Data Prep Rules
Data preparation is the process of converting raw data into a clean, consistent, and structured format that is suitable for analysis. This process involves several key steps, including data cleaning to remove errors and inconsistencies, as well as data transformation. These rules create new in-memory fields (see Derived Fields), which can then be used for further processing or to build additional rules. It also involves data engineering tasks such as adding new columns to enrich the dataset, deleting unnecessary columns to improve efficiency, and renaming columns for improved clarity and consistency.
They generate pass and fail statistics based on conversion success or failure, and they create derived fields of the converted type.
See Add New Rule for information about adding rules.
The following is a list of data preparation rules:
Rule Name | Description |
|---|---|
Converts a non-string field into a specified data type. It creates a new in-memory field. | |
Executes the specified expression on the field. This is useful for complex transformations. | |
Looks up a value from a dataset, based on the specified keys. | |
Applies a mathematical transformation to a numeric field. It creates a new in-memory field. | |
Extracts one or more parts from fields such as names, addresses, and timestamps. | |
Joins multiple fields into a single string field which can be used to create a new column. | |
Separates a string field into substrings which can be used to create new columns. | |
Converts a string field into a specified data type. It creates a new in-memory field. |
DataTypeConversion
This rule changes a data type into a new, specified data type.
A derived field is stored in-memory (RAM). The derived fields are available in-memory and can be used for further profiling and analysis. Users can also include the derived field values with profile output fields. For more information, see Derived Fields.
This rule serves several purposes:
• Consistency for Analysis: It ensures that data is in a uniform format, making it possible to accurately group information together—for instance, changing detailed time-and-date stamps so you can consistently group all records by just the day.
• Readability: It converts technical data types into plain, easily readable strings so that user-facing reports are clear for non-technical audiences.
• System Stability and Scalability: It prevents technical errors, such as those caused by numbers getting too large for the system to handle (integer overflow), which supports the system's ability to grow.
• Data Integrity: It helps maintain the quality and accuracy of your information.
Note that when changing data types, some information may be lost:
• Loss of Precision: If you convert a high-detail number (like one with many decimal places, such as a "Numeric" or "Double" type) into a simpler whole number ("Int" or "Long"), the decimal part of the number will be removed or rounded off.
• Loss of Date/Time Detail: If you take a combined date and time (a "TimeStamp") and convert it to just a Date or just a Time, the part you discard (the time of day or the date itself) is permanently erased from the data, which may affect later analysis.
• Handling Unconvertible Values: If a field contains a value that cannot be logically converted to the new type (for example, trying to turn the text "N/A" into a number), the rule will typically fail to process that specific value. The system will not crash; instead, the resulting field value for that record will be set to NULL (a missing value indicator).
This rule does not convert a string data type. To convert a string data type, use the StringToConversion rule.
Rule Properties
This rule has the following properties.
Rule Name | A default rule name (<FieldName>DataTypeConversion) is provided and displayed here. However, you can edit or overwrite it. Click Reset to restore the default rule name. Note: The underscore (_) character is the only special character allowed in the name. Rule names cannot begin with a digit. If a field or column in the source data starts with a digit, 'r_' will be prepended to any rules created based on that field. |
Field Name | The field name to which the rule applies is displayed here, along with the data type in parentheses. For example, Date (Date). |
Rule Type | The type of rule that is applied to the field. That is DataTypeConversion (Function rule). Tip... A Red Cross in a rule icon (for example |
Rule Parameters
This rule has the following parameters.
Source Type | The source field data type. |
Convert to: | Select the data type to convert the source data into for the in-memory derived field. Note: The dropdown menu only presents options which the Source Type can be logically converted to. For example, if the Source Type is Numeric, then you can convert to Boolean, Double, Float, Integer, Long or String. If the Source Type is Date or Time, then you can only convert to String. Options for all source data types are: • String (Text) • Int (32-bit integer) • Long (64-bit integer) • Double (Double-precision floating point) • Float (Single-precision floating point) • Numeric (High-precision decimal: 38 digits, 18 decimal places) • Boolean (True/false) • Date (Calendar date) • Time (Time of day) • TimeStamp (Date and time combined) |
Format | Optionally, select a format to apply to the converted data. Format options depend on the source data type. Note: When converting from Double, Float, Integer, Long and Numeric data types there are no formats to specify. |
The Boolean data type can be converted to a String or Integer data type. The String data type has the following formats available: • True.False • Yes.No • 1.0 • T.F | |
The Date data type can be converted to a String data type and the following formats are available: • yyyy-M-dd • yyyy-MM-dd • MM/dd/yy • M/dd/yyyy • MM/dd/yyyy • M-dd-yyyy • MM-dd-yyyy • MMM-yy • MMM dd, yyyy | |
The Time data type can be converted to a String data type and the following formats are available: • HH:mm:ss • HH:mm • hh:mm:ss • hh:mm aa | |
The TimeStamp data type can be converted to a String, Date or Time data type and the following formats are available: String Formats: • yyyy-MM-dd HH:mm:ss • MM/dd/yyyy HH:mm • MMM dd, yyyy HH:mm aa • EEE, dd MMM yyyy HH:mm:ss Z Date Formats: • yyyy-M-dd • yyyy-MM-dd • MM/dd/yy • M/dd/yyyy • MM/dd/yyyy • M-dd-yyyy • MM-dd-yyyy • MMM-yy • MMM dd, yyyy Time Formats: • HH:mm:ss • HH:mm • hh:mm:ss • hh:mm aa Tip... If you are converting string-based temporal data (like dates and times) into a true Date, Time, or TimeStamp, the Format parameter is required. If the input string does not adhere to a default, recognized ISO standard (for example, yyyy-MM-dd), the conversion will fail without specifying the exact pattern in the Format parameter. | |
Timezone | Optionally, select a Timezone identifier (for example, "UTC", "America/New_York", "Europe/London"). This parameter is typically used for timestamp conversions that require timezone adjustments. This parameter is visible when the Source Type is a Time or TimeStamp data type. Tip... When converting timestamps, if the Timezone parameter is omitted, the system will use a default time zone, typically UTC or the server's local time zone. If you intend to localize or accurately compare timestamps across different geographic regions, you must explicitly specify the Timezone. Otherwise, calculations based on the perceived local time will be incorrect. |
Derived Field Name | A default derived field name (d_<SourceDataType>Derived_DataTypeConversion, where <SourceDataType> is the data type of the source) is provided and displayed here. However, you can edit or overwrite it. See Derived Fields. |
Supported Data Types
Int, Long, Double, Float, Numeric, Boolean, DateTime, TimeStamp (input)
String, Int, Long, Double, Float, Numeric, Boolean, DateTime, TimeStamp (output)
Remarks
Does not provide pass and fail statistics.
Example: Timestamp to Date Conversion (Data Aggregation)
Use Case: This conversion retains the date and removes the time from a timestamp. Typically used for daily sales aggregation, transactions are grouped by calendar day for generating daily reports, performing trend analysis, and populating business intelligence dashboards without needing time-of-day granularity.
To change the input value 2025-01-15 14:30:45 (TimeStamp) to the output value 2025-01-15 (Date), parameters can be set as follows:
Field Type - Date
Example: Numeric Type Conversion (Data Migration)
Use Case: This conversion is used to convert integer IDs to a longer data type, such as Long, to support larger datasets. This prevents integer overflow during system scalability, supports growing databases, and ensures data integrity when platform migrations or expansions occur.
To change the input value 2147483647 (Int - the max 32-bit value) to the output value 2147483647 (Long), parameters can be set as follows:
Field Type - Long.
Example: Boolean to String Conversion (User Interface)
Use Case: This conversion changes Boolean flags text for inclusion in customer-facing reports. This improves report readability for non-technical users, enhances customer communication, and maintains consistent terminology across various business documentation.
To change the input value true (Boolean) to the output value "yes" (String), parameters can be set as follows:
• Field Type - String
• Format - "yes.no"
ExecuteExpression
This rule executes the specified expression. This is useful for complex transformations.
A derived field is stored in-memory (RAM). The derived fields are available in-memory and can be used for further profiling and analysis. Users can also include the derived field values with profile output fields. For more information, see Derived Fields.
Once the Execute Expression rule has been added to a profile, it will be categorized under -MultiFieldRules- on the Rules tab, instead of under the -OutputFields-.
