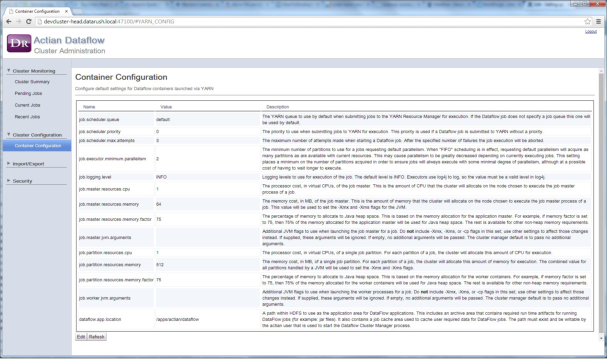
Option | Description |
job.scheduler.queue | The default YARN job queue to use for jobs submitted to YARN. Default: "default" |
job.scheduler.priority | The default job priority. Default: 0 |
job.scheduler.max.attempts | The maximum number of attempts allowed to start a container. If the maximum number of attempts are exceeded, the job fails. Default: 3 |
job.executor.minimum.parallelism | The minimum amount of parallelism (number of parallel partitions) that are allowed to run a job. When a job is first executed, it attempts to allocate a worker container for each wanted partition or unit of parallelism. This is defined by the job parallelism setting. The minimum parallelism is the amount of parallelism that a job is willing to accept. If the target number of containers cannot be obtained in a timely manner, the job will be allocated the minimum (or maybe more) and executed. If a job requires a specific number of partitions,, then the parallelism and minimum parallelism values should match. Default: 2 |
job.logging.level | The level used for logging a job by the application master and the worker containers. Select the required level of logging. Default: "INFO" |
job.master.resources.cpu | The number of CPU cores to allocate to the Application Master container for a job. Default: 1 Note: Configuring this setting is mandatory. |
job.master.resources.memory | The amount of memory (in megabytes) to allocate to the application master. Note: Configuring this setting is mandatory. |
job.master.resources.memory.factor | The percentage of memory allotted to the application master container to allocate as Java heap space. The remaining memory is used as non-heap space. The ‑Xmx option passed to the JVM is calculated by entering this percentage to the job.master.resources.memory setting. |
job.master.yarn.ports | The ports that are available when you set up an application master for a new job. If the port is not set or set to 0, then a random port is selected when a new job is launched that is used as the RPC port for the application master. You must provide port ranges or a comma-separated list of the individual ports. |
job.master.jvm.arguments | Additional JVM arguments to provide to the JVM running the application master. Do not specify memory settings in this option. |
job.partition.resources.cpu | The number of CPU cores to allocate to each worker container for a job. Default: 1 Note: Configuring this setting is mandatory. |
job.partition.resources.memory | The amount of memory (in megabytes) allotted to each worker container for a job. Note: Configuring this setting is mandatory. |
job.partition.resources.memory.factor | The percentage of memory allotted to the application master container to allocate as Java heap space. The rest of the memory is used as non-heap space. The -Xmx option passed to the JVM is calculated by entering this percentage to the job.master.resources.memory setting. |
job.worker.jvm.arguments | Additional JVM arguments provided to each JVM running worker containers. Do not specify memory settings in this option. |
dataflow.app.location | The path to the HDFS-based directory for DataFlow application usage. For more information about the application location, see the installation requirements section above. |