the cosmos.ini file for the Studio IDE and the Runtime Engine as required.
A few examples of the arguments that you can change include:
• Permgen
• Heap (-XmX and -XmS)
• Debugging args
Last modified date: 08/02/2023