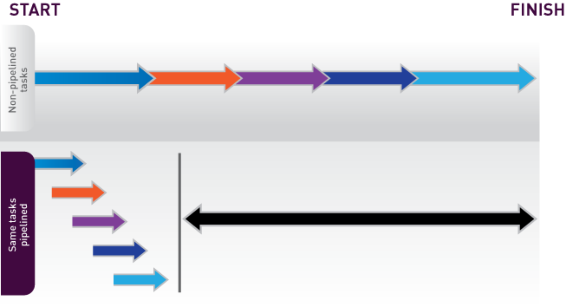
Pipeline Parallelism
Pipeline parallelism extends on simple task parallelism, breaking the task into a sequence of processing stages. Each stage takes the result from the previous stage as input, with results being passed downstream immediately. A good analogy is an automobile assembly line. Each station performs a self-contained action, for instance welding the frame or installing the windshield, but depends on some other task having been done first. Each station simultaneously works on a (different) partly assembled car, and when all stations are finished, the cars are sent to the next station. After the final station, a completely assembled car has been produced. Similarly, in a pipeline, each piece of data moves from stage to stage, eventually producing a final result.
Pipelining is a common technique found in CPUs to increase throughput processing. It is also prevalent in code involving disk (or network) accesses; this often interleaves well with CPU-intensive processing, since they compete for different resources.
Pipeline parallelism shares the features and drawbacks of task parallelism—namely, it is limited by the slowest sub-task and has restricted scalability. However, it is able to parallelize sub-tasks that are dependent, allowing it to be used in more cases. Ideally, each stage consumes and produces one value which permits maximum overlap; however, this is not strictly required. A stage could consume multiple values before emitting output, although this would impact the overall benefit of pipelining.