Configuring DataFlow Client for Hadoop
DataFlow provides integration with several Hadoop versions. The integration supports:
• Configuring access to the Hadoop Distributed File System (HDFS). After configuring the access, you can browse HDFS for file access similar to any other file system.
• Creating execution profiles that enable running DataFlow jobs on a Hadoop cluster.
Configuring the Hadoop Version
Ensure that you have configured the appropriate version of Hadoop to match the cluster.
To configure the Hadoop version in KNIME
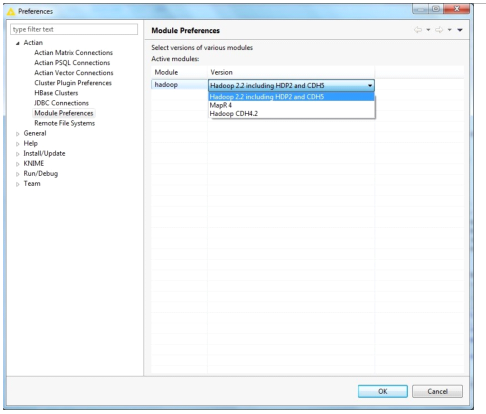
1. Go to File > Preferences > Actian > Module Preferences.
2. Select the appropriate version and click OK to save the preferences.
The following screen shot provides the Hadoop version that is set to Apache Hadoop 2.2 (default).
Configuring HDFS Access
When building workflows, it is convenient to browse HDFS directly. This capability is supported in the DataFlow nodes such as Delimited Text Reader (see
To add Actian Delimited Text Reader operator HDFS file reference) that support file operations.
To enable this capability, you must first configure the connectivity to an HDFS instance.
To create connectivity to an HDFS instance in KNIME
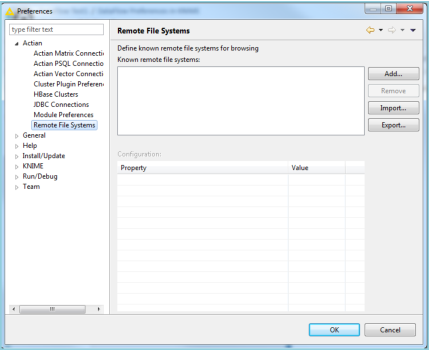
1. Go to File > Preferences.
2. In the Preferences dialog, use the tree view on the left pane to view Actian preferences and select Remote File Systems.
The following is a screen shot of the Remote File Systems dialog.
3. To add a new HDFS file system instance, click Add.
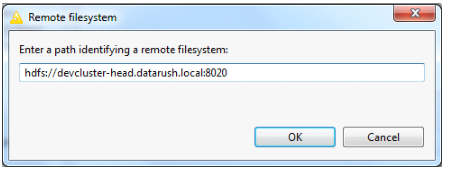
4. Enter the URL to the HDFS instance and click OK. The URL is in hdfs:<server name>:<port number> format. The following screen shot provides an example of a valid HDFS URL:
Note: The default port for the HDFS name server is 8020. To verify and use the correct server name and port number, contact your Hadoop administrator.
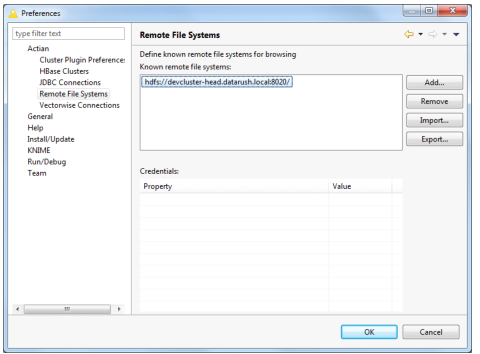
The HDFS instance URL is captured and displayed in the Preferences dialog.
You can add multiple HDFS instance URLs as required to support multiple Hadoop clusters. However, only one version of Hadoop is supported for each installation of DataFlow in KNIME.
Configuring Kerberos for Hadoop
When using a Hadoop cluster with Kerberos security enabled, typically no additional setup is required. If the Kerberos system can authenticate the KNIME user, then no additional setup is needed.
In a few cases, if the version of Java used by the Hadoop cluster does not match with the version of Java used internally by KNIME, then an exception such as “GSS initiate failed [Caused by GSSException: No valid credentials provided (Mechanism level: Failed to find any Kerberos tgt)]” is thrown while executing jobs on the cluster. When this exception occurs, multiple fixes can be implemented, depending on the client system. The fixes are:
• If the client machine with KNIME has the same version of Java installed as the Hadoop cluster, you can add the following line to the knime.ini file in the KNIME installation’s base directory:
-vm
<JAVA_Home>/bin/java
where JAVA_HOME is the location of the Java installation.
Note: You must add these lines directly before the -vmargs and on two separate lines with no leading or trailing spaces. The location should be defined as the local Java installation that matches the version used by the Hadoop cluster.
• If the client machine with KNIME does not have a local version of Java installed, then copy the following folder from the Hadoop cluster’s Java installation directory ($<JAVA_HOME>/jre/lib/security) and replace the appropriate folder in the KNIME install ($<KNIME_HOME>/jre/lib/security).
• If neither of the above methods can be used, then the only option is to export the DataFlow project from KNIME and run it
Using dr command. If the Java version used by the client matches the version used by the Hadoop cluster, then the job should authenticate successfully.
Configuring Kerberos for Hadoop on Windows
There are various ways to set up Kerberos client on windows.
To set up the Kerberos client
1. At the command prompt, enter the following command:
where klist
If C:\Wind ows\System32\klist.exe is displayed as the first value in the result, then set the PATH variable available in System Properties > Environment Variables > System Variables to %JAVA_HOME%/bin in the beginning.
2. Copy the krb5.conf file to the appropriate location:
• If you are using JVM installed on Windows, copy the krb5.conf file to <JAVA_HOME>/jre/lib/security folder.
• If you are using JRE available in KNIME, then copy the krb5.conf file to <KNIME_HOME>/jre/lib/security folder.
Ensure that the hadoop.conf.dir environment variable is set and references the Hadoop configuration directory (typically /etc/hadoop/conf). The hadoop.conf.dir environment variable is used by the DataFlow Cluster Manager to ensure that the proper configuration is accessed and provided to DataFlow clients. Alternatively, edit the knime.ini file and include ‑Dhadoop.conf.dir=<path to configuration directory>.
3. To authenticate Kerberos credentials, at the command prompt enter the command:
kinit –f <principalName>
Enter the password when prompted. For example:
Kinit –f actian@DATAFLOW.ACTIAN.COM
Note: To confirm that the ticket is stored in the cache, at the command prompt, enter the command klist.
4. From the same session, start KNIME or run RushScript to use the cached ticket that was authenticated.