Vector in Hadoop Concepts
Vector in Hadoop Overview
Vector in Hadoop (hereafter VectorH) is a high performance, ACID-compliant analytical SQL database management system that leverages the Hadoop Distributed File System (HDFS) or MapR-FS for storage and Hadoop YARN for resource management.
VectorH uses an ANSI standard-compliant SQL engine that performs native SQL processing of data and can be used for efficient large-scale data warehousing, data mining, and reporting. It has an advanced query optimizer, supports efficient updates, and is certified for use with the most popular BI tools.
VectorH performs efficient analytics for large quantities of data by using its vectorization engine and advanced data distribution/replication in HDFS to distribute data optimally. It also includes advanced security features and workload management.
Apache Hadoop Overview
Apache Hadoop is a framework for distributed storage and processing of very large data sets on a cluster of commodity machines. Hadoop splits files into large blocks and distributes them across nodes in a cluster. Various application libraries exist on Hadoop that allow users to write distributed applications that can take advantage of this data distribution to perform large scale data processing for different kinds of use cases.
HDFS and Data Locality
Hadoop's storage component is the Hadoop Distributed File System. The MapR Hadoop distribution uses MapR-FS instead of HDFS.
Note: This guide uses “HDFS” as a generic term for either file system, unless otherwise stated.
To process data, Hadoop works on local data as much as possible, a concept known as data locality. Nodes in the cluster process the data they have access to.
YARN
Hadoop has a component called YARN (Yet Another Resource Negotiator), which manages the resources in a cluster and schedules applications. Think of it as the "operating system" for Hadoop.
Spark
Spark is a parallel data processing framework for Hadoop that allows data in a multitude of formats to be processed across the cluster in a resilient manner.
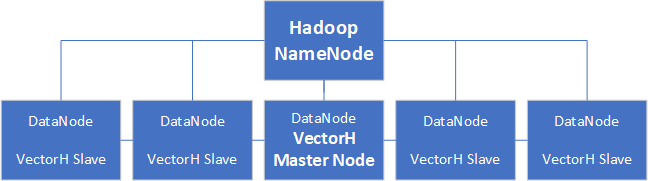
NameNodes and DataNodes
A Hadoop cluster consists of a NameNode and DataNodes.
• The NameNode keeps the directory of all files in the file system and tracks where across the cluster the file data is stored.
• DataNodes store the data files.
VectorH and Apache Hadoop Integration
VectorH integrates with multiple Hadoop services.
• HDFS – VectorH distributes its data by leveraging the native file system APIs
• YARN – VectorH integrates with YARN for resource and workload management
• Spark – VectorH integrates with Spark to import existing cluster data or to processes it directly as an external table
The VectorH engine runs natively within a Hadoop cluster and can use all or a subset of the nodes in a Hadoop cluster. The VectorH installation process is driven from a single DataNode, which becomes the VectorH master node. The master node is a full installation and acts as the primary node for the VectorH instance. The master node drives the setup for the VectorH slave nodes.
Best Practice — The NameNode must be on a machine separate from any of the DataNodes, according to best practices for Hadoop. Combining these roles on a single server can result in unpredictable behavior for VectorH and the cluster.
VectorH can be installed on a minimum of three DataNodes. We recommend, however, using at least five DataNodes (one of which is the VectorH master node).
YARN can be used to control and share resources within a Hadoop cluster so that processes can share the available resources without conflicting. These resources can be decreased or increased as demand requires, for example, for month-end ETL processing. VectorH is compliant with YARN.
Installed Components
A VectorH instance requires a fully configured Hadoop installation with at least YARN and HDFS enabled. It consists of the following installed components:
• VectorH full installation on single Hadoop DataNode. We refer to the node with the full VectorH installation as the master node.
Note: The NameNode and DataNode must be separate because the NameNode is typically the busiest node in the cluster, and the VectorH master node is the busiest node in the VectorH instance.
• Vector Server, libraries, Java classes on the slave nodes
• Intel MPI Runtime library on all nodes for inter-node communication