|
•
|
|
•
|
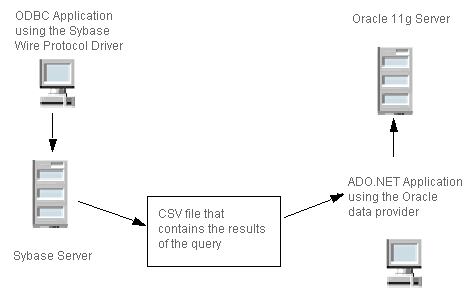
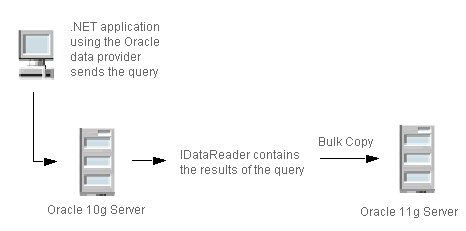
After exporting data from an Oracle database, you migrate the results to a PSQL database. Figure 4 shows an ODBC environment copying data to an ADO.NET database server.
|
|
•
|