Profiling Rules
Profiling rules can help you identify problems in source data. These rules are of the following types:
• Some rules can be used to generate aggregate statistics, which help identify inaccuracies by examining aggregated values over large datasets.
• Other rules are test rules that generate pass and fail statistics. Some of these rules also provide a method to invert the results into pass and fail files.
The following is a list of profiling rules:
Rule Name | Description |
|---|---|
Returns true or false after comparing a field to a constant value.. | |
Returns true or false after comparing a field value to another field value. | |
Writes all the distinct (unique) values found in a source dataset into a file. | |
Writes all the duplicate values found in a source dataset into a file. | |
Calculates equal width ranges across the field values and counts the number of values in each range. | |
Returns true if two strings match based on the configured fuzzy matching rules and match score filter. | |
Returns true if a field is not blank, returns false otherwise. | |
Returns true if a field is not null, returns false otherwise. | |
Checks if the value is within specified range. | |
Returns true if a field matches a regular expression, returns false otherwise. | |
Calculates the most frequent values of a field. | |
Calculates the following statistics for a numeric field. Min, Max, Mean, Median, Mode, Standard Deviation, Sum, Variance. |
Compare to Constant
Description | Returns true or false after comparing a field to a constant value. |
Parameters | • Invert Test - Select this to report the opposite results in your pass or fail file. For more information, see Invert Rule Test. • Operator - Select from one of the following comparison operators: – Equal – Greater – Greater or Equal – Lesser – Lesser or Equal – Not Equal • Constant - In this text box, type the constant value to compare, and then press the Enter key or click Add. For equal or not equal you can specify one or more constants. |
Supported Data Types | String, Date, Timestamp, Boolean, Numeric, Double, Float, Long, Integer |
Remarks | The constant must be of the same data type as the profiled field. The equal operator is not recommended to use on double or float field comparisons. Do not use quotation marks with string data. The following formats are supported for date and timestamp: • yyyy-mm-dd • yyyy-mm-dd hh:mm:ss (military time) Note: If source has GMT timestamp data, the constant value should end with 'Z'. |
Compare to Field
Description | Returns true or false after comparing a field value to another field value. |
Parameters | • Invert Test - Select this to report the opposite results in your pass or fail file. For more information, see Invert Rule Test. • Operator - Select from one of the following comparison operators: – Equal – Greater – Greater or Equal – Lesser – Lesser or Equal – Not Equal • Compare Field - Select the required field to compare from. |
Supported Data Types | String, Date, Timestamp, Boolean, Numeric, Double, Float, Long, Integer |
Remarks | The two fields must be of the same data type. The equal operator is not recommended for use on double or float field comparisons. |
Distinct Values
Description | Writes all the distinct (unique) values found in a source dataset into a file. |
Parameters | • Results File - Displays the distinct values output file. Default is within your project. However, you can change it. • Sort by - Select the required Sort Order from the following: – Field Data (Faster) – Frequency Count (Slower) Note: Frequency Count (Slower) sorts the results in descending order and hence the sorting is slower compared to Field Data sort option. |
Supported Data Types | String, Date, Timestamp, Boolean, Numeric, Double, Float, Long, Integer |
Remarks | The results file name must not contain the following characters: • / • \ • . • , • .. |
