Statistics
The DataFlow operator library contains several prebuilt statistics and data summarizer operators. This topic covers each of those operators and provides details on how to use them.
Statistics Operators
Using the DataQualityAnalyzer Operator to Analyze Data Quality
The
DataQualityAnalyzer operator is used to evaluate a set of quality tests on an input data set. Those records for which all tests pass are considered "clean" and are thus sent to the clean output. Those records for which any tests fail are considered "dirty" and are thus sent to the dirty output.
This operator also produces a PMML summary model that includes the following statistics:
• totalFrequency: Total number of rows.
• invalidFrequency: Total number of rows for which at least one test involving the given field failed.
• testFailureCounts: Per-test failure counts for each test involving the given field.
Using Expressions to Create Quality Metrics
Quality metrics can be specified by using the expression language. Any number of quality metrics can be specified by passing a single expression directly to the DataQualityAnalyzer operator. The syntax of a quality metric expression is:
<predicate expression 1> as <metric name 1>[, <predicate expression 2> as <metric name 2>, ...]
Each expression must be a predicate expression that returns a boolean value. For example, the following expression can be passed directly to the DataQualityAnalyzer, assuming your input has the specified input fields:
class is not null as class_not_null, `petal length` > 0 as length_gt_zero, `petal width` > 0 as width_gt_zero
As with field names used elsewhere within expressions, the metric name can be surrounded by back-ticks if it contains non-alphanumeric characters, such as in the expression:
class is not null as `class-not-null`
For more information about syntax and available functions, see the
Expression Language.
Code Example
This example demonstrates using the DataQualityAnalyzer operator to ensure the "class" field is non-null and that the petal measurements are greater than zero. This example uses a quality metric expression to specify the metrics to apply to the input data.
Using the DataQualityAnlayzer operator in Java
This example demonstrates using the DataQualityAnalyzer operator creating QualityTest instances directly.
Using the DataQualityAnlayzer operator in Java
// Create the DataQualityAnalyzer operator
DataQualityAnalyzer dqa = graph.add(new DataQualityAnalyzer());
QualityTest test1 = new QualityTest(
"class_not_null",
Predicates.notNull("class"));
QualityTest test2 = new QualityTest(
"length_gt_zero",
Predicates.gt(FieldReference.value("petal length"), ConstantReference.constant(0)));
QualityTest test3 = new QualityTest(
"width_gt_zero",
Predicates.gt(FieldReference.value("petal width"), ConstantReference.constant(0)));
dqa.setTests(Arrays.asList(test1, test2, test3));
Using the DataQualityAnalyzer operator in RushScript
var results = dr.dataQualityAnalyzer(data, {tests:'class is not null as class_not_null, `petal length` > 0 as length_gt_zero, `petal width` > 0 as width_gt_zero'});
Properties
The
DataQualityAnalyzer operator provides the following properties.
Ports
The
DataQualityAnalyzer operator provides a single input port.
The
DataQualityAnalyzer operator provides the following output ports.
Using the SummaryStatistics Operator to Calculate Data Statistics
The
SummaryStatistics operator discovers various metrics of an input data set based on the configured detail level. The types of the fields, combined with the detail level, determine the set of metrics that are calculated.
If the detail level is SINGLE_PASS_ONLY_SIMPLE, the following statistics are calculated.
If the detail level is SINGLE_PASS_ONLY, all of the statistics that are calculated for SINGLE_PASS_ONLY_SIMPLE are calculated. In addition, the following are also calculated.
If the detail level is MULTI_PASS, all of the statistics that are calculated for SINGLE_PASS_ONLY are calculated. In addition, the following are also calculated.
Important! The correct data type must be selected to avoid overflows. If overflows occur, try increasing the size of the data type from float to double or double to numeric.
Code Example
This example calculates summary statistics for the Iris data set. The
SummaryStatistics operator produces a PMML model containing summary statistics. This example writes the PMML to a file. It also obtains an in-memory reference to the statistics and outputs to a file.
Using the SummaryStatistics operator in Java
import static com.pervasive.datarush.types.TokenTypeConstant.DOUBLE;
import static com.pervasive.datarush.types.TokenTypeConstant.STRING;
import static com.pervasive.datarush.types.TokenTypeConstant.record;
import com.pervasive.datarush.analytics.pmml.PMMLModel;
import com.pervasive.datarush.analytics.pmml.PMMLPort;
import com.pervasive.datarush.analytics.pmml.WritePMML;
import com.pervasive.datarush.analytics.stats.DetailLevel;
import com.pervasive.datarush.analytics.stats.PMMLSummaryStatisticsModel;
import com.pervasive.datarush.analytics.stats.SummaryStatistics;
import com.pervasive.datarush.analytics.stats.UnivariateStats;
import com.pervasive.datarush.graphs.LogicalGraph;
import com.pervasive.datarush.graphs.LogicalGraphFactory;
import com.pervasive.datarush.operators.io.textfile.ReadDelimitedText;
import com.pervasive.datarush.operators.model.GetModel;
import com.pervasive.datarush.schema.TextRecord;
import com.pervasive.datarush.types.RecordTokenType;
public class IrisSummaryStats {
public static void main(String[] args) {
// Create an empty logical graph
LogicalGraph graph = LogicalGraphFactory.newLogicalGraph("SummaryStats");
// Create a delimited text reader for the Iris data
ReadDelimitedText reader = graph.add(new ReadDelimitedText("data/iris.txt"));
reader.setFieldSeparator(" ");
reader.setHeader(true);
RecordTokenType irisType = record(
DOUBLE("sepal length"),
DOUBLE("sepal width"),
DOUBLE("petal length"),
DOUBLE("petal width"),
STRING("class"));
reader.setSchema(TextRecord.convert(irisType));
// Run summary statistics on the data and normalized values
SummaryStatistics summaryStats = graph.add(new SummaryStatistics());
summaryStats.setDetailLevel(DetailLevel.MULTI_PASS);
summaryStats.setShowTopHowMany(25);
graph.connect(reader.getOutput(), summaryStats.getInput());
// Use the GetModel operator to obtain a reference to the statistics model.
// This reference is valid after the graph is run and can be used to then
// access the statistics model outside of the graph.
GetModel<PMMLModel> modelOp = graph.add(new GetModel<PMMLModel>(PMMLPort.FACTORY));
graph.connect(summaryStats.getOutput(), modelOp.getInput());
// Write the PMML generated by summary stats
WritePMML pmmlWriter = graph.add(new WritePMML("results/iris-summarystats.pmml"));
graph.connect(summaryStats.getOutput(), pmmlWriter.getModel());
// Compile and run the graph
graph.run();
// Use the model reference to get the actual stats model
PMMLSummaryStatisticsModel statsModel = (PMMLSummaryStatisticsModel) modelOp.getModel();
// Print out stats for the numeric fields
for (String fieldName : new String[] {"sepal length", "sepal width", "petal length", "petal width"}) {
UnivariateStats fieldStats = statsModel.getFieldStats(fieldName);
System.out.println("Field: " + fieldName);
System.out.println(" frequency = " + fieldStats.getTotalFrequency());
System.out.println(" missing = " + fieldStats.getMissingFrequency());
System.out.println(" min = " + fieldStats.getNumericInfo().getMin());
System.out.println(" max = " + fieldStats.getNumericInfo().getMax());
System.out.println(" mean = " + fieldStats.getNumericInfo().getMean());
System.out.println(" stddev = " + fieldStats.getNumericInfo().getStddev());
}
}
}
Using the SummaryStatistics operator in RushScript
var results = dr.summaryStatistics(data, {includedFields:"sepal length", detailLevel:DetailLevel.MULTI_PASS});
Properties
The
SummaryStatistics operator has the following properties.
Ports
The
SummaryStatistics operator provides a single input port.
The
SummaryStatistics operator provides a single output port.
Using the DistinctValues Operator to Find Distinct Values
The
DistinctValues operator calculates the distinct values of the given input field. This produces a record consisting of the input field with only the distinct values, and a count field with the number of occurrences of each value.
Code Example
This example calculates the number of distinct types of iris present in the data set.
Using the DistinctValue operator in Java
import static com.pervasive.datarush.types.TokenTypeConstant.DOUBLE;
import static com.pervasive.datarush.types.TokenTypeConstant.STRING;
import static com.pervasive.datarush.types.TokenTypeConstant.record;
import com.pervasive.datarush.analytics.stats.DistinctValues;
import com.pervasive.datarush.graphs.LogicalGraph;
import com.pervasive.datarush.graphs.LogicalGraphFactory;
import com.pervasive.datarush.io.WriteMode;
import com.pervasive.datarush.operators.io.textfile.ReadDelimitedText;
import com.pervasive.datarush.operators.io.textfile.WriteDelimitedText;
import com.pervasive.datarush.schema.TextRecord;
import com.pervasive.datarush.types.RecordTokenType;
/**
* Determine all distinct classes of iris.
*/
public class DistinctIris {
public static void main(String[] args) {
// Create an empty logical graph
LogicalGraph graph = LogicalGraphFactory.newLogicalGraph("DistinctValues");
// Create a delimited text reader for the Iris data
ReadDelimitedText reader = graph.add(new ReadDelimitedText("data/iris.txt"));
reader.setFieldSeparator(" ");
reader.setHeader(true);
RecordTokenType irisType = record(
DOUBLE("sepal length"),
DOUBLE("sepal width"),
DOUBLE("petal length"),
DOUBLE("petal width"),
STRING("class"));
reader.setSchema(TextRecord.convert(irisType));
// Initialize the DistinctValues operator
DistinctValues distinct = graph.add(new DistinctValues());
distinct.setInputField("class");
// Connect the reader to distinct
graph.connect(reader.getOutput(), distinct.getInput());
// Write the distinct values for the class field
WriteDelimitedText writer = graph.add(new WriteDelimitedText("results/iris-distinct.txt", WriteMode.OVERWRITE));
writer.setFieldSeparator(",");
writer.setFieldDelimiter("");
writer.setHeader(true);
writer.setWriteSingleSink(true);
// Connect rank to the writer
graph.connect(distinct.getOutput(), writer.getInput());
// Compile and run the graph
graph.run();
}
}
Using the DistinctValues operator in RushScript
var results = dr.distinctValues(data, {inputField:"class"});
Properties
The
DistinctValues operator provides the following properties.
Ports
The
DistinctValues operator provides a single input port.
The
DistinctValues operator provides a single output port.
Using the NormalizeValues Operator to Normalize Values
The
NormalizeValues operator applies normalization methods to fields within an input data flow. The results of the normalization methods are available in the output flow. All input fields are present in the output with the addition of the calculated normalizations.
Normalization methods require certain statistics about the input data such as the mean, standard deviation, minimum value, maximum value, and so on. These statistics are captured in a
PMMLModel. The statistics can be gathered by an upstream operator such as
SummaryStatistics and passed into this operator. If not, they will be calculated with a first pass over the data and then applied in a second pass.
Code Example
This example normalizes the Iris data set using the z-score method.
Using the NormalizeValues operator in Java
import static com.pervasive.datarush.types.TokenTypeConstant.DOUBLE;
import static com.pervasive.datarush.types.TokenTypeConstant.STRING;
import static com.pervasive.datarush.types.TokenTypeConstant.record;
import static com.pervasive.datarush.analytics.functions.StatsFunctions.NormalizeMethod.ZSCORE;
import com.pervasive.datarush.analytics.stats.NormalizeValues;
import com.pervasive.datarush.graphs.LogicalGraph;
import com.pervasive.datarush.graphs.LogicalGraphFactory;
import com.pervasive.datarush.io.WriteMode;
import com.pervasive.datarush.operators.io.textfile.ReadDelimitedText;
import com.pervasive.datarush.operators.io.textfile.WriteDelimitedText;
import com.pervasive.datarush.schema.TextRecord;
import com.pervasive.datarush.types.RecordTokenType;
/**
* Compute the normalized z-score values for the iris data set.
*/
public class NormalizeIris {
public static void main(String[] args) {
// Create an empty logical graph
LogicalGraph graph = LogicalGraphFactory.newLogicalGraph("Normalize");
// Create a delimited text reader for the Iris data
ReadDelimitedText reader = graph.add(new ReadDelimitedText("data/iris.txt"));
reader.setFieldSeparator(" ");
reader.setHeader(true);
RecordTokenType irisType = record(
DOUBLE("sepal length"),
DOUBLE("sepal width"),
DOUBLE("petal length"),
DOUBLE("petal width"),
STRING("class"));
reader.setSchema(TextRecord.convert(irisType));
// Initialize the NormalizeValues operator
NormalizeValues norm = graph.add(new NormalizeValues());
norm.setScoreFields("sepal length", "sepal width", "petal length", "petal width");
norm.setMethod(ZSCORE);
// Connect the reader to normalize
graph.connect(reader.getOutput(), norm.getInput());
// Write the normalized data
WriteDelimitedText writer = graph.add(new WriteDelimitedText("results/iris-zscore.txt", WriteMode.OVERWRITE));
writer.setFieldSeparator(",");
writer.setFieldDelimiter("");
writer.setHeader(true);
writer.setWriteSingleSink(true);
// Connect normalize to the writer
graph.connect(norm.getOutput(), writer.getInput());
// Compile and run the graph
graph.run();
}
}
Using the NormalizeValues operator in RushScript
var scoreFields = ["sepal length", "sepal width", "petal length", "petal width"];
var results = dr.normalizeValues(data, {scoreFields:scoreFields, method:NormalizeMethod.ZSCORE});
Properties
The
NormalizeValues operator provides the following properties.
Ports
The
NormalizeValues operator provides the following input ports.
The
NormalizeValues operator provides a single output port.
Using the Rank Operator to Rank Data
The
Rank operator is used to rank data using the given rank mode. The data is grouped by the given partition fields and is sorted within the grouping by the ranking fields. An example is to rank employees by salary per department. To rank the highest to lowest salary within department: partition by the department and rank by the salary in descending sort order.
Three different rank modes are supported:
STANDARD
Also known as competition ranking, items with the same ranking values have the same rank and then a gap is left in the ranking numbers. For example: 1224
DENSE
Items that comparison determines are equal receive the same ranking. Items following those receive the next ordinal ranking (that is, ranks are not skipped). For example: 1223
ORDINAL
Each item receives a distinct ranking, starting at one and increasing by one, producing essentially a row number within the partition. For example: 1234
A new output field is created to contain the result of the ranking. The field is named "rank" by default.
Code Example
In this example we use the
Rank operator to order the Iris data set by the "sepal length" field, partitioning by the "class" field.
Using the Rank operator in Java
import static com.pervasive.datarush.types.TokenTypeConstant.DOUBLE;
import static com.pervasive.datarush.types.TokenTypeConstant.STRING;
import static com.pervasive.datarush.types.TokenTypeConstant.record;
import com.pervasive.datarush.analytics.stats.Rank;
import com.pervasive.datarush.analytics.stats.Rank.RankMode;
import com.pervasive.datarush.graphs.LogicalGraph;
import com.pervasive.datarush.graphs.LogicalGraphFactory;
import com.pervasive.datarush.io.WriteMode;
import com.pervasive.datarush.operators.io.textfile.ReadDelimitedText;
import com.pervasive.datarush.operators.io.textfile.WriteDelimitedText;
import com.pervasive.datarush.schema.TextRecord;
import com.pervasive.datarush.types.RecordTokenType;
/**
* Rank the iris data set by sepal length, partition by class
*/
public class RankIris {
public static void main(String[] args) {
// Create an empty logical graph
LogicalGraph graph = LogicalGraphFactory.newLogicalGraph("Rank");
// Create a delimited text reader for the Iris data
ReadDelimitedText reader = graph.add(new ReadDelimitedText("data/iris.txt"));
reader.setFieldSeparator(" ");
reader.setHeader(true);
RecordTokenType irisType = record(
DOUBLE("sepal length"),
DOUBLE("sepal width"),
DOUBLE("petal length"),
DOUBLE("petal width"),
STRING("class"));
reader.setSchema(TextRecord.convert(irisType));
// Initialize the Rank operator
Rank rank = graph.add(new Rank());
rank.setPartitionBy("class");
rank.setRankBy("sepal length");
rank.setMode(RankMode.STANDARD);
// Connect the reader to rank
graph.connect(reader.getOutput(), rank.getInput());
// Write the data with the additional rank field
WriteDelimitedText writer = graph.add(new WriteDelimitedText("results/iris-rank.txt", WriteMode.OVERWRITE));
writer.setFieldSeparator(",");
writer.setFieldDelimiter("");
writer.setHeader(true);
writer.setWriteSingleSink(true);
// Connect rank to the writer
graph.connect(rank.getOutput(), writer.getInput());
// Compile and run the graph
graph.run();
}
}
Using the Rank operator in RushScript
var results = dr.rank(data, {partitionBy:'class', rankBy:'"sepal length" desc', mode:RankMode.STANDARD});
Properties
The
Rank operator provides the following properties.
Ports
The
Rank operator provides a single input port.
The
Rank operator provides a single output port.
Using the SumOfSquares Operator to Compute a Sum of Squares
The
SumOfSquares operator computes the sum of squares for the given fields in the input data. The inner products are calculated in a distributed fashion with a reduction at the end to produce the sum of squares matrix. Note that all the fields must be of type double or be assignable to a double type.
Code Example
The following example demonstrates computing the sum of squares matrix over three double fields.
Using the SumOfSquares operator in Java
// Calculate the Sum of Squares
SumOfSquares sos = graph.add(new SumOfSquares());
sos.setFieldNames(Arrays.asList(new String[]{"dblfield1", "dblfield2", "dblfield3"}));
Using the SumOfSquares operator in RushScript
var results = dr.sumOfSquares(data, {
fieldNames:['dblfield1', 'dblfield2', 'dblfield3']});
Properties
The
SumOfSquares operator provides the following properties.
Ports
The
SumOfSquares operator provides a single input port.
The
SumOfSquares operator provides a single output port.
Support Vector Machine
Support Vector Machines within DataFlow
A support vector machine (SVM) is a supervised learning model that analyzes data and recognize patterns. It is often used for data classification.
A basic SVM is a nonprobabilistic binary linear classifier, which means it takes a set of input data and predicts, for each given input, which of two possible classes forms the output. In addition, support vector machines can efficiently perform nonlinear classification using what is called the kernel trick, which implicitly maps their inputs into high-dimensional feature space.
DataFlow provides operators to produce and utilize SVM models. The learner is used to determine the classification rules for a particular data set, while the predictor can apply these rules to a data set.
Covered SVM Operators
Using the SVMLearner Operator to Build a PMML Support Vector Machine Model
The
SVMLearner operator is responsible for building a PMML Support Vector Machine model from input data. It is implemented as a wrapper for the LIBSVM library found at
http://www.csie.ntu.edu.tw/%7Ecjlin/libsvm/.
Code Example
This example uses the
SVMLearner operator to train a predictive model base on the Iris data set. It uses the "class" field within the iris data as the target column.
Using the SVMLearner operator in Java
import static com.pervasive.datarush.types.TokenTypeConstant.DOUBLE;
import static com.pervasive.datarush.types.TokenTypeConstant.STRING;
import static com.pervasive.datarush.types.TokenTypeConstant.record;
import java.util.Arrays;
import com.pervasive.datarush.analytics.pmml.WritePMML;
import com.pervasive.datarush.analytics.svm.PolynomialKernelType;
import com.pervasive.datarush.analytics.svm.learner.SVMLearner;
import com.pervasive.datarush.analytics.svm.learner.SVMTypeCSvc;
import com.pervasive.datarush.graphs.LogicalGraph;
import com.pervasive.datarush.graphs.LogicalGraphFactory;
import com.pervasive.datarush.operators.io.textfile.ReadDelimitedText;
import com.pervasive.datarush.schema.TextRecord;
import com.pervasive.datarush.types.RecordTokenType;
/**
* Use the SVM learner to train a predictive model based on the iris data set.
*/
public class SVMIris {
public static void main(String[] args) {
// Create an empty logical graph
LogicalGraph graph = LogicalGraphFactory.newLogicalGraph("SVMIris");
// Create a delimited text reader for the Iris training and query data
ReadDelimitedText reader = graph.add(new ReadDelimitedText("data/iris.txt"));
reader.setFieldSeparator(" ");
reader.setHeader(true);
String[] classTypes = {"Iris-setosa", "Iris-versicolor", "Iris-virginica"};
RecordTokenType irisType = record(
DOUBLE("sepal length"),
DOUBLE("sepal width"),
DOUBLE("petal length"),
DOUBLE("petal width"),
DOMAIN(STRING("class"), classTypes);
reader.setSchema(TextRecord.convert(irisType));
// Create a SVMLearner operator
SVMLearner svm = graph.add(new SVMLearner());
svm.setKernelType(new PolynomialKernelType().setGamma(3));
svm.setType(new SVMTypeCSvc("class", 1));
// Connect the reader and the SVM
graph.connect(reader.getOutput(), svm.getInput());
// Write the PMML generated by SVM
WritePMML pmmlWriter = graph.add(new WritePMML("results/polynomial-SVM.pmml"));
graph.connect(svm.getModel(), pmmlWriter.getModel());
// Compile and run the graph
graph.run();
}
}
Using the SVMLearner operator in RushScript
var learningColumns = ["sepal length", "sepal width", "petal length", "petal width"];
var kernel = new PolynomialKernelType().setGamma(3);
var type = new SVMTypeCSvc("class", 1);
var learner = dr.svmLearner(data, {includedColumns:learningColumns, kernelType:kernel, type:type});
Properties
The
SVMLearner operator provides the following properties.
Ports
The
SVMLearner operator provides a single input port.
The
SVMLearner operator provides a single output port.
Using the SVMPredictor Operator to Apply a Support Vector Machine Model
The
SVMPredictor operator applies a previously built Support Vector Machine model to the input data. This supports either CSVC SVMs or one-class SVMs.
We distinguish the two cases by the presence of
PMMLModelSpec.getTargetCols(). If there are zero target columns, it is assumed to be a one-class SVM. Otherwise, there must be exactly one column of type
TokenTypeConstant.STRING, in which case it is a CSVC SVM.
For CSVC SVMs, the PMML is expected to contain Support Vector Machines with
SupportVectorMachine.getTargetCategory() and
SupportVectorMachine.getAlternateTargetCategory() populated. Each of the SVMs are evaluated, adding a vote to either target category or alternate target category. The predicted value is the one that receives the most votes.
For one-class SVMs, the target category and alternate target category will be ignored. The result will either be -1 if the SVM evaluated to a number less than zero or 1 if greater than zero.
Note: This operator is non-parallel.
Code Examples
Example Usage of the SVMPredictor Operator in Java
// Create the SVM predictor operator and add it to a graph
SVMPredictor predictor = graph.add(new SVMPredictor());
// Connect the predictor to an input port and a model source
graph.connect(dataSource.getOutput(), predictor.getInput());
graph.connect(modelSource.getOutput(), predictor.getModel());
// The output of the predictor is available for downstream operators to use
Using the SVMPredictor operator in RushScript
var results = dr.svmPredictor(learner, data);
Properties
The
SVMPredictor operator has no properties.
Ports
The
SVMPredictor operator provides the following input ports.
The
SVMPredictor operator provides a single output port.
Text Processing
Text Processing within DataFlow
Text processing is the process of deriving information from unstructured text. This is accomplished by first structuring the text in a form that can be analyzed and then performing various transformations and statistical techniques on the text.
The DataFlow text processing library provides operators that can perform basic text mining and processing tasks on unstructured text. The primary operator is the TextTokenizer operator, which analyzes the text within a string field of a record and creates an object that represents a structured form of the original text. This TokenizedText object can then be used by a variety of other operators within the library to perform various transformations and statistical analysis on the text.
This section covers each of those operators and provides details on how to use them.
Text Processing Operators
Using the TextTokenizer Operator to Tokenize Text Strings
The
TextTokenizer operator tokenizes a string field in the source and produces a field containing a
TokenizedText object. The TextTokenizer operator has two main properties that determine the string field in the input that should be tokenized and the object field in the output that will store the encoded TokenizedText object. The contents of the string field will be parsed and tokenized, creating a TokenizedText object that will be encoded into the output field. This TokenizedText object can then be used by downstream operators for further text processing tasks.
Code Example
This example demonstrates using the
TextTokenizer operator to tokenize a message field in a record.
Using the TextTokenizer operator in Java
//Create a TextTokenizer operator
TextTokenizer tokenizer = graph.add(new TextTokenizer("messageField"));
tokenizer.setOutputField("messageTokens");
Using the TextTokenizer operator in JavaScript
//Create a TextTokenizer operator
var results = dr.textTokenizer(data, {inputField:"messageField", outputField:"messageTokens"});
Properties
The
TextTokenizer operator has the following properties.
Ports
The
TextTokenizer operator provides a single input port.
The
TextTokenizer operator provides a single output port.
Using the CountTokens Operator to Count Tokens
The
CountTokens operator counts the number of a particular type of token in a
TokenizedText field. The CountTokens operator has two main properties that define the input field that contains the tokenized text with tokens to count and the name of the output field that should contain the counts. By default the operator will count the number of word tokens; however, this property can be modified to count any valid
TextElementType.
Code Example
This example demonstrates using the
CountTokens operator to count the number of sentence tokens in the tokenized text field.
Using the CountTokens operator in Java
//Create a CountTokens operator
CountTokens counter = graph.add(new CountTokens("messageTokens");
counter.setOutputField("sentenceCount");
counter.setTokenType(TextElementType.SENTENCE);
Using the CountTokens operator in JavaScript
//Create a CountTokens operator
var results = dr.countTokens(data, {inputField:"messageTokens", outputField:"wordCount"});
Properties
The
CountTokens operator has the following properties.
Ports
The
CountTokens operator provides a single input port.
The
CountTokens operator provides a single output port.
Using the FilterText Operator to Filter Tokenized Text
The
FilterText operator filters a tokenized text field in the source and produces a field containing a filtered
TokenizedText object.
The FilterText operator has three properties: input field, output field, and the list of text filters that will be applied to the input. The input field must be a tokenized text object. The tokenized text object will be filtered of all tokens that are specified by the text filters. This will produce a new tokenized text object that will be encoded into the output field. If the output field is unspecified, the original input field will be overwritten with the new tokenized text object. This object can then be used for further text processing tasks.
Available Filters
LengthFilter
Filters all words with a length less than or equal to the specified length.
PunctuationFilter
Filters all standalone punctuation tokens. Will not remove punctuation that is part of a word such as an apostrophe or hyphen.
RegexFilter
Filters all words that match against the supplied regular expression.
TextElementFilter
Filters all text elements in the hierarchy that are higher than the specified element. The default hierarchy is Document, Paragraph, Sentence, Word.
WordFilter
Removes any words in a provided list.
All the available filters have the option of inverting the filter. This has the effect of keeping all the words that pass the filter instead of those that fail, and effectively inverts the output.
Code Example
This example demonstrates using the
FilterText operator to filter out XML/HTML tags and punctuation.
Using the FilterText operator in Java
//Create a FilterText operator
FilterText filter = graph.add(new FilterText("messageTokens");
filter.setOutputField("filteredTokens");
filter.setTextFilters( new PunctuationFilter(),
new RegexFilter("<(\"[^\"]*\"|'[^']*'|[^'\">])*>"));
Using the FilterText operator in JavaScript
//Create a FilterText operator
var results = dr.filterText(data, {inputField:"messageTokens", outputField:"filteredTokens",
textFilters:[new PunctuationFilter()]});
Properties
The
FilterText operator has the following properties.
Ports
The
FilterText operator provides a single input port.
The
FilterText operator provides a single output port.
Using the DictionaryFilter Operator to Filter Based on Dictionaries
The
DictionaryFilter operator filters a tokenized text field in the source based on a dictionary. This will produce a field containing a filtered
TokenizedText object in the output.
The DictionaryFilter operator has four properties: input field, output field, dictionary input field, and whether the filter should be inverted. The input field must be a tokenized text object.
The tokenized text object will be filtered of all words that are specified in the dictionary input. This will produce a new tokenized text object that will be encoded into the output field. If the output field is unspecified, the original input field will be overwritten with the new tokenized text object. This object can then be used for further text processing tasks.
Code Example
This example demonstrates using the
DictionaryFilter operator to filter out stop words.
Using the DictionaryFilter operator in Java
//Create a DictionaryFilter operator
DictionaryFilter filter = graph.add(new DictionaryFilter("messageTokens");
filter.setOutputField("filteredTokens");
filter.setDictionaryField("dictionary");
Using the DictionaryFilter operator in JavaScript
//Create a DictionaryFilter operator
var results = dr.dictionaryFilter(data, {inputField:"messageTokens",outputField:"filteredTokens",dictionaryField:"dictionary"});
Properties
The
DictionaryFilter operator has the following properties.
Ports
The
DictionaryFilter operator provides a single input port.
The
DictionaryFilter operator provides a single output port.
Using the ConvertTextCase Operator to Convert Case
The
ConvertTextCase operator performs case conversions on a tokenized text object and produces a field containing the modified tokenized text object. The operator will convert all the characters in the individual text tokens into upper- or lowercase depending on the settings and will produce a new tokenized text object with the specified case conversions applied to each token.
The ConvertTextCase operator has three properties: input field, output field, and the case used for the conversion. The input field must be a tokenized text object, and the output field will similarly be a tokenized text object. If the output field is unspecified, the original input field will be overwritten with the new tokenized text object. The new tokenized text object can then be used for further text processing tasks.
Code Example
This example demonstrates using the
ConvertTextCase operator to convert all tokens into lowercase.
Using the ConvertTextCase operator in Java
//Create a ConvertTextCase operator
ConvertTextCase converter = graph.add(new ConvertTextCase("messageTokens");
converter.setOutputField("convertedTokens");
converter.setCaseFormat(Case.LOWER);
Using the ConvertTextCase Operator in JavaScript
//Create a ConvertTextCase operator
var results = dr.convertTextCase(data, {inputField:"messageTokens", outputField:"convertedTokens", caseFormat:"LOWER"});
Properties
The
ConvertTextCase operator has the following properties.
Ports
The
ConvertTextCase operator provides a single input port.
The
ConvertTextCase operator provides a single output port.
Using the TextStemmer Operator to Stem Text
Stemming is the process for removing the commoner morphological and inflexional endings from words.
The
TextStemmer operator stems a tokenized text field in the source and produces a field containing a stemmed
TokenizedText object.
The TextStemmer operator has three properties: input field, output field, and the stemmer to use. The input field must be a tokenized text object. Each of the words in the tokenized text object will be stemmed using the rules defined by the specified stemmer algorithm. This will produce a new tokenized text object with the original words replaced by their stemmed form, which will then be encoded into the output field. If the output field is unspecified, the original input field will be overwritten with the new tokenized text object. This object can then be used for further text processing tasks.
Available Stemmers
The stemmers use the snowball stemmer algorithms to perform stemming. For more information, visit the snowball website at
http://snowball.tartarus.org/. The available stemmers are:
• Armenian
• Basque
• Catalan
• Danish
• Dutch
• English
• Finnish
• French
• German
• Hungarian
• Irish
• Italian
• Lovins
• Norwegian
• Porter
• Portuguese
• Romanian
• Russian
• Spanish
• Swedish
• Turkish
Code Example
This example demonstrates using the
TextStemmer operator to stem a text field with the Porter stemmer algorithm.
Using the TextStemmer operator in Java
//Create a TextStemmer operator
TextStemmer stemmer = graph.add(new TextStemmer("messageTokens");
stemmer.setOutputField("stemmedTokens");
stemmer.setStemmerType(StemmerType.PORTER);
Using the TextStemmer operator in JavaScript
//Create a TextStemmer operator
var results = dr.textStemmer(data, {inputField:"messageTokens", outputField:"stemmedTokens", stemmerType:"PORTER"});
Properties
The
TextStemmer operator has the following properties.
Ports
The
TextStemmer operator provides a single input port.
The
TextStemmer operator provides a single output port.
Using the ExpandTextTokens Operator to Expand Text Tokens
The
ExpandTextTokens operator can be used to expand a tokenized text field. The operator will create a new string field in the output, which it will then expand the tokenized text object into based on the token type specified, with one token per copied row. This will cause an expansion of the original input data since the rows associated with the original tokenized text object will be duplicated for every token in the output.
The ExpandTextTokens operator has three properties: input field, output field, and the
TextElementType to expand in the output. The input field must be a tokenized text object. If there are no tokens of the specified type contained in the tokenized text object, the string output field will contain null for that row.
Code Example
This example demonstrates using the
ExpandTextTokens to expand the individual words of the original text into a string field.
Using the ExpandTextTokens operator in Java
//Create an ExpandTextTokens operator
ExpandTextTokens expander = graph.add(new ExpandTextTokens("messageTokens");
expander.setOutputField("words");
expander.setTokenType(TextElementType.WORD);
Using the ExpandTextTokens operator in JavaScript
//Create an ExpandTextTokens operator
var results = dr.expandTextTokens(data, {inputField:"messageTokens", outputField:"sentences", tokenType:"SENTENCE"});
Properties
The
ExpandTextTokens operator has the following properties.
Ports
The
ExpandTextTokens operator provides a single input port.
The
ExpandTextTokens operator provides a single output port.
Using the CalculateWordFrequency Operator to Calculate Word Frequencies
The
CalculateWordFrequency operator determines the frequencies of each word in a
TokenizedText field. The
CalculateWordFrequency operator has two main properties that define the input field that contains the tokenized text, and the output field for the frequency map
The operator will output a
WordMap object that contains the words and their associated frequencies. This object can then be used by other operators such as
Using the TextFrequencyFilter Operator to Filter Frequencies or
Using the ExpandTextFrequency Operator to Expand Text Frequencies.
Code Example
This example demonstrates using the
CalculateWordFrequency operator to determine the frequency of each word in the tokenized text field.
Using the CalculateWordFrequency operator in Java
//Create a CalculateWordFrequency operator
CalculateWordFrequency freqCalc = graph.add(new CalculateWordFrequency("messageTokens");
freqCalc.setOutputField("wordsFrequencies");
Using the CalculateWordFrequency Operator in JavaScript
//Create a CalculateWordFrequency operator
var results = dr.calculateWordFrequency(data, {inputField:"messageTokens", outputField:"wordFrequencies"});
Properties
The
CalculateWordFrequency operator has the following properties.
Ports
The
CalculateWordFrequency operator provides a single input port.
The
CalculateWordFrequency operator provides a single output port.
Using the CalculateNGramFrequency Operator to Calculate N-gram Frequencies
The
CalculateNGramFrequency operator determines the frequencies of each n-gram in a
TokenizedText field. The CalculateNGramFrequency operator has three main properties which define the input field that contains the tokenized text, the output field for the frequency map, and the n that will be used by the calculation. The operator will output an
NGramMap object that contains the n-grams and their associated frequencies.
Code Example
This example demonstrates using the
CalculateNGramFrequency operator to determine the frequency of each bigram in the tokenized text field.
Using the CalculateNGramFrequency operator in Java
//Create a CalculateNGramFrequency operator
CalculateNGramFrequency freqCalc = graph.add(new CalculateNGramFrequency("messageTokens");
freqCalc.setOutputField("ngramFrequencies");
freqCalc.setN(2);
Using the CalculateNGramFrequency operator in JavaScript
//Create a CalculateNGramFrequency operator
var results = dr.calculateNGramFrequency(data, {inputField:"messageTokens", outputField:"ngramFrequencies"});
Properties
The
CalculateNGramFrequency operator has the following properties.
Ports
The
CalculateNGramFrequency operator provides a single input port.
The
CalculateNGramFrequency operator provides a single output port.
Using the TextFrequencyFilter Operator to Filter Frequencies
The
TextFrequencyFilter operator filters a list of frequencies produced by the
CalculateWordFrequency or
CalculateNGramFrequency operators.
The operator has several properties that must be set to determine the behavior of the filter. The input field for the frequency maps must be set. Additionally a minimum or maximum threshold may be set for the frequencies. This will cause the filter to only keep those absolute frequencies between the minimum or maximum threshold inclusively. Also the total number of top frequencies to keep may be set. This will be applied after determining if the frequencies are within the threshold. Therefore if fewer than the specified number of total frequencies are available, they will all be included in the output.
Any combination of these filtering methods may be applied to the frequencies. If an output field for the filtered frequency maps is unspecified, the original field will be overwritten in the output.
Code Example
This example demonstrates using the
TextFrequencyFilter operator to filter all the absolute frequencies below two and keeps the top ten frequencies.
Using the TextFrequencyFilter operator in Java
//Create a TextFrequencyFilter operator
TextFrequencyFilter filter = graph.add(new TextFrequencyFilter("FrequencyMap");
filter.setOutputField("filteredFrequencies");
filter.setMinThreshold(2);
filter.setTotalNumber(10);
Using the TextFrequencyFilter operator in JavaScript
//Create a TextFrequencyFilter operator
var results = dr.textFrequencyFilter (data,{inputField:"FrequencyMap", outputField:"filteredFrequencies", minThreshold:2, totalNumber:10});
Properties
The
TextFrequencyFilter has the following properties.
Ports
The
TextFrequencyFilter provides a single input port.
The
TextFrequencyFilter provides a single output port
Using the ExpandTextFrequency Operator to Expand Text Frequencies
The
ExpandTextFrequency operator expands a frequency map produced by the
CalculateWordFrequency or
CalculateNGramFrequency operators. If either output field is unspecified the operator will only include the specified output fields in the output. This can be useful if only the text elements or frequencies are needed.
As expected, this operator will cause an expansion of the original input data, and any fields that are not directly expanded will simply be copied. If the row does not have a frequency map to expand, the row will simply be copied into the output with a null indicator inserted into the new fields.
The output of the frequencies can additionally be controlled by setting whether the operator should output relative or absolute frequencies.
Code Example
This example demonstrates using the
ExpandTextFrequency operator to expand the word frequencies in the record.
Using the ExpandTextFrequency operator in Java
//Create an ExpandTextFrequency operator
ExpandTextFrequency expander = graph.add(new ExpandTextFrequency("frequencyMap");
expander.setTextOutputField("words");
expander.setFreqOutputField("frequencies");
Using the ExpandTextFrequency operator in JavaScript
//Create an ExpandTextFrequency operator
var results = dr.expandTextFrequency(data, {inputField:"frequencyMap", textOutputField:"words", freqOutputField:"frequencies"});
Properties
The
ExpandTextFrequency operator has the following properties.
Ports
The
ExpandTextFrequency operator provides a single input port.
The
ExpandTextFrequency operator provides a single output port.
Using the GenerateBagOfWords Operator to Expand Text Frequencies
The
GenerateBagOfWords operator can be used to determine all of the distinct words in a
TokenizedText field. The GenerateBagOfWords operator has two main properties that define the input field containing the tokenized text and the output field for the words.
Code Example
This example demonstrates using the
GenerateBagOfWords operator to determine the frequency of each word in the tokenized text field.
Using the CalculateWordFrequency operator in Java
//Create a GenerateBagOfWords operator
GenerateBagOfWords bow = graph.add(new GenerateBagOfWords("messageTokens");
bow.setOutputField("words");
Using the CalculateWordFrequency operator in JavaScript
//Create a GenerateBagOfWords operator
var results = dr.generateBagOfWords(data, {inputField:"messageTokens", outputField:"words"});
Properties
The
GenerateBagOfWords operator has the following properties.
Ports
The
GenerateBagOfWords operator provides a single input port.
The
GenerateBagOfWords operator provides a single output port.
Using the DrawDiagnosticsChart Operator to Draw Diagnostic Charts
To build diagnostic charts, the
DrawDiagnosticsChart operator uses confidence values along with the actual target values (true class).
Note: These values are obtained using the input of this operator and output of one or multiple predictors.
The supported chart types are:
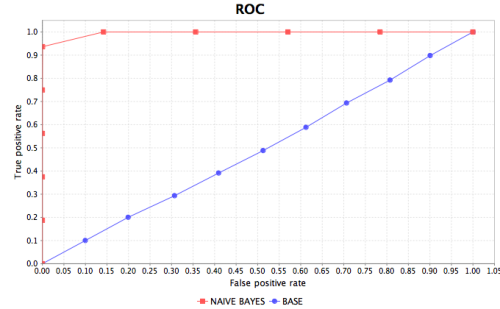
ROC chart
Provides a comparison between the true positive rate (y-axis) and false positive rate (x-axis) when the confidence threshold decreases.
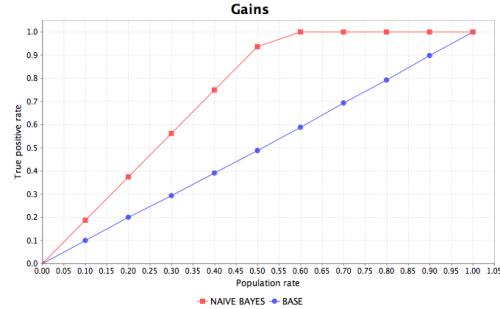
Gains chart (CRC, Cumulative Response Chart)
Provides the change in true positive rate (y-axis) when the percentage of the targeted population (x-axis) decreases.
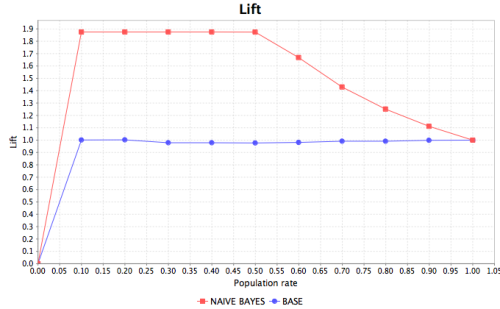
Lift chart
Provides the change in lift (y-axis) which is the ratio between predictor result and baseline when the percentage of the targeted population (x-axis) increases.
The true positive rate is the ratio of all correct positive classifications and total number of positive samples in the test set. The false positive rate is the ratio of all incorrect positive classifications and total number of negative samples in the test set.
The
DrawDiagnosticsChart operator can accept one to five predictor operators as input sources. Each predictor output must contain a column for the actual target values and confidence values (probability, score) assigned by the given predictor.
Note: This operator is not parallelizable and runs on a single node in cluster mode.
Output Chart
The following images are examples for the chart types.
Code Example
Using the DrawDiagnosticsChart operator in Java
// Create a diagnostics chart drawer with two input ports
DrawDiagnosticsChart drawer = new DrawDiagnosticsChart(2);
drawer.setConfidenceFieldNames(Arrays.asList("NaiveBayesConfidence", "BaseConfidence"));
drawer.setTargetFieldNames(Arrays.asList("target", "target"));
drawer.setChartNames(Arrays.asList("NAIVE BAYES", "BASE"));
drawer.setChartType(ChartType.GAINS);
drawer.setResultSize(10);
drawer.setTargetValue("E");
drawer.setOutputPath("chart.png");
graph.connect(bayesPredictor.getOutput(), drawer.getInput(0));
graph.connect(basePredictor.getOutput(), drawer.getInput(1));
Using the DrawDiagnosticsChart operator in RushScript
// Using default settings: five (optional) input ports, values for disconnected ports as nulls.
var drawer = dr.drawDiagnosticsChart("chart", bayesPredictor, null, basePredictor, null, null, {
confidenceFieldNames: ["NaiveBayesConfidence", null, "BaseConfidence", null, null],
targetFieldNames: ["target", null, "target", null, null],
chartNames: ["NAIVE BAYES", null, "BASE", null, null],
outputPath: "chart.png",
chartType: com.pervasive.datarush.analytics.viz.ChartType.GAINS,
resultSize: 10,
targetValue: "E"
});
Properties
The
DrawDiagnosticsChart operator provides the following properties.
Ports
The
DrawDiagnosticsChart operator provides an arbitrary number of input ports. It is configured using constructor arguments. The default setting is five input ports. Only port 0 is mandatory.
The
DrawDiagnosticsChart operator provides a single output port.