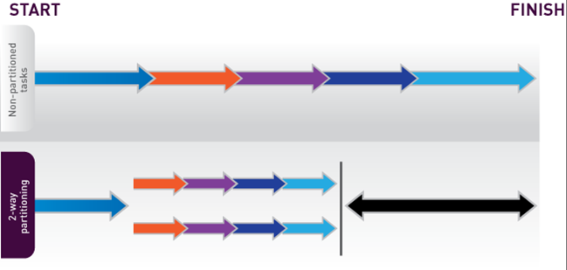
Data Parallelism
Data parallelism, also called horizontal partitioning, breaks input data into smaller sets. The same task is then performed on each set in parallel. Since each operation is over a smaller dataset, each takes less time. Combined with the tasks executing concurrently, overall execution time is decreased as well.
Data parallelism generally scales well, as the parallelism stems from the data. As such it can be very effective but requires that there be data independence between the sets so that they can be processed independently of each other. While this is the case for some problems, this is not generally true of all problems. Also, if the cost of the task is not roughly the same for any piece of data, it is possible that some sets will take longer than others, so the gain is limited by the slowest set.