Duplicate Values
Description | Writes all the duplicate values found in a source dataset into a file. |
Parameters | • Results File - Displays the duplicate values output file. Default is within your project. However, you can change it. • Sort by - Select the Sort Order from the following: – Field Data (Faster) – Frequency Count (Slower). Note: Frequency Count (Slower) sorts the results in descending order and hence the sorting is slower compared to Field Data sort option. • Min Count - Type the required value (default is 2). The value must not be lower than 2. |
Supported Data Types | String, Date, Timestamp, Boolean, Numeric, Double, Float, Long, Integer |
Remarks | The results file name must not contain the following characters: • / • \ • . • , • .. |
Equal Range Binning
Description | Calculates equal width ranges across the field values and counts the number of values in each range. The following is an example of the Equal Range Binning histogram output. 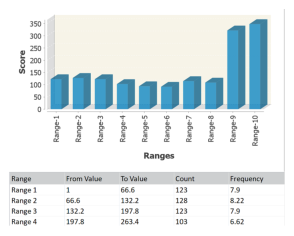 |
Parameters | • RangeCount - Specify the number of ranges to create. The default is 10. |
Supported Data Types | All numeric types supported as input (Numeric, Double, Float, Long, Integer) |
Remarks | This rule constructs a histogram and defines an equal range for each bin. The rule algorithm works as follows: • Finds the lowest and highest values in the field to profile to determine the end points • Creates Range Count equal-width ranges between highest and lowest values • Counts the non-null values in each range The generated histogram has a Range Count and one bar for nulls. Exceptions: If min and max values are identical, then bar is generated. If data type is integer or long and the minimum and maximum are close together, then it generates the number of bars that fits in the graph. Example: If minimum is 1 and maximum is 4, then rangeCount > = 4 results in one bar for each possible nonnull whole value. The behaviour for interpolated breaks between ranges depends upon the input data type: • int and long: interpolated breaks are whole numbers. • float and double: interpolated breaks are double precision floating point values and can be values such as 1.6799999999999999995 due to floating-point roundoff error. • numeric: interpolated breaks are rounded for presentation. The scale used when rounding is the scale of the minimum or maximum value (whichever is larger), plus a number of digits equal to the number of digits in the rangeCount.. |
Fuzzy Match
Description | Returns true if two strings match based on the configured fuzzy matching rules and match score filter. |
Parameters | • Invert Test - Select this to report the opposite results in your pass or fail file. For more information, see Invert Rule Test. • Fuzzy Match Algorithm - – CONTAINS – DAMERAU_LEVENSHTEIN – EXACT_MATCH – JARO – JARO_WINKLER – LEVENSHTEIN – QGRAM – POSITIONAL_QGRAM – SHORTHAND • Constant - In this text box, type the constant value with which to compare, and then press the Enter key or click Add. You can compare with multiple values. • Fuzzy Score Filter - Add a decimal values between 0.01 to 1. Default value is 0.7. Comparison score is between 0 to 1. Records with comparison score less than this value are not considered a match for probable duplicates and are discarded. The higher the value you select, more strict is the matching. |
Supported Data Types | String |
Remarks | Supported Fuzzy Matching algorithms: • CONTAINS: Checks the small string in the long string. • DAMERAU–LEVENSHTEIN: This distance between two strings is the minimum number of operations (insertions, deletions or substitutions of a single character, or transposition of two adjacent characters) required to change one string into another. For more information, see Damerau–Levenshtein distance. • EXACT MATCH: Checks two strings for exact match. • JARO: A measure of characters in common, being no more than half the length of the longer string in distance with consideration for transpositions. • JARO-WINKLER: This algorithm extends Jaro algorithm and uses a prefix scale “p” which gives more favorable ratings to strings that match from the beginning for a set prefix length “l”. The prefix length is set to 4 characters (the maximum possible prefix length). For more information, see Jaro–Winkler distance. • LEVENSHTEIN: This distance between two strings is the minimum number of single-character edits (insertions, deletions or substitutions) required to change one string into other. For more information, see Levenshtein distance. • POSITIONAL QGRAM: Positional q-grams is an extension to q-grams with an additional property called maxDistance used in calculating the string similarity. For example, ‘peter’ contains the positional bigrams (‘pe’,0), (‘et’,1), (‘te’,2) and (‘er’,3). If maxDistance is set to 1, then (‘et’,1) will only be matched to bi-grams in the other string with positions 0 to 2 • QGRAM: q-grams (also called as n-grams) is the process of breaking up a string into multiple strings each with length n (q). For example, apply q-grams on abcde with q = 3 would yield abc, bcd, cde. For example, the word ‘peter’ with q=2 would yield following bigrams - ‘pe’, ‘et’, ‘te’ and ‘er’. A q-gram similarity measure between two strings is calculated by counting the number of q-grams in common. • SHORTHAND: Determine if the shorter string is a “shorthand” of the longer. That is, if it can be produced only by deletions. If the first character of a word in the longer string is deleted, the entire word is considered deleted. For e.g. IBM is a shorthand of International Business Machines. |
Is Not Blank
Description | Returns true if a field is not blank, returns false otherwise. |
Parameters | • Invert Test - Select this to report the opposite results in your pass or fail file. For more information, see Invert Rule Test. |
Supported Data Types | String |
Remarks | Counts null, white space, and empty strings as blank. |
Is Not Null
Description | Returns true if a field is not null, returns false otherwise. |
Parameters | • Invert Test - Select this to report the opposite results in your pass or fail file. For more information, see Invert Rule Test. |
Supported Data Types | String, Date, Timestamp, Boolean, Numeric, Double, Float, Long, Integer |
Remarks | None |
In Range
Description | Checks if the value is within specified range. |
Parameters | • Lower Bound - The lower range value. Select Inclusive to include the lower bound number in the range. • Upper Bound - The upper range value. Select Inclusive to include the upper bound number in the range. |
Supported Data Types | Date, Timestamp, Numeric, Double, Float, Long, Integer |
Remarks | The following formats are supported for Date and Timestamp: • yyyy-mm-dd • yyyy-mm-dd hh:mm:ss (military time). Note: If source has GMT timestamp data, the lower bound and upper bound values should end with 'Z'. |
Matches Regex
Description | Returns true if a field matches a regular expression, returns false otherwise. |
Invert Test | Select this to report the opposite results in your pass or fail file. For more information, see Invert Rule Test. |
Parameters | Regular Expression - Specify one or more regular expressions by typing or selecting them from the drop-down list and then clicking Add. Click You can also: • Paste a macro by right-clicking in the text box and selecting the macro from the Paste Macro dialog. See Pasting Macro in Map or Process. • Create a macro by right-clicking in the text box. See Creating a Macro by Selecting a Value. The drop-down list includes the following options: • AlphaNumeric Strings -->^[a-zA-Z0-9]+$ • AnyString-->.* • ASCII characters only-->^([a-zA-Z0-9!\"#$%&',/:;<=>@_`|~ \\(\\)\\*\\+\\-\\.\\?\\[\\]\\\\\\^\\{\\}])*$") • Canada Postal Code-->^([A-Za-z]\d[A-Za-z][\s-]?\d[A-Zaz]\d) • Credit Card Number-->[1-9][0-9]{3} [0-9]{4} [0-9]{4} [0-9]{4} • Date - mm/dd/yyyy format-->^(3[0-1]|2[0-9]|1[0-9]|0[1-9])[\s{1}|\/|-](Jan|JAN|Feb|FEB|Mar|MAR|Apr|APR|May|MAY|Jun|JUN|Jul|JUL|Aug|AUG|Sep|SEP|Oct|OCT|Nov|NOV|Dec|DEC)[\s{1}|\/|-]\d{4}$ • Date - YYMMDD format-->^((\d{2}((0[13578]|1[02])(0[1-9]|[12]\d|3[01])|(0[13456789]|1[012])(0[1-9] |[12]\d|30)|02(0[1-9]|1\d|2[0-8])))|([02468][048]|[13579][26])0229)$ • Days of Week-->^(Sun|Mon|(T(ues|hurs))|Fri)(day|\.)?$|Wed(\.|nesday)?$|Sat(\.|urday)?$|T ((ue?)|(hu?r?))\.?$ • Digits Only-->\d+ • Email Address-->^(([A-Za-z0-9]+_+)|([A-Za-z0-9]+\\-+)|([A-Za-z0-9]+\\.+)|([A-Za-z0-9]+\\++))*[A-Za-z0-9]+@((\\w+\\-+)|(\\w+\\.))*\\w{1,63}\\.[a-zAZ]{2,6}$ • ISBN_10 Number-->ISBN\x20(?=.{13}$)\d{1,5}([-])\d{1,7}\1\d{1,6}\1(\d|X)$ • Mr or Mrs-->Mr|Mrs • Printable Characters-->^([a-zA-Z0-9!@#$%^&amp;*()-_=+;:'&quot;|~`&lt;&gt;?/{}] {1,5})$ • Single Alphabetic character-->^[a-zA-Z]$ • Social Security Number-->^[0-9]{3}-?[0-9]{2}-?[0-9]{4}$ • Time - hh:mm AMPM format-->^ *(1[0-2]|[1-9]):[0-5][0-9]*(a|p|A|P)(m|M) *$ • Time - hh:mm:ss format-->(([0-1][0-9])|([2][0-3])):([0-5][0-9]):([0-5][0-9]) • UK Postal Code-->^([A-Z]{1,2}[0-9]{1,2}|[A-Z]{3}|[A-Z]{1,2}[0-9][A-Z])( |-)[0-9][A-Z]{2} • US Currency-->^\$?( )*\d*(.\d{1,2})?$ • US Phone Number-->^[01]?[- .]?\(?[2-9]\d{2}\)?[- .]?\d{3}[- .]?\d{4}$ • US Zipcode or Zip+4-->[0-9]{5}(-[0-9]{4})? • Vehicle Identification Number (VIN)-->^(([a-h,A-H,j-n,J-N,p-z,P-Z,0-9]{9})([a-h,A-H,j-n,J-N,p,P,r-t,R-T,v-z,V-Z,0-9])([a -h,A-H,j-n,J-N,p-z,P-Z,0-9])(\d{6}))$ AnyString is the default regular expression. For a description of Regular Expression options, see Remarks (below). |
Supported Data Types | String |
Remarks | Regex pattern rule is displayed in the Parameters column on the Rules tab and the Description column is displayed on the Result summary. Actian DataConnect stores and uses regular expressions and you can edit the expressions if required. Description of Regular Expressions: • AlphaNumeric - Matches strings that contain character and/or numeric data. • AnyString - Matches all strings. • ASCII characters only Postal- Matches ASCII characters only postal. • Canada Postal Code - Matches postal code for Canada. • Credit Card Number - Matches a credit card number. • Date - mm/dd/yyyy format - Flexible date validator that matches most date formats. • Date_YYMMDD - Date expression validator with format YYMMDD. • Days of Week - Matches days of the week or their abbreviations. • DigitsOnly - Expression for matching one or more digits. • EmailAddress - Matches an email address. • ISBN_10 Number - Matches format of an ISBN number. • Mr or Mrs - Matches Mr or Mrs characters. • Printable Characters - Matches all printable characters. • Single Alphabetic character - Matches a single alphabetic Character. • Social Security Number - Matches U.S. social security number. Dashes (-) are optional. • Time - hh:mm AMPM format - Matches time format hh/mm AM. • Time - hh:mm:ss format - Matches time format hh:mm:ss. • US Zipcode or Zip+4 - Matches a US zip code. • Vehicle Identification Number (VIN) - Matches US Vehicle Identification Numbers (VINs). |
Most Frequent Values
Description | Calculates the most frequent values of a field. |
Parameters | • Top How Many - Specify the number of desired frequent values. The default is 25, which returns the top 25 most frequent values. |
Supported Data Types | String, Date, Timestamp, Boolean, Numeric, Double, Float, Long, Integer |
Remarks | This rule replaces some of the functionality of the Distinct Values rule. |
Statistics
Description | Calculates the following statistics for a numeric field. Min, Max, Mean, Median, Mode, Standard Deviation, Sum, Variance. |
Parameters | None |
Supported Data Types | Date, Timestamp, Boolean, Numeric, Double, Float, Long, Integer. |
Remarks | None |
Last modified date: 01/08/2026