Parallelization of I/O
In DataFlow, the operators that perform I/O operations are parallelized. The data files are divided into logical sections. Each logical section can be read in parallel to allow processing multiple streams of data in parallel. Only a few file types can be split logically. For example, a few compression formats should be read sequentially from the beginning of the file until the end. These file types are treated as a single split to avoid reading in parallel.
The file read operators also support reading of multiple files as a single logical unit. All the files must be in the same format for reading as a single logical unit. For example, a directory with many log files can be read as a single logical log file. All the files in the directory are split and read in parallel. The file readers also support using wildcard characters in file paths which helps to select the files to read.
The reading of files in parallel is performed in two phases. The first phase determines the files to read and splits all the data to read. The splits are distributed to all the streams of execution defined by the physical plan of the application.
In the second phase, the splits are received by the readers, the split data is read, and the data is parsed as required. The data is then sent downstream to the operators that process them.
When the application is run in a Hadoop cluster and the data is sourced from HDFS, the first phase will also optimize the allocation of splits to nodes in the cluster. This optimizes the location by setting the data processing close to the data source.
The following provides a four-way parallel physical plan with a parallelized reader.
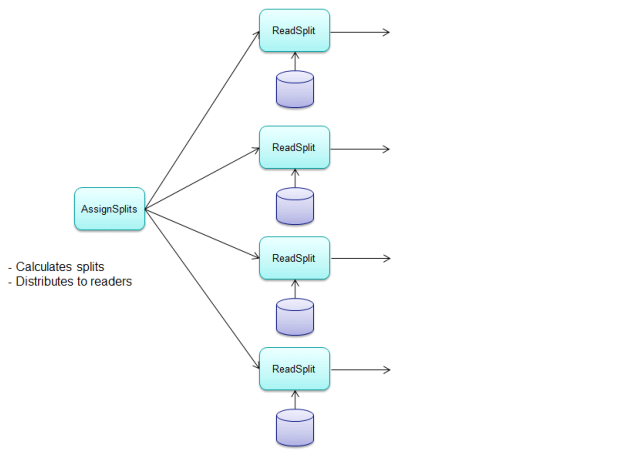
Example
The following code sample uses the ReadDelimitedText DataFlow operator. The reader can read and parse CSV-style files into valid data for downstream operators. This reader supports parallel reading of data files.
Application using a file reader operator
import static com.pervasive.datarush.types.TokenTypeConstant
.INT;
import static com.pervasive.datarush.types.TokenTypeConstant
.STRING;
import static com.pervasive.datarush.types.TokenTypeConstant
.record; import
com.pervasive.datarush.graphs.LogicalGraph; import com.pervasive.datarush.graphs.LogicalGraphFact ory;
import com.pervasive.datarush.io.WriteMode; import com.pervasive.datarush.operators.io.textfile.R eadDelimitedText;
import com.pervasive.datarush.operators.io.textfile.W riteDelimitedText;
import com.pervasive.datarush.schema.TextRecord; import com.pervasive.datarush.types.RecordTokenType;
/**
* Read the ratings.txt file and simply write it back out again.
*/
public class ReadAndWrite {
public static void main(String[] args) {
// Create an empty logical graph LogicalGraph graph =
LogicalGraphFactory.newLogicalGraph("ReadAndWr ite");
// Create a delimited text reader for the "ratings.txt" file
ReadDelimitedText reader = graph.add(new ReadDelimitedText("data/ratings.txt"));
reader.setFieldSeparator("::"); reader.setHeader(true); RecordTokenType ratingsType =
record(INT("userID"), INT("movieID"),
INT("rating"), STRING("timestamp"));
reader.setSchema(TextRecord.convert(ratingsTyp e));
// Create a delimited text writer WriteDelimitedText writer =
graph.add(new
WriteDelimitedText("results/test-ratings.txt", WriteMode.OVERWRITE));
writer.setFieldDelimiter(""); writer.setHeader(true); writer.setWriteSingleSink(true);
// Connect the output of the reader to the input of the writer
graph.connect(reader.getOutput(), writer.getInput());
// Compile and run the graph
graph.run();
}
}
Running this application provides the following output.
com.pervasive.datarush.graphs.internal.Logical GraphInstanceImpl execute
INFO: Executing phase 0 graph: {[AssignSplits, ParseSplits, WriteSink]} com.pervasive.datarush.operators.io.LocalityOp timizer next
INFO: Assigned 1 total splits across 8 nodes, with 1 non-local com.pervasive.datarush.graphs.internal.Logical GraphInstanceImpl execute
INFO: Phase 0 graph: {[AssignSplits, ParseSplits, WriteSink]} completed in 722 milliseconds
The output logs provide a note that the application resulted in one physical phase. During this phase, three operators, AssignSplits, ParseSplits and WriteSink, are executed. The AssignSplits operator determines the splits of the input data files and sends the splits to the downstream ParseSplits operator. The ParseSplits operator reads the data in each split, parses the records and fields, and sends the data to downstream. The final operator in this application writes the data back to the file(s).
The physical plan will create an eight-way parallel DataFlow graph. This is shown by the log stating the number of splits assigned as a cross eight nodes. Even though the graph is run on a single machine, the parallel streams of execution are handled similar to the graph run by distributing across many machines. The location optimizations are applied where it is possible.
Last modified date: 01/03/2025