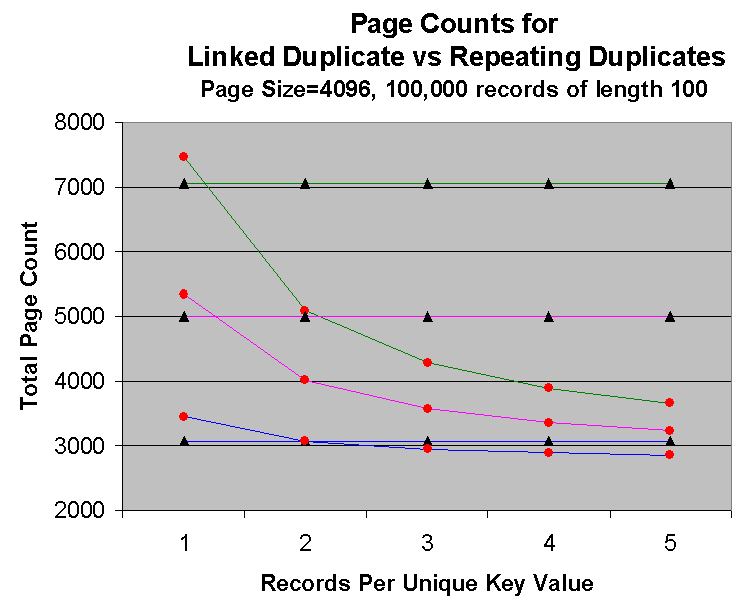
|
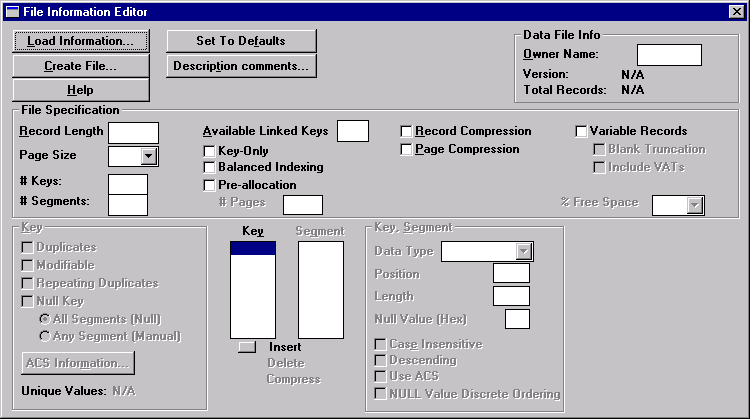
Displays help for the File Information Editor dialog box.
|
|
Table 70
|
|
Table 71
|
|
Table 72
|
|
•
|
|
•
|
|
1
|
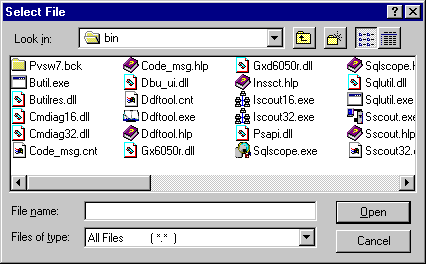
Click Load Information at the top of the File Information Editor. The Select File dialog box appears.
|
|
2
|
|
1
|
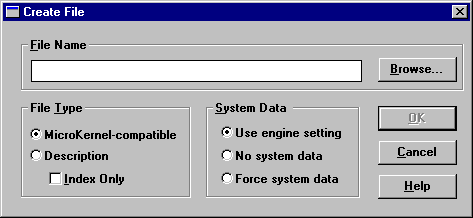
Click Create File at the top of the File Information Editor dialog box. The Create File dialog box appears.
|
|
2
|
|
Table 73
|
|
1
|
|
3
|
Click OK when you are finished entering comments.
|
|
1
|
Click Load Information in the File Information Editor and select the file you want to compact.
|
|
2
|
Click Create File, give the file a new name (which creates a clone) in the Create File dialog box, and click OK.
|
|
3
|
From the Data menu on the main window, select Save. In the Save Data dialog box, enter the name of the original file in the From MicroKernel File box and then specify a name for the output file (for example, <original file>.out) in the To Sequential File box.
|
|
4
|
|
5
|
|
6
|
|
1
|
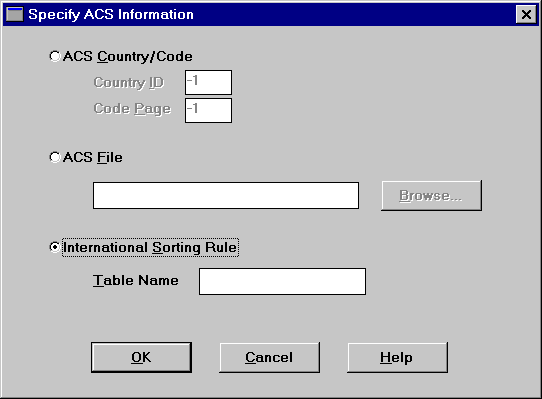
Click ACS Information.
|
|
Table 74
|