Rule Properties
Rule Name | A default rule name (ExecuteExpression or ExecuteExpression_n, where “n” is 1,2,3, and so on) is provided and displayed here. However, you can edit or overwrite it. Click Reset to restore the default rule name. Note: The underscore (_) character is the only special character allowed in the name. Rule names cannot begin with a digit. If a field or column in the source data starts with a digit, 'r_' will be prepended to any rules created based on that field. |
Field Name | -MultipleFields- is displayed here. |
Rule Type | The type of rule that is applied to the field. That is ExecuteExpression (Function rule). Tip... A Red Cross in a rule icon (for example |
Rule Parameters
Script | The Script text box helps you construct expressions for Derived Fields. Click Build to open the Expression Builder dialog to assist you in building the SQL script. For example, to add multiple regular expressions use the RLIKE operator: CASE WHEN field RLIKE 'pattern1' THEN true WHEN field RLIKE 'pattern2' THEN true WHEN field RLIKE 'pattern3' THEN true ELSE false END |
Derived Field Name | A default derived field name (d_ExecuteExpression, d_ExecuteExpression_n, where “n” is 1,2,3, and so on) is provided and displayed here. However, you can edit or overwrite it. See Derived Fields. |
Supported Data Types
String, Date, Time, Timestamp, Boolean, Numeric, Double, Float, Long, Integer
Using the Expression Builder
The Expression Builder dialog helps you construct expressions for Derived Fields. This dialog provides the fields, operators, and functions you can use to build SQL scripts in Apache Spark.
To open the Expression Builder dialog, click Build. In the displayed dialog, select the required field and double-click.
The following is an Expression Builder dialog:
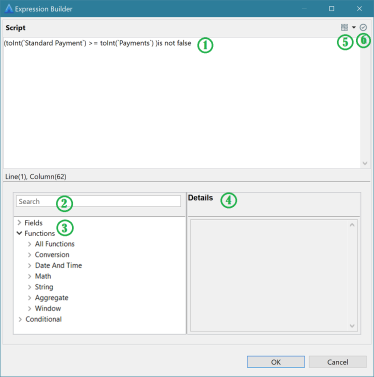
The following elements are available in the dialog:
Screen Element | Description |
|---|---|
(1) Script editor | The script editor displays the expression that is built. You can insert the elements from the element tree or type in the editor. |
(2) Search | Enter a keyword in the Search box to find and display matching fields or functions in the Search Results pane. Click on the required function and the description for the function is displayed in the Details pane. To insert the selected function into the expression, double-click the function. Tip... When you are typing a search keyword, a |
(3) Element tree | The left pane provides the Field references, Functions, and Conditional constructs that can be used to build an expression. Click on the required element and the description is displayed in the Details pane. To insert an element, double-click the element or select the element and click OK. The following elements are listed in the form of a tree structure: • Field references: Provides a list of input fields that can be referenced in the expression. • Functions: Provides a list of functions available to the expression language, and it is organized by category. To see the description of a function, select it. After a function is inserted into the expression, you must replace its argument names with appropriate values. See Conversion Functions, Date And Time Functions, Math Functions, String Functions, Aggregate Functions, Window Functions. • Conditional constructs: Conditional constructs are programming structures that allow you to control the flow of a program by making decisions based on conditions. See Conditional Constructs. |
(4) Details pane | Displays the details of the selected function. |
(5) Operators | Click to view a list of operators supported by expression language. The operators are organized by category. See Operators. |
(6) Validation button | Click to check the validity of the expression and report any existing errors. |
Operators
There are several types of operators in that you can use in your expressions or scripts, including:
• Arithmetic: Used to perform basic mathematical operations.
• Comparison or Relational: Used to compare two values or expressions. They return a boolean result (True or False) based on whether the comparison is true or false.
• Logical: Used to combine or modify boolean values (True or False), assignment, and more.
The following table lists the available operators:
Operator | Description |
|---|---|
( | Open bracket. Open and closed brackets are used to group expressions. They are not specific operators but are frequently used in conjunction with conditional operators or mathematical expressions. Example: a + (b * c) |
) | Close bracket. Open and closed brackets are used to group expressions. They are not specific operators but are frequently used in conjunction with conditional operators or mathematical expressions. Example: ((a > b) and (c < d)) |
* | Arithmetic operator for multiplication. Multiplies two values together. |
+ | Arithmetic operator for addition. Adds two values together. |
- | Arithmetic operator for subtraction. Subtracts one value from another. |
/ | Arithmetic operator for division. Divides one value by another. |
% | Relational “remainder” operator. Returns the remainder of a division operation. |
!= | Relational “not equal to” operator. Checks if two values or expressions are not equal. |
|| | String concatenation operator. |
< | Relational “less than” operator. Checks if the value on the left is less than the value on the right. |
<= | Relational “less than or equal to” operator. Checks if the value on the left is less than or equal to the value on the right. |
<> | Relational “not equal to” operator. Checks if two values or expressions are not equal (an alternative to !=). |
= | Relational “equal to” operator. Checks if two values or expressions are equal. |
> | Relational “greater than” operator. Checks if the value on the left is greater than the value on the right. |
>= | Relational “greater than or equal to” operator. Checks if the value on the left is greater than or equal to the value on the right. |
AND | Logical “and” operator. Returns True if both operands (conditions) are True. Otherwise, it returns False. |
BETWEEN | Tests if a value is within a given range, inclusive. |
CASE | Begins conditional expression. |
CAST | Type conversion function. |
ELSE | Default result when no conditions match. |
END | Ends CASE expression. |
EXISTS | Tests for the existence of a set of values. |
ILIKE | Case-insensitive matching. |
IN | Tests if a value is equal to any value in a list. |
IS NOT NULL | Test “is not null”. Checks if a field value or result of expression is any value other than null. |
IS NULL | Tests “is null”. Checks if a field value or result of expression is null. |
LIKE | Logical “like” operator. Compares two string expressions. If the expressions match, result is True. If there is no match, result is False. |
NOT | Negates a boolean expression. |
NOT IN | Tests if a value is not equal to any value in a list. |
OR | Logical “or” operator. Returns True if at least one of the operands (conditions) is True. Returns False if both operands are False. |
RLIKE | Tests if a string matches a regular expression. |
THEN | Result when condition is true. |
WHEN | Condition in CASE expression. |
Conversion Functions
The conversions category provides a set of functions for converting the data type of input fields into a different data type in Apache Spark.
Function | Description | Parameters |
|---|---|---|
bigint | Format: bigint(field) Converts a field with a numeric type into a bigint (long) type. This function rule is useful, for example, for handling unique identifiers (IDs) and aggregate counts that exceed 2.1 billion. | field: Name of the field to be converted. |
boolean | Format: boolean(field) Converts an integer field into a boolean type based on specific integer values representing true and false. If the integer value of the field matches the truth value, it will return true. If it matches the falsity value, it will return false. Any other value (unmapped values) will result in null. This function is useful, for example, for converting status codes (for example, '1' for true, '0' for false) or text (for example, 'YES', 'NO') into a true/false value for conditional logic. | field: Name of the field to be converted. |
cast | Format: cast(field AS dataType) Converts a field to the specified data type. This function is useful, for example, for standardizing data types before profiling. For example, if a dataset contains a column representing employee ages that was accidentally imported as a STRING, you would use the cast function to convert it to an INT or BIGINT. This conversion is necessary to perform mathematical operations (like calculating the average age or identifying ranges) that are essential for accurate data profiling and analysis. | • field: Name of the field to be converted. • dataType: The target type, which can be one of: STRING, INT, BIGINT, DOUBLE, FLOAT, BOOLEAN, DATE, TIMESTAMP, DECIMAL, or BINARY. |
cast_as_bigint | Format: cast(field AS BIGINT) Converts a string or numeric field to bigint (long). This function is useful, for example, when you need to explicitly change a field's type to a large whole number. | field: Name of the field to be converted. |
cast_as_boolean | Format: cast(field AS BOOLEAN) Converts a string or numeric field to boolean. This function is useful, for example, when you need to explicitly change a field's type to a true/false value. | field: Name of the field to be converted. |
cast_as_decimal | Format: cast(field AS DECIMAL(precision, scale)) Converts a field to decimal. This function is useful, for example, when handling currency or financial data where you need exact precision (for example, 10 digits total with 2 after the decimal) to avoid rounding errors. | field: Name of the field to be converted. |
cast_as_double | Format: cast(field AS DOUBLE) Converts a string or numeric field to double. This function is useful, for example, when you need a numeric value with high-precision floating-point arithmetic for scientific or complex non-financial calculations. | field: Name of the field to be converted. |
cast_as_float | Format: cast(field AS FLOAT) Converts a string or numeric field to float. This function is useful, for example, when converting a field to a single-precision floating-point number, typically for simpler decimal values where space efficiency is important. | field: Name of the field to be converted. |
cast_as_int | Format: cast(field AS INT) Converts a string or numeric field to int. This function is useful, for example, when converting text-based or decimal numbers into standard whole numbers (integers) for counting or grouping, discarding any fractional part. | field: Name of the field to be converted. |
cast_as_string | Format: cast(field AS STRING) Converts a field to string. This function is useful, for example, when you need to combine a number or date with other text, or output data for human-readable reports or log files. | field: Name of the field to be converted. |
date | Format: date(field) Extracts and outputs the date part from a timestamp field. This function is useful, for example, when you only need the date portion for comparison, grouping, or filtering, and you want to disregard the time. | field: Name of the field to be converted. |
date_format | Format: date_format(field, format) Extracts the time part from a timestamp field and outputs to a specified pattern. This function is useful, for example, when you need to represent a time in a specific custom format (for example, 'YYYY-MM-DD' or 'HH:mm:ss') for display or integration. | • field: Name of the field to be converted. • format: The pattern to apply. |
decimal | Format: decimal(field) Converts a field to decimal. This function is useful, for example, when you need an explicit function call (rather than the `CAST` syntax) to define the exact precision and scale of a financial or critical numeric field. | • field: Name of the field to be converted. |
double | Format: Double(field) Converts a field to double. This function is useful, for example, when converting a raw data field to a high-precision decimal number outside of the standard `CAST` syntax. | field: Name of the field to be converted. |
float | Format: Float(field) Converts a field into a float type. This function is useful, for example, when converting a raw data field to a single-precision floating-point number outside of the standard `CAST` syntax. | field: Name of the field to be converted. |
format_number | Format: Format_number(field, decimalPlaces) Formats a numeric field as string with specified decimal places. This function is useful, for example, when preparing a numeric result (like a dollar amount) for presentation, ensuring a fixed number of decimal points and applying standard formatting (for example, thousand separators). | • field: Name of the field to be converted. • decimalPlaces: Number of decimal places. |
format_string | Format: format_string(format, args...) Returns formatted string using printf-style format strings. This function is useful, for example, when dynamically constructing complex strings by inserting multiple variable values into a template (like generating a structured message or URL). | • field: Name of the field to be converted. • args: Arguments to format. |
from_unixtime | Format: from_unixtime(unixTime, format) Converts Unix timestamp (seconds) to formatted date string. This function is useful, for example, when raw log or event data contains time as a numeric timestamp and you need to convert it into a human-readable date and time string. | • field: Name of the field to be converted. • format: The date and time pattern to apply. |
int | Format: Int(field) Converts a field into an integer type. This conversion can lead to a loss of precision if the number is too large or too small to be represented as an integer. This function is useful, for example, when converting numeric fields (for example, age, count) that are currently strings or decimals into a standard whole number, without needing the massive size of a bigint. | field: Name of the field to be converted. |
to_date | Format: to_date(field, format) Converts a string to date, optionally with format. This function is useful, for example, when a date is stored as a custom-formatted text string (for example, 'DD/MM/YYYY') and needs to be treated as an actual date type for sorting or analysis. | • field: Name of the field to be converted. • format: (Optional) The date pattern to apply. |
to_timestamp | Format: to_timestamp(field, format) Converts a string field to a timestamp field. This function is useful, for example, when you have a string that contains both date and time (for example, '2024-06-15 14:30:00') and need to treat it as a full time-series data point. | • field: Name of the field to be converted. • format: (Optional) The time pattern to apply. |
try_cast | Format: try_cast(field AS dataType) Converts a string field to a specified data type, returns NULL if conversion fails. | • field: Name of the field to be converted. Field should be wrapped in back quotes (for example, `myField`). • dataType: The target data type: STRING, INT, BIGINT, DOUBLE, FLOAT, BOOLEAN, DATE, TIMESTAMP, DECIMAL, BINARY. |
try_to_date | Format: try_to_date(field, format) Converts a string field or timestamp to a date, returns NULL if conversion fail. | • field: Name of the field to be converted. Field should be wrapped in back quotes (for example, `myField`). • format: (Optional) The Date format pattern (for example, 'MM-dd-yyyy' or 'dd-MM-yyyy'). |
try_to_timestamp | Format: try_to_timestamp(field, format) Converts a string field to timestamp, returns NULL if conversion fails. | • field: Name of the field to be converted. Field should be wrapped in back quotes (for example, `myField`). • format: (Optional) The Java SimpleDateFormat pattern (for example, 'MM-dd-yyyy HH:mm:ss') |
unix_timestamp | Format: unix_timestamp(field, format) Converts a string field to Unix timestamp (seconds since epoch). This function is useful, for example, when converting a human-readable date/time string into a simple numeric format for easier calculation or comparison of time intervals. | • field: Name of the field to be converted. • format: The pattern to apply. |
Date And Time Functions
The date and time category provides functions for dealing with date, time, and timestamp values. Unless specifically indicated otherwise, these functions accept values of any of the date and time types. If no time zone is supplied to functions taking an optional time zone argument, the default time zone as indicated by the JVM will be used.
Function | Description | Parameters |
|---|---|---|
add_months | Format: add_months(startDate, numMonths) Adds the specified number of months to a date. | • startDate: The date field. • numMonths: Number of months to add. |
current_date() | Format: current_date() Returns the current date in Spark SQL. | None |
current_timestamp() | Format: current_date() Returns the current timestamp in Spark SQL. | None |
date_add | Format: date_add(startDate, numDays) Adds the specified number of days to a date. | • startDate: The date field. • numDays: Number of days to add. |
date_sub | Format: date_sub(startDate, numDays) Subtracts the specified number of days from a date. | • startDate: The date field. • numDays: Number of days to subtract. |
datediff | Format: datediff(endDate, startDate) Returns the number of days between two dates. | • endDate: The end date field. • startDate: The start date field. |
day | Format: day(field) Extracts the day of the month from a date/timestamp field. | field: The date or timestamp field. |
dayofweek | Format: dayofweek(field) Extracts the day of the week (where 1=Sunday and 7=Saturday). | field: The date or timestamp field. |
from_utc_timestamp | Format: from_utc_timestamp(field, timezone) Converts a field in UTC to the specified timezone. | • field: The timestamp field in UTC. • timezone: The target timezone (for example, 'PST', 'America/Los\_Angeles'). |
hour | Format: hour(field) Extracts the hour from a timestamp field. | field: The timestamp field. |
minute | Format: minute(field) Extracts the minute from a timestamp field. | field: The timestamp field. |
month | Format: month(field) Extracts the month from a timestamp field. | field: The date or timestamp field. |
months_between | Format: months_between(endDate, startDate) Returns the number of months between two dates. | • endDate: The end date field. • startDate: The start date field. |
now | Format: now() Returns the current timestamp (this is an alias for current\_timestamp). | None |
second | Format: second(field) Extracts the seconds from a timestamp field. | field: The timestamp field. |
to_utc_timestamp | Format: to_utc_timestamp(field, timezone) Converts the timestamp from the specified timezone to UTC. | • field: The timestamp field. • timezone: The source timezone. |
weekofyear | Format: weekofyear(field) Extracts the week of a year from a date/timestamp field. | field: The date or timestamp field. |
year | Format: year(field) Extracts the year from a date/timestamp field. | field: The date or timestamp field. |
Math Functions
The Math category provides implementations of common math functions. Trigonometric functions use radians by default.
Function | Description | Parameters |
|---|---|---|
abs | Format: abs(field) Returns the absolute value of the given numeric field, which is simply the number without a negative sign. The number can be an int, long, float, or a double. If the argument is NaN, the result is NaN. | field: A numeric field. Alternatively, an expression (such as another function or an expression that evaluates to a number) can also be used. |
ceil | Format: ceil(field) Returns the smallest integer that is not smaller than the value. | field: A numeric field. Alternatively, an expression (such as another function or an expression that evaluates to a number) can also be used. |
cos | Format: cos(field) Returns the cosine of the given field (input must be in radians). | field: A numeric field. Alternatively, an expression (such as another function or an expression that evaluates to a number) can also be used. |
e | Format: e(field) Returns Euler's number e (approximately 2.718281828459045). | field: A numeric field. |
exp | Format: exp(field) Returns the mathematical constant e raised to the power of the given field. If the argument is NaN, the result is NaN. | field: A numeric field. Alternatively, an expression (such as another function or an expression that evaluates to a number) can also be used. |
floor | Format: floor(field) Returns the largest integer that is not greater than the value. | field: A numeric field. Alternatively, an expression (such as another function or an expression that evaluates to a number) can also be used. |
ln | Format: ln(field) Returns the natural logarithm of the given field. | field: A numeric field. Alternatively, an expression (such as another function or an expression that evaluates to a number) can also be used. |
log | Format: log(field) Returns the logarithm of the field using the specified base. For example, if you have a field called num in a record, and it contains “7.389”, log(`num`) will evaluate to log(7.389) returning 2, because e raised to the power of 2 is about 7.389. If the argument is NaN or less than zero, the result is NaN. | field: A numeric field. |
log2 | Format: log2(field) Returns the base 2 logarithm of the given field. | field: A numeric field. |
log10 | Format: log10(field) Returns the base 10 logarithm of the given field. This determines the power to which 10 must be raised to equal the field number. If the argument is NaN or less than zero, the result is NaN. | field: A numeric field. |
pi | Format: pi(field) Returns the mathematical constant PI (approximately 3.14159). | field: A numeric field. |
pow | Format: pow(base, exponent) Returns the base value raised to the power of the exponent. | • base: Base value. • exponent: Exponent value. |
rand | Format: rand(seed) Returns a random floating-point value between 0 and 1. The value is generated using a pseudorandom number generator (based on an algorithm). | seed: (Optional) Random seed. |
round | Format: round(field, scale) Returns the field value rounded to the specified number of decimal places. If the argument is NaN, the result is 0. Returns a Long if the argument is a Double and an Integer if the argument is a Float. | • field: A numeric field. Alternatively, an expression (such as another function or an expression that evaluates to a number) can also be used. • scale: (Optional) Number of decimal places. The default is 0. |
sin(field) | Format: sin(field) Returns the sine of the given field (input must be in radians). Sine is a mathematical function that takes an angle (in radians) and returns the sine value of that angle. Radians are a way of measuring angles, similar to degrees, but using a different scale. For example, if you have an angle of 30 degrees, to use this the sin function you first convert 30 degrees into radians, and then find the sine value. If the field is a number representing an angle in radians, like 1.0 (which is approximately 57.3 degrees). The sin function would return the sine of 1.0, which is approximately 0.841. | field: A numeric field. Alternatively, an expression (such as another function or an expression that evaluates to a number) can also be used. |
sqrt | Format: sqrt(field) Returns the square root of the given field. | field: A numeric field. Alternatively, an expression (such as another function or an expression that evaluates to a number) can also be used. |
tan | Format: tan(field) Returns the tangent of the given field (input must be in radians). | field: A numeric field. Alternatively, an expression (such as another function or an expression that evaluates to a number) can also be used. |
String Functions
The String category provides common String manipulation functions.
Function | Description | Parameters |
|---|---|---|
concat | Format: concat(field1, field2, ...) Joins the string values of two or more input fields together. | • field: The first string field or constant. • field2: The second string field or constant. • Additional fields: Include as many string fields or constants as needed. |
concat_ws | Format: concat_ws(separator, field1, field2, ...) Joins multiple strings together, separated by a specified delimiter. | • separator: The string to use as a delimiter between fields. • field1: The first string field. • Additional fields: Include as many string fields as needed. |
initcap | Format: initcap(field) Capitalizes the first letter of every word in the string field. | field: The string field to capitalize. |
instr | Format: instr(field, substring) Returns the 1-based index of the first time a specific substring appears within a string field. | • field: The string to search within. • substring: The specific substring to locate. |
length | Format: length(field) Returns the number of characters in the string value. | • field: The string field to measure. |
locate | Format: locate(substring, field, position) Returns the 1-based index of a substring within a string, optionally starting the search from a specific position. | • substring: The specific substring to locate. • field: The string to search within. • position: (Optional) The starting position for the search. The default is 1. |
lower | Format: lower(field) Converts all alphabetical characters in the string to lowercase. | field: The string field to convert. |
lpad | Format: lpad(field, length, pad) Adds characters to the left side of a string until it reaches a specified total length. | • field: The string field to pad. • length: The final target length of the string. • pad: The string used for padding (for example, '0' or ' '). |
ltrim | Format: ltrim(field) Removes leading whitespace characters from the beginning (left side) of the string. | field: The string field to trim. |
regexp_extract | Format: regexp_extract(field, pattern, groupIdx) Extracts the part of the string that matches a specified capture group from a regular expression pattern. | • field: The string field to search within. • pattern: The Java regular expression to use for matching. • groupIdx: The index of the capture group to extract (0 returns the entire match). |
regexp_replace | Format: regexp_replace(field, pattern, replacement) Replaces all occurrences of substrings that match a regular expression pattern with a specified replacement string. | • field: The string field to modify. • pattern: The Java regular expression to search for. • replacement: The string to substitute for all matches. |
replace | Format: replace(field, search, replace) Replaces all non-regex occurrences of a specific search string within a field with a new replacement string. | • field: The string field to modify. • search: The exact string to find and replace. • replace: The string to substitute for all occurrences of the search string. |
rpad | Format: rpad(field, length, pad) Adds characters to the right side of a string until it reaches a specified total length. | • field: The string field to pad. • length: The final target length of the string. • pad: The string used for padding (for example, '0' or ' ') |
rtrim | Format: rtrim(field) Removes trailing whitespace characters from the end (right side) of the string. | field: The string field to trim. |
split | Format: split(field, pattern, limit) Divides a string into an array of strings based on a delimiter pattern. | • field: The string field to be split. • pattern: The regular expression delimiter. • limit: (Optional) The maximum number of resulting array elements. |
substring | Format: substring(field, startPos, length) Returns a segment of the input string, starting at a specific position and continuing for a defined length. | • field: The input string field. • startPos: The 1-based position where the extraction should begin. • length: The number of characters to extract. |
trim | Format: trim(field) Removes leading and trailing whitespace characters from both ends of the string. | field: The string field to trim. |
upper | Format: upper(field) Converts all alphabetical characters in the string to uppercase | field: The string field to convert. |
Aggregate Functions
The Aggregate category has functions that perform calculations.
Function | Description | Parameters |
|---|---|---|
avg | Format: avg(field) This function calculates and returns the average of the values in the specified field. Must be used with OVER () clause as a window function. | field: The numeric field to calculate the average of. |
count | Format: count(field) This function counts and returns the total number of rows in the specified field or group. Must be used with OVER () clause as a window function. | field: The numeric field to count. |
sum | Format: sum(field) This function calculates and returns the sum of values in the specified field. Must be used with OVER () clause as a window function. | field: The numeric field to calculate the sum of. |
Window Functions
The Window category has the following functions.
Function | Description | Parameters |
|---|---|---|
lag | Format: lag(field, offset) OVER (PARTITION BY ... ORDER BY ...). This function returns the value x number of rows before the current row (where x is the offset). | • field: The field to either return the value of, or to base the offset on (if an offset is specified). • offset: (Optional) Number of rows back. The default is 1. |
rank | Format: rank() OVER (PARTITION BY ... ORDER BY ...) Used with the OVER clause, this function assigns a rank to each row within a partition (with gaps for ties). | None |
row_number | Format: row_number() OVER (PARTITION BY ... ORDER BY ...) Used with the OVER clause, this function assigns a unique sequential integer to each row within a partition. | None |
Conditional Constructs
The Conditional category has constructs that help you pick values based on certain conditions.
Construct | Description | Parameters |
|---|---|---|
case when then else end | Format: case (baseExpression) when (condition) then (value) when (condition2) then (value2) else (defaultValue) end Builds a conditional expression that evaluates to one of many possible values, functioning similarly to a switch or case statement. If the condition is not met, the specified defaultValue is returned. | • baseExpression: (Optional) A field or expression to evaluate. • condition: If a baseExpression is used, the condition checks if the expression equals a certain value. If no baseExpression is used, you can name the field and use any assignment (for example, Hr < 12). • defaultValue: A field or expression to return as default if no case is met. |
case when then end | Format: case (baseExpression) when (condition) then (returnValue) when (condition2) then (returnValue2) end Builds a conditional expression that evaluates to one of many possible values, functioning similarly to a switch or case statement. If the condition is not met, a null value is returned. | • baseExpression: (Optional) A field or expression to evaluate. • condition: If a baseExpression is used, the condition checks if the expression equals a certain value. If no baseExpression is used, you can name the field and use any assignment (for example, Hr < 12). |
coalesce | Format: coalesce(field1, field2, ...) Returns the first non-null value from a list of fields/values. | • field1: The first field or value to check. • field2: The alternative field or value. • Additional fields as needed. |
if | Format: if(condition, trueValue, falseValue) Returns the trueValue if the condition is true, otherwise it returns the falseValue. | • condition: The boolean expression to be tested. • trueValue: The value to be returned when condition is true. • falseValue: The value to be returned when condition is false. |
nvl | Format: nvl(field, replacementValue) Returns the replacement value if the field is null. | • field: The field or expression. • replacementValue: The replacement value (which must be the same data type as the field). |
Remarks
• See DateTime Format
• See Class DecimalFormat
LookupValue
This rule allows you to perform a lookup (search and retrieve values from another dataset). The values retrieved from the lookup are placed into a new, auto-generated derived field. The returned lookup values can then be used where Data Profiler accepts a derived field (in expressions and other rules, and to write values to a target). For step-by-step instructions, see Adding a lookup source, Creating a LookupValue rule and Writing retrieved lookup values to the target.
A derived field is stored in-memory (RAM). The derived fields are available in-memory and can be used for further profiling and analysis. Users can also include the derived field values with profile output fields. For more information, see Derived Fields.
Once the LookupValue rule is added to a profile, it is categorized under -MultiFieldRules- in the Field/Rule pane (instead of under -OutputFields-).
This rule uses an incore lookup which is stored in memory (RAM). The lookup dataset contains two columns that are of interest for configuring this rule: one column contains the values that reside in the source or derived field (referred to as the lookup key field); the other column stores the desired values (referred to as the return lookup field). When the rule executes, the engine compares the source or derived field value (referred to as the matching key value) with the lookup key field value. When these values match, the return lookup field value is added to the new derived field.
Lookups can also be created in the Source tab (see Creating Lookups in Profile Editor Source Tab).
This topic includes the following:
• Example
Rule Properties
This rule has the following properties.
Rule Name | A default rule name (LookupValue or LookupValue_n, where “n” is 1,2,3, and so on) is provided and displayed here. However, you can edit or overwrite it. Click Reset to restore the default rule name. Note: The underscore (_) character is the only special character allowed in the name. Rule names cannot begin with a digit. If a field or column in the source data starts with a digit, 'r_' will be prepended to any rules created based on that field. |
Field Name | -MultipleFields- is displayed here. |
Rule Type | The type of rule that is applied to the field. That is LookupValue (Function rule). Tip... A Red Cross in a rule icon (for example |
Rule Parameters
This rule has the following parameters.
Lookup Name | Click Add Tip... In the Lookup Configuration Wizard, connect to the lookup as with a source connector. For example, select the ASCII (Delimited) connector and set the Header property to True. When prompted to select the Lookup Key Field, select the lookup column for comparing against the source or derived field. |
Lookup Key Field | The lookup field selected in the Lookup Configuration Wizard. This field contains the lookup values to compare against the Matching Key Field values. When the Lookup Key Field and the Matching Key Field values match, the Return Lookup Field (from the lookup) value is added to the derived field. If no match is found, a null or blank value is returned. |
Matching Key Field | Select the field in the source (or derived field) to match against the Lookup Key Field values. When the Lookup Key Field and the Matching Key Field values match, the Return Lookup Field value is added to the derived field. |
Return Lookup Field | Select the field in the lookup that contains the values to retrieve from the lookup dataset. These values are stored in-memory within the derived field. |
Derived Field Name | A default derived field name (d_<FieldName>LookupValue or d_<FieldName>LookupValue_n, where “n” is 1,2,3, and so on) is provided and displayed here. However, you can edit or overwrite it. See Derived Fields. |
Adding a lookup source
1. In the Rules tab, select any field, then click  >Add New Rule.
>Add New Rule.
The Add Rules dialog opens.
The Add Rules dialog opens.
2. In the Data Prep tab, select LookupValue, and Finish.
The Rule Definition pane opens. The Rule Name field displays the rule name which can be edited.
The Rule Definition pane opens. The Rule Name field displays the rule name which can be edited.
3. In the Rule Definition pane, click  (to the right of the Lookup Name drop-down list) to open the Configuration Wizard, then do the following:
(to the right of the Lookup Name drop-down list) to open the Configuration Wizard, then do the following:
• Enter a name for the lookup and a description (optionally). This name will appear in the Lookup drop-down list.
• Configure the lookup data connection parts and properties click Connect and Next.
• Verify that you are connected to the correct lookup data, note the name of the column to be used for the Lookup Key Field, then click Next.
• In the Field Name column, select the Lookup Key Field (which will be used by the LookupValue rule for matching against the source/derived Matching Key Field), then click Finish.
The lookup is now available in the Lookup Name drop-down list and the Source tab, Source drop-down list.
To configure the LookupValue rule to use the lookup, continue to Creating a LookupValue rule.
Creating a LookupValue rule
1. In the Rules tab, Field/Rule pane, select LookupValue under -MultiFieldRules-.
The Rule Definition pane opens.
2. In the Rule Definition pane define the rule parameters:
• Lookup Name: Select the required lookup.
• Lookup Key Field: The lookup column previously specified for the lookup is displayed.
Tip... To change this value, click the edit button beside the lookup name.
• Matching Key Field: Select the source or derived field to use for matching against the Lookup Key Field.
• Return Lookup Field: Select the lookup field that contains the values to retrieve and store in the new derived field.
• Save all files.
The retrieved lookup values can now be used in other rules or to map to an output field using the new derived field. To create a new output field for the retrieved lookup values, continue to Writing retrieved lookup values to the target.
Writing retrieved lookup values to the target
1. In the Rules tab, Field/Rule pane, create a new output field for the derived values:
• Click  >Add New Field, and enter a descriptive name for the new field.
>Add New Field, and enter a descriptive name for the new field.
• In the Expression column for the new field, select the required derived field from the drop-down list.
The new field is now mapped to the derived field containing the retrieved lookup values.
2. Save the profile, then click  to execute the profile.
to execute the profile.
The Total pass/fail data pie chart is displayed.
The Total pass/fail data pie chart is displayed.
3. Click the pie chart to open the Drill Down data tab.
Scroll to the right to see the new output field populated with the data.
Scroll to the right to see the new output field populated with the data.
Tip... To omit a field from the output, select the field in the Field/Rule pane and click  to delete it. The field is not deleted in the source data.
to delete it. The field is not deleted in the source data.
Editing a lookup source
1. In the Rules tab, click  >Add New Rule.
>Add New Rule.
The Add Rules dialog opens.
The Add Rules dialog opens.
2. In the Data Prep tab, select LookupValue, and Finish.
3. Select the lookup you want to edit from the Lookup Name drop-down list.
4. Click  to edit (on the right of the Lookup Name drop-down list) in the Configuration Wizard.
to edit (on the right of the Lookup Name drop-down list) in the Configuration Wizard.
5. Edit fields and properties as needed, click Connect and Next.
6. Verify that you are connected to the correct lookup data, note the column to be used for the Lookup Key Field (the field that contains the replacement value), then click Next.
7. In the Field Name column, select the field to use as the Lookup Key Field and click Finish.
Note: When users change the lookup name, connection, key field, replacement field, or derived field name, all related elements and metrics using the lookup file reflect the changes (for example, the rule name).
Deleting a lookup source
1. In the Rules tab, click  >Add New Rule.
>Add New Rule.
The Add Rules dialog opens.
The Add Rules dialog opens.
2. In the Data Prep tab, select LookupValue, and Finish.
3. Select the lookup you want to delete from the Lookup Name drop-down list.
4. Click  to delete (on the right of the Lookup Name drop-down list).
to delete (on the right of the Lookup Name drop-down list).
The lookup is removed from the Lookup Name drop-down list and the Source tab Source drop-down list.
The lookup is removed from the Lookup Name drop-down list and the Source tab Source drop-down list.
Example
Let’s say that your source contains a State column containing full state names (such as California and Texas), and you need the values to be state codes (such as CA and TX). You also have a dataset, StateCodes, that contains a StateName column containing full state names, and an Abbreviation column containing the corresponding state code.
For example, the source State column (below, on the left) and the lookup dataset (below, on the right):
Source (or Derived Field) | Lookup: StateCodes |
"State" "Texas" "California" "Ohio" "Ohio" "California" | "State_Name","Abbreviation" "California","CA" "Texas","TX" "Ohio","OH" |
Note: The elements displayed in bold are used as the parameter settings in this example. | |
To use the dataset as the lookup to retrieve state codes you would add StateCodes as a lookup (see Adding a lookup source), and set the LookupValue rule parameters as follows:
• Lookup Name - StateCodes (The name of the lookup file.)
• Lookup Key Field - State_Name (The lookup field to match against the source Matching Key Field.)
• Matching Key Field - State (The source field to match against the Lookup Key Field value. When the Lookup Key Field and the Matching Key Field values match, the Return Lookup Field value is added to the derived field.)
• Return Lookup Field - Abbreviation (The lookup field that contains the values to retrieve from the lookup dataset. These values are stored in-memory within the new derived field.)
• Derived Field Name - d_State_LookupValue (The new, derived field containing the retrieved state code values which can be included in output by mapping an output field Expression property to the derived field.)
For step-by-step instructions, see Adding a lookup source, Creating a LookupValue rule and Writing retrieved lookup values to the target.
Supported Data Types
All data types. However, the Lookup Key Field and Matching Key Field values must be the same data type.
MathTransform
This rule applies various mathematical transformations to numeric fields. It acts as a unified metric, consolidating many common math functions.
A derived field is stored in-memory (RAM). The derived fields are available in-memory and can be used for further profiling and analysis. Users can also include the derived field values with profile output fields. For more information, see Derived Fields.
Rule Properties
This rule has the following properties.
Rule Name | The default rule name (<FieldName>_MathTransform) is provided and displayed here. Click Reset to restore the default rule name. Note: The underscore (_) character is the only special character allowed in the name. Rule names cannot begin with a digit. If a field or column in the source data starts with a digit, 'r_' will be prepended to any rules created based on that field. |
Field Name | The field name to which the rule applies is displayed here, along with the data type in parentheses. For example, Total (Numeric). |
Rule Type | The type of rule that is applied to the field. That is MathTransform (Function rule). Tip... A Red Cross in a rule icon (for example |
Rule Parameters
This rule has the following parameters.
Math Operation | Select the mathematical operation to perform. Options are: • Absolute Value - Returns absolute value. For example: abs(-5) = 5 • Add - Returns a + b. For example: 5 + 3 = 8 • Arc Cosine - Returns arccos(x). For example: acos(1) = 0 • Arc Sine - Returns arcsin(x). For example: asin(0) = 0 • Arc Tangent - Returns arctan(x). For example: atan(0) = 0 • Arc Tangent 2 - Returns atan2(y, x). For example: atan2(1,1) = PI/4 • Cosine - Returns cos(x) radians. For example: cos(0) = 1 • Cube Root - Returns cube root1. For example: cbrt(27) = 3 • Divide - Returns a / b. For example: 10 / 2 = 5 • Exponential - Returns e^x. For example: exp(1) = 2.718... • Hyperbolic Cosine - Returns cosh(x). For example: cosh(0) = 1 • Hyperbolic Sine - Returns sinh(x). For example: sinh(0) = 01 • Hyperbolic Tangent - Returns tanh(x). For example: tanh(0) = 0 • Hypotenuse - Returns sqrt(a^2 + b^2). For example: hypot(3,4) = 5 • Log Base 10 - Returns log10(x). For example: log10(100) = 2 • Log Base 2 - Returns log2(x). For example: log2(8) = 3 • Maximum - Returns max(a, b). For example: max(5, 3) = 5 • Minimum - Returns min(a, b). For example: min(5, 3) = 3 • Modulo - Returns a % b. For example: 10 % 3 = 1 • Multiply - Returns a * b. For example: 5 * 3 = 15 • Natural Log - Returns ln(x). For example: log(e) = 1 • Negate - Returns negation. For example: negate(5) = -5 • Power - Returns a^b. For example: 2^3 = 8 • Sign - Returns sign (-1, 0, 1). For example: signum(-5) = -1 • Sine - Returns sin(x) radians. For example: sin(0) = 0 • Square Root - Returns square root. For example: sqrt(16) = 4 • Subtract - Returns a - b. For example: 5 - 3 = 2 • Tangent - Returns tan(x) radians. For example: tan(0) = 0 • To Degrees - Converts radians to degrees. For example: degrees(PI) = 180 • To Radians - Converts degrees to radians. For example: radians(180) = PI |
Use Field | Specifies the second operand as another field (which must be specified in the Second Operand Field parameter). This parameter is an alternative to the Use Constant parameter, and only available when a binary math operation is selected. |
Use Constant | Specifies the second operand as a constant value (which must be specified in the Constant Value parameter). This parameter is an alternative to the Use Field parameter, and only available when a binary math operation is selected. |
Second Operand Field | This option is only available when the Use Field parameter is selected. |
Constant Value | This option is only available when the Use Constant parameter is selected. |
Decimal Precision | (Optional) Specifies the number of decimal places for rounding the result. By default, the value is -1 (which performs no rounding). A positive integer specifies the number of digits to keep after the decimal point. For example, 2 rounds the result to two decimal places: 3.14159 is rounded to 3.14. |
Derived Field Name | A default derived field name (d_<FieldName>_MathTransform or d_<FieldName>_MathTransform_n, where “n” is 1,2,3, and so on) is provided and displayed here. However, you can edit or overwrite it. The name can be edited. See Derived Fields. |
Supported Data Types
Numeric (input)
Numeric (output)
Remarks
Does not provide pass and fail statistics and generates a derived field. See Derived Fields.
ParseExtract
This rule enables users to parse and extract parts from a structured or composite field value (such as an URI, Email, Full Name, Address, and Timestamp). Users apply the parsing function that is relevant to the data type in the field. For example, the Parse Name, Parse Email or Parse Time function. The parsing functions generate a derived field for each part. For example, the Parse Email function extracts two parts: username@domain. The username part is to the left of the @ symbol and the domain part is to the right of the @ symbol. Two derived fields are generated - one for usernames and another for domains.
A derived field is stored in-memory (RAM). The derived fields are available in-memory and can be used for further profiling and analysis. Users can also include the derived field values with profile output fields. For more information, see Derived Fields.
For a step-by-step example, see Example
Some parsing functions requires additional parameters such as FORMAT or Regex in order to be specified.
Rule Properties
This rule has the following properties.
Rule Name | A default rule name (<FieldName>_ParseExtract) is provided and displayed here. However, you can edit or overwrite it. Click Reset to restore the default rule name. Note: The underscore (_) character is the only special character allowed in the name. Rule names cannot begin with a digit. If a field or column in the source data starts with a digit, 'r_' will be prepended to any rules created based on that field. |
Field Name | The field name to which the rule applies is displayed here, along with the data type in parentheses. For example, Email (String). |
Rule Type | The type of rule that is applied to the field. That is ParseExtract (Function rule). Tip... A Red Cross in a rule icon (for example |
Rule Parameters
This rule has the following parameters.
Function | Select the parsing function that is relevant to the type of data in the field from the Function drop-down list. See Functions for details. |
Format | Select the format desired. Each function has a different set of PartIDs available. See Functions for details. |
Click • Add Part - Select to manually add a single part from the field. A single row is added to the table. You can then select the specific part from the Part drop-down list. • Add Available Parts - Select to add all the available parts from the field. A single row is added to the table for each part. The Part column is auto-populated. Tip... To delete a part from the table, select the part and | |
Part | The unique identifier for the part. This field is populated by the Function selected. For some functions, a dropdown list is provided with some or all of the available parts which you can select from. For example, the Parse Full Name function provides all of the available parts, including [first] and [last] which are parts for the first name and the last name. When a dropdown list of parts is provided, select a part from the list. When a dropdown list of parts for the function is not provided, enter a value for an element that is shown for the Format field selection. For example, the Parse Time Date function provides format options which include MM, dd and yyyy. Thus, you can enter MM for month, dd for day and yyyy for year as parts. Likewise, the Parse Timestamp and Parse Time functions provide format options which include HH, mm and ss. Thus, you can enter HH for hour, mm for minute for day and ss for seconds as parts. When the Extract Regex Groups function is used, this value refers to the group numbers, where 0 = entire match, 1 = first group, 2 = 2nd group, and so on. This value can also be a named group. Named groups can also be used if defined in the pattern (for example, (?<name>...) ? name). For more information, see Functions. |
Derived Field Name | A default derived field name (d_<FieldName>ParseExtract or d_<FieldName>ParseExtract_n, where “n” is 1,2,3, and so on) is provided and displayed here. However, you can edit or overwrite it. See Derived Fields. |
Data Type | The data type of the part. |
Functions
The following functions are available.
Function | Description |
|---|---|
Parse Full Name | This function is only available for string fields, and requires that you select a format to parse string into. Parses a full name into the following PartIDs: • title - The title part of a full name. For example, Mr and Mrs. • first - The first name part of a full name. • middle - The middle name part of a full name. • last - The last name part of a full name. • suffix - The suffix part of a full name. For example, PhD and Sr. |
Parse Address | Parses a postal address into the following PartIDs: • street - The street address. • city - The city name. • postcode - The zip code parsed from the address. • state - The state name. • po_box - The post office box number. • country - The country name. |
Parse Email | Parses an email into the following PartIDs: • username - The username part of the email (the part before the @ symbol). • domain - The email domain (the part after the @ symbol). |
Parse Timestamp | This function is only available for string fields, and requires that you select a format to parse string into. Parses the parts of a timestamp based on the symbols defined for SimpleDateFormat (Java Platform SE 8). See https://docs.oracle.com/javase/8/docs/api/java/text/SimpleDateFormat.html. One or more symbols can be referenced in a single part. For example, PartID = dd-MM returns 12-09 for a timestamp value 12-09-2002T30:30:34 |
Parse Date | This function is only available for string fields, and requires that you select a format to parse string into. Parses the parts of a date based on the symbols defined for SimpleDateFormat (Java Platform SE 8). See https://docs.oracle.com/javase/8/docs/api/java/text/SimpleDateFormat.html. One or more symbols can be referenced in a single part. For example, PartID = dd-MM returns 12-09 for a timestamp value 12-09-2002T30:30:34 |
Parse Time | This function is only available for time fields, and requires that you select a format to parse string into. Parses time parts based on the symbols specified for SimpleDateFormat (Java Platform SE 8). See https://docs.oracle.com/javase/8/docs/api/java/text/SimpleDateFormat.html. One or more symbols can be referenced in a single part. For example, PartID = HH-mm returns 30-30 for a timestamp value 12-09-2002T30:30:34. |
Parse URI | Parses an URI into the following PartIDs: • scheme - The scheme part of the URI. For example, http, https, ftp, s3. • username - The username part of the URI, if one is referenced. • host - The hostname part of the URI. • port - The port specified in the URI. • path - The path segment of the URI. • query - The query part of the URI which is typically followed by the ? character. |
Extract Regex Groups | Extracts the groups captured from the specified regular expression when it matches the field value. This function requires that you enter a regular expression. The Part identifier in this case refers to the group numbers, where 0 = entire match, 1 = first group, 2 = 2nd group, and so on. The Part identifier can also be a named group. Simple example: (.+?)\s(.+?) - In this case, there are two groups as can be seen in matching parenthesis groups. Suppose the input is ‘Actian Corporation’, then PartId = 1 returns Actian, PartId = 2 will yield Corporation. Named Group example: (<cname>.+?)\s.+ - In this case, there is one named group, cname. PartId = cname returns Actian for the input Actian Corporation. |
Supported Data Types
String (input)
String (output)
Remarks
Does not provide pass and fail statistics and generates a derived field. See Derived Fields.
Example
To illustrate how to use the ParseExtract rule, we apply the rule to a Name column which contains a first name, middle name and last name in a single field. We will extract the first and last names into two new output fields.
1. In the Rules tab, Fields section, click  > Add New Rule, then select the Name field from the Select Field Name drop-down list.
> Add New Rule, then select the Name field from the Select Field Name drop-down list.
2. In the Data Prep tab, select ParseExtract, and Finish.
The rule is displayed under the Name field.
The rule is displayed under the Name field.
3. In the Rule Definition pane, the default Rule Name, Name_ParseExtract, is displayed (which can be edited). Do the following:
• Select Parse Full Name from the Function drop-down.
• Select [last] [first] from the Format drop-down.
• Click  > Add Available Parts.
> Add Available Parts.
• Select unwanted parts (retain first and last) and click  to delete.
to delete.
4. In the Field/Rule pane, create two new output fields by doing the following:
• Click  > Add New Field, change the default name, field-1 (which appears at the bottom of the Field/Rule list), to match the first part name. In this case, we enter first.
> Add New Field, change the default name, field-1 (which appears at the bottom of the Field/Rule list), to match the first part name. In this case, we enter first.
• Click  > Add New Field, change the default name, field-2 (which appears at the bottom of the Field/Rule list), to match the first part name. In this case, we enter last.
> Add New Field, change the default name, field-2 (which appears at the bottom of the Field/Rule list), to match the first part name. In this case, we enter last.
5. Map the two new fields to the relevant derived field content by doing the following:
• first field - Click in the Expression field and select d_Name_ParseExtract_1 from the drop-down list.
• last field - Click in the Expression field and select d_Name_ParseExtract_3 from the drop-down list.
6. Save the profile, then click  to execute the profile.
to execute the profile.
The Total pass/fail data pie chart is displayed.
The Total pass/fail data pie chart is displayed.
7. Click the pie chart to open the Drill Down data tab.
Scroll to the right to see the three new fields populated with the data.
Scroll to the right to see the three new fields populated with the data.
Tip... If you no longer need to see the Name field in the output you can remove it: Select it under -Output Fields- and click  to delete it. The Name field is not deleted in the source data.
to delete it. The Name field is not deleted in the source data.
StringJoin
This rule combines multiple fields into a single value, based on a specified delimiter. A derived field is auto-generated for the new value. The derived field can be used for further processing, to build additional rules (such as referencing the derived field in a rule), and to create a new output field.
This rule supports all data types. Default text formatting is used to convert and output to a string format. For example, date, time and timestamp fields are formatted using the ISO 8601 format.
Once the StringJoin rule is added to a profile, it is categorized under -MultiFieldRules- on the Rules tab, instead of under -OutputFields-.
A derived field is stored in-memory (RAM). The derived fields are available in-memory and can be used for further profiling and analysis. Users can also include the derived field values with profile output fields. For more information, see Derived Fields.
Rule Properties
This rule has the following properties.
Rule Name | The default rule name (StringJoin or StringJoin_n, where “n” is 1,2,3, and so on) is provided and displayed here. Click Reset to restore the default rule name. Note: The underscore (_) character is the only special character allowed in the name. Rule names cannot begin with a digit. If a field or column in the source data starts with a digit, 'r_' will be prepended to any rules created based on that field. |
Field Name | -MultipleFields- is displayed here. |
Rule Type | The type of rule that is applied to the field. That is StringJoin (Function rule). Tip... A Red Cross in a rule icon (for example |
Rule Parameters
This rule has the following properties.
Delimiter | (optional) Select or enter the delimiter to use between each string in the joined result. For example, if the delimiter is set to Comma (,) each string in the resulting value will be separated by a comma: <String1>,<String2>,<String3>. By default, this parameter is set to Comma (,). If a delimiter is not required, the delimiter can be set to an empty string. Options are: • COMMA (default) • SEMICOLON • TAB • SPACE • PIPE • COLON • CR_LF • LF • CR |
Skip Null/Empty Values | (required) Specifies whether null or empty values are included in the joined result. • Select to exclude (True) null or empty strings from the joined result. • Deselect to include (False) null or empty strings in the joined result. By default, this parameter is set to include (False). |
Null Substitute | (optional) When the Skip Null/Empty Values parameter is set to include (False), this parameter specifies the string for representing null values in the final joined result. For example, if the null substitute is set to N/A, all null values are replaced with N/A in the joined result string: <String1>,<N/A>,<String3>. This parameter is only available when the Skip Null/Empty Values parameter is set to include (False). |
Derived Field Name | A default derived field name (d_<FieldName>StringJoin or d_<FieldName>StringJoin_n, where “n” is 1,2,3, and so on) is provided and displayed here. However, you can edit or overwrite it. The name can be edited. See Derived Fields. |
Available | Lists fields that are available for joining. Select one or more fields that you want to include in the join, then click > to move them to the Selected list. Click >> to add all the fields. |
Selected | Lists fields that will be joined. Select one or more fields and click < to move them back into the Available list. Click << to remove all the fields. Click the up and down icons ( |
Supported Data Types
All data types (input)
String (output)
Remarks
Does not provide pass and fail statistics and generates a derived field. See Derived Fields.
Example
To illustrate how to use the StringJoin rule, we join two columns: an Account column and a Balance column, using the pipe delimiter: <Account>|<Balance>.
After the StringJoin rule generates a derived field for the new, joined values, we create a new output field called Account&Balance, map it to the derived field, and view the new, joined values in the output. The Account&Balance output field will have, for example, the following output: 01-6063|262.98.
1. In the Rules tab, Fields section, click  > Add New Rule, then select the Account Number field from the Select Field Name drop-down list.
> Add New Rule, then select the Account Number field from the Select Field Name drop-down list.
2. In the Data Prep tab, select StringJoin, and Finish.
3. In the Rule Definition pane, select PIPE from the Delimiter drop-down, then select null from the Null Substitute drop-down.
4. In the Available list, select Balance and click > to add it to the Selected list. Use the up/down arrows to reorder the fields.
5. In the Field/Rule pane, create a new output field by doing the following:
• Click  > Add New Field, change the default name, field-1 (which appears at the bottom of the Field/Rule list), to a descriptive name for the derived content. In this case, we name it Account&Balance.
> Add New Field, change the default name, field-1 (which appears at the bottom of the Field/Rule list), to a descriptive name for the derived content. In this case, we name it Account&Balance.
• Map the new field to the derived field content by clicking the Account&Balance Expression field and selecting d_Account_Number_StringJoin from the drop-down list.
6. Save the profile, then click  to execute the profile.
to execute the profile.
The Total pass/fail data pie chart is displayed.
The Total pass/fail data pie chart is displayed.
7. Click the pie chart to open the Drill Down data tab.
Scroll to the right to see the three new fields populated with the data.
To edit the rule, return to the Rules tab and select the rule under -MultiFieldRules-.
Scroll to the right to see the three new fields populated with the data.
To edit the rule, return to the Rules tab and select the rule under -MultiFieldRules-.
Tip... If you no longer need to see the Account Number field in the output you can remove it: Select it under -Output Fields- and click  to delete it. The Account Number field is not deleted in the source data.
to delete it. The Account Number field is not deleted in the source data.
StringSplit
This rule splits a string value in a field into separate substrings, or parts, based on a specified delimiter. A derived field is auto-generated for each part. The derived fields can be used for further processing, to build additional rules (such as referencing the derived field in a rule), and to create new output fields.
For example, if your source data has a Name column that contains both first and last names, and you need a column strictly for first names and a column strictly for last names. You can use the StringSplit rule to create the two columns. The columns can then be included in the profile output.
For a step-by-step example, see Example
A derived field is stored in-memory (RAM). The derived fields are available in-memory and can be used for further profiling and analysis. Users can also include the derived field values with profile output fields. For more information, see Derived Fields.
Rule Properties
This rule has the following properties.
Rule Name | The default rule name (<FieldName>_StringSplit) is provided and displayed here. However, you can edit or overwrite it. Click Reset to restore the default rule name. Note: The underscore (_) character is the only special character allowed in the name. Rule names cannot begin with a digit. If a field or column in the source data starts with a digit, 'r_' will be prepended to any rules created based on that field. |
Field Name | The field name to which the rule applies is displayed here, along with the data type in parentheses. For example, Name (String). |
Rule Type | The type of rule that is applied to the field. That is StringSplit (Function rule). |
Rule Parameters
This rule has the following properties.
Limit | (optional) Specifies the maximum number of parts to include in the result of the string split. If the limit is greater than zero (0), the number of parts will not exceed the limit specified, and the last part will contain the last portion of the original string. If the limit is zero (0) or less, all substrings produced by the split will be included. The default value is 20. Note: You will still be able to add additional parts that exceed the Limit specified. |
Delimiter | (optional) Select or enter the delimiter to be used for splitting the substrings in the field. The delimiter is treated as a literal string unless the Regex checkbox is selected (which makes it suitable for straightforward splitting scenarios). The default value is SPACE. Options are: • COMMA • SEMICOLON • TAB • SPACE • PIPE • COLON • CR_LF • LF • CR |
Regex | (optional) Specifies whether the delimiter used is treated as a regex expression. By default, this option is deselected. • Select to treat the delimiter as a regex expression. • Deselect to treat the delimiter as a literal string such as a comma (,). |
(required) Add the parts that you want to derive into memory as a field. You can add the parts one at a time, or add the number specified in the Limit parameter. Click • Add Part - Adds a single row for referencing a specific split substring (for example, 0th, 10th, 20th, and so on). • Add Available Parts - Adds the number of parts specified by the Limit, and automatically fills in Part ids with 0 as the index of the first split substring. Note: After using Add Available Parts, you can still add additional parts. | |
Part | Index of the split substring within the result, starting with 0 as the first element. |
Derived Field Name | A default derived field name (d_<FieldName>StringSplit or d_<FieldName>StringSplit_n, where “n” is 1,2,3, and so on) is provided and displayed here. However, you can edit or overwrite it. See Derived Fields. |
Data Type | The data type in the derived field. |
Supported Data Types
String (input)
This rule outputs a list of substrings which are derived as fields into memory.
Example
To illustrate how to use the StringSplit rule we use a case where the source data has a Name column that contains a value comprised of two substrings - a first name and a last name:
<firstName> <lastName>
We want our output to have a column strictly for first names and a column strictly for last names.
Since the two substrings are separated by a space, we use the SPACE delimiter to split the value into two parts. When the parts are created two derived fields are auto-generated. We will link those derived fields to two new output fields we also create: FirstName and LastName.
1. In the Rules tab, click  > Add New Rule, then select the Name field from the Select Field Name drop-down list.
> Add New Rule, then select the Name field from the Select Field Name drop-down list.
Rules that are applicable to the data in the selected field are listed.
Rules that are applicable to the data in the selected field are listed.
2. In the Data Prep tab, select StringSplit, and Finish.
In the Rule Definition pane, the default Rule Name, Name_StringSplit, is displayed (which can be edited), and a single derived field placeholder is listed in the Parts table.
In the Rule Definition pane, the default Rule Name, Name_StringSplit, is displayed (which can be edited), and a single derived field placeholder is listed in the Parts table.
3. Set Limit to 2 and select SPACE from the Delimiter drop-down.
4. Click  > Add Part to add a second derived field name, and enter 1 in the Part column.
> Add Part to add a second derived field name, and enter 1 in the Part column.
5. In the Field/Rule pane, create two new output fields by doing the following:
• Click  > Add New Field, change the default name, field-1 (which appears at the bottom of the Field/Rule list), to a descriptive name for the derived content. In this case, we name it First Name.
> Add New Field, change the default name, field-1 (which appears at the bottom of the Field/Rule list), to a descriptive name for the derived content. In this case, we name it First Name.
• Click  > Add New Field, change the default name, field-2 (which appears at the bottom of the Field/Rule list), to a descriptive name for the derived content. In this case, we name it Last Name.
> Add New Field, change the default name, field-2 (which appears at the bottom of the Field/Rule list), to a descriptive name for the derived content. In this case, we name it Last Name.
6. Map the two new fields to the corresponding derived field by doing the following:
• First Name field - Click in the Expression field and select d_Name_StringSplit_0 from the drop-down list.
• Last Name field - Click in the Expression field and select d_Name_StringSplit_1 from the drop-down list.
7. Save the profile, then click  to execute the profile.
to execute the profile.
The Total pass/fail data pie chart is displayed.
The Total pass/fail data pie chart is displayed.
8. Click the pie chart to open the Drill Down data tab.
Scroll to the right to see the new fields populated with the data.
Scroll to the right to see the new fields populated with the data.
StringToConversion
This rule converts a given string field into a specified data type.
A derived field is stored in-memory (RAM). The derived fields are available in-memory and can be used for further profiling and analysis. Users can also include the derived field values with profile output fields. For more information, see Derived Fields.
Rule Properties
This rule has the following properties.
Rule Name | A default rule name (<FieldName>_StringToConversion) is provided and displayed here. However, you can edit or overwrite it. Click Reset to restore the default rule name. Note: The underscore (_) character is the only special character allowed in the name. Rule names cannot begin with a digit. If a field or column in the source data starts with a digit, 'r_' will be prepended to any rules created based on that field. |
Field Name | The field name to which the rule applies is displayed here, along with the data type in parentheses. For example, ZIP (String). |
Rule Type | The type of rule that is applied to the field. That is StringToConversion (Conversion rule). |
Rule Parameters
This rule has the following parameters.
Convert To | The data type of the derived in-memory field: • Boolean • Date • Double • Float • Int • Long • Numeric • Time • TimeStamp |
Format | The following formats are required when converting to Boolean derived field: • True.False • Yes.No • 1.0 • T.F |
The following formats are required when converting to Date derived field. You can select from the available options or specify your own pattern in the text box. See DateTime Format. • yyyy-M-dd • yyyy-MM-dd • MM/dd/yy • M/dd/yyyy • MM/dd/yyyy • M-dd-yyyy • MM-dd-yyyy • MMM-yy • MMM dd, yyyy | |
The following formats are required when converting to Time derived field. You can select from the available options or specify your own pattern in the text box. See DateTime Format. • HH:mm:ss • HH:mm • hh:mm:ss • hh:mm aa | |
The following formats are required when converting to TimeStamp derived field. You can select from the available options or specify your own pattern in the text box. See DateTime Format. • yyyy-MM-dd HH:mm:ss • MM/dd/yyyy HH:mm • MMM dd, yyyy HH:mm aa • EEE, dd MMM yyyy HH:mm:ss Z Note: Note: ISO 8601 format should be mentioned as yyyy-MM-dd'T'HH:mm:ss+hh:mm. T in this format must be enclosed within single quotes, 'T'. • Time Zone - Select your time zone from the available options. | |
When converting to Numeric, Double, Float, Long, and Int derived field, there are no parameters to specify. | |
Derived Field Name | A default derived field name (d_FieldName_StringToConversion, d_FieldName_StringToConversion_n, where “FieldName” is the field the rule applies to, “n” is 1,2,3, and so on) is provided and displayed here. However, you can edit or overwrite it. See Derived Fields. |
Supported Data Types
String (input)
Date, Time, TimeStamp, Boolean, Numeric, Double, Float, Long, Int (output)
Remarks
Provides pass and fail statistics and generates a derived field. See Derived Fields.
Last modified date: 05/27/2026