Controlling the Job Master Location
When a job runs in the DataFlow cluster, one of the processes serves as the job master. The job master controls the job execution. It is also the process where nonparallel operations are performed. Finally, the job master serves as the single point of contact from the client. The client does not communicate directly with the rest of the workers and is routed through the client.
By default, all node managers can be either master or worker. When a job is submitted, we randomly select a node to use as the master. In general, this is the preferred configuration.
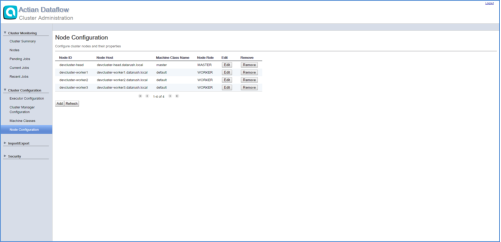
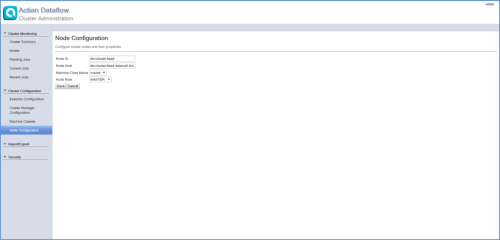
However, there may be connectivity restrictions that may require dedicated master nodes as the client only needs to communicate with the masters. You can define the master nodes and worker nodes in the Node Configuration page, as shown in the following example: