Copy Statement
The copy statement copies the contents of a table to a data file (copy into) or copies the contents of a file to a table (copy from). For more information on the copy statement, see Populating Tables in the Ingres Database Administrator Guide.
This statement has the following syntax:
copy [table] [schema.]table_name
([column_name = format [with null [(value)]]
{, column_name = format [with null [(value)]]}])
into | from | append 'filename[, type]'
[with_clause];
([column_name = format [with null [(value)]]
{, column_name = format [with null [(value)]]}])
into | from | append 'filename[, type]'
[with_clause];
Parameters--Copy Statement
This statement has the following parameters:
table_name
Specifies an existing table from which data is read or to which data is written.
column_name
Specifies the column from which data is read or to which data is written.
format
Specifies the format in which a value is stored in the file.
filename
Specifies the file from which data is read or to which data is written. When using append, you must ensure that the format of the existing content in filename matches the format generated by the copy append command.
type
(Optional) Specifies the file translation type (see Windows File Types for Copy): T or B.
A space after the comma or at the end of the filename causes the name to be taken literally, rather than interpreting a filetype. If a filename ends in a space, Windows removes the trailing spaces so that they do not appear in the actual file name.
with_clause
Consists of the word with, followed by a comma-separated list of one or more of the following items:
• on_error = TERMINATE | CONTINUE
• error_count = n
• rollback = ENABLED | DISABLED
• log = 'filename'
The following options are valid for bulk copy operations only. For details about these settings, see Modify Statement. The value specified for any of these options becomes the new setting for the table and overrides any previously made settings (either using the modify statement or during a previous copy operation).
• allocation = n
• extend = n
• fillfactor = n (ISAM, Hash, and Btree only)
• minpages = n (Hash only)
• maxpages = n (Hash only)
• leaffill = n (Btree only)
• nonleaffill = n (Btree only)
• row_estimate = n
Unformatted Copying
To copy all rows of a table to a file with no conversion or formatting, omit the column list from the copy statement. This operation is referred to as an unformatted copy.
For example, to copy the entire employee table into the file, emp_name, issue the following statement:
copy table employee () into 'emp_name';
Parentheses must be included in the statement, even though no columns are listed. The resulting binary file contains data stored in column binary formats. To load data from a file that was created by an unformatted copy into, use an unformatted copy from.
Note: An unformatted copy (whether using copy, copydb, or unloaddb) is not portable across platforms due to the endianness of the binary data.
Formatted Copying
Formatted copying allows the type, number, and order of columns in the data file to differ from the table. By specifying a list of columns and their types in the copy statement, you instruct Ingres to perform a formatted copy. The copy statement list specifies the order and type of columns in the data file. Ingres uses the column names in the list to match up file data with the corresponding columns in the table.
For human readable text data files, the copy list formats will almost always be a character type: char, c, text, or less commonly varchar or byte. The copy statement converts (character) file data into table data types for copy from, or the reverse for copy into. The copy list may contain other types as well, such as integer or decimal, but these are binary types for special programming situations; they are not human readable types. Copy also supports a "dummy" type, used to skip input data (from) or insert fixed output text (into).
If some table columns are not listed in the copy list for a copy from, those columns are defaulted. (If they are defined in the table as not default, an error occurs.) If some table columns are not listed for a copy into, those table columns simply do not appear in the output data file.
The order of columns in the table need not match the order in the data file. Remember that the order of columns in the copy list reflects the order in the data file, not the order in the table. Additionally, a table column may be named more than once. (For copy from, if a column is named multiple times, the last occurrence in the copy list is the one that is stored into the table. Earlier occurrences undergo format conversion, but the result is discarded.)
Special restriction: If the table includes one or more long columns (such as long varchar or long byte), columns cannot be reordered across any long column. For example, if the table contains (int a, int b, long varchar c), a copy statement could use the order (b,a,c); but a copy statement asking for (a,c,b) would be illegal (you cannot move column b to occur after the long column c).
The values in the data file can be fixed-length, or variable-length. Values can optionally be ended with a delimiter (see Delimiters in the Data File); the delimiter is specified in the copy list. copy can also process a special case of delimited values, the comma separated values (CSV) delimiting form.
Note: If II_DECIMAL is set to comma, you must follow any comma required in SQL syntax (such as a fixed-length copy type) by a space. For example:
copy table t (col1=c20, col2=c30, d0=nl) into ‘t.out’:
Bulk Copying
To improve performance when loading data from a file into a table, use a bulk copy. Bulk copy is possible for either formatted or unformatted copies.
The requirements for performing a bulk copy are:
• The table is not journaled
• The table has no secondary indexes
• For storage structures other than heap, the table is empty and occupies fewer than 18 pages
If the DBMS Server determines that all these requirements are met, the data is loaded using bulk copy. If the requirements are not met, data is loaded using a less rapid technique. For detailed information about bulk copying, see the Ingres Database Administrator Guide.
To specify the estimated number of rows to be copied from a file to a table during a bulk copy operation, use with row_estimate (see Row_estimate).
Column Formats for Copy
The following sections describe how to specify the data file format for table columns. The format specifies how each is written and delimited in the data file.
Note: When copying to or from a table that includes long varchar or long byte columns, specify the columns in the order they appear in the table.
Character (Text) Formats
The character formats are the ones most commonly used to read and write ordinary text (human-readable) data files.
The basic character formats are byte, c, char, and text. Each has a variable-length form and a fixed-length form. The variable-length forms are byte(0), c0, char(0), and text(0). The fixed-length forms are byte(n), Cn, char(n), and text(n). An optional delim may follow to specify a delimiter.
The subtle differences between the various character formats are described in Copy Format Details.
Counted Character Formats
The byte varying, long byte, long varchar, long nvarchar, nvarchar(n), and varchar formats are "counted" formats: each data file value is preceded by a character count. The character count defines the length of the data value; the actual field length as defined by a fixed-length specifier or a delimiter may be larger. On input (copy from), extra field characters beyond those included by the embedded character count are ignored. On output (copy into), any extra field length after the actual value is filled with padding, as defined by the specific format.
The fixed-length forms are byte varying(n), nvarchar(n), and varchar(n). The variable-length forms are byte varying(0), long byte(0), long varchar(0), long nvarchar(0), and varchar(0). An optional delim may follow to specify a delimiter.
Note: Nvarchar(0) is not a counted format.
For all fixed-length counted formats: the field length N does not include the preceding length specifier. For example, a varchar(1) field takes 6 bytes. When reading data (copy from), if the character count found in the data is larger than the defined length, a runtime conversion warning is issued and the row is not loaded.
These counted formats are the only ones that can be used with long table columns. The two long formats can only be used with long byte or long varchar table columns. See Copy Format Details.
Dummy Format
The D (dummy) format describes a data file column that does not map to any table column. On input (copy from), a D format column describes file data to be skipped and discarded. On output (copy into), a D format column describes constant data to be sent to the data file.
The column name given for any dummy column is not matched to any table column. The Dn form for copy into uses the column name as the value to output; all other uses of the dummy format ignore the column name completely.
Unicode Formats
The Unicode formats are nchar, nvarchar, and long nvarchar and they can only be used with nchar or nvarchar table columns. Fixed-length forms are nchar(n) and nvarchar(n). Variable-length forms are nchar(0), nvarchar(0), and long nvarchar(0).
Fixed-length nchar(n) and nvarchar(n) formats read and write using the two-byte UCS-2 encoding. The variable-length nchar(0), nvarchar(0), and long nvarchar(0) forms read and write using the variable-length UTF8 encoding.
The field length n for nchar(n) and nvarchar(n) should be specified as character lengths, not byte (octet) lengths. However, the embedded length specifier used by the nchar(0) and nvarchar(0) formats should give the number of bytes, not characters. (The reason is that nchar(0) and nvarchar(0) use the UTF8 encoding, which encodes Unicode code points into a variable number of bytes. Copy needs the byte count to know how many bytes to read and decode from UTF8.)
Binary Formats
The formatted copy statement supports binary formats that match the binary types used to store data in tables. These are the boolean, date, decimal, float, integer, and money formats (and size variants such as bigint, smallint, real, and so on). Most data files are text, not binary, so these binary formats are not often needed.
Copy Format Details
This section describes specifying the format of fields in the data file. When specifying data file formats for copy into, be aware of the following points:
• Data from numeric columns, when written to text fields in the data file, is right-justified and filled with blanks on the left.
• When a copy into statement is issued in the Terminal Monitor, the -i and -f command line flags control the format used to convert floating-point table data into text-type file data. To avoid rounding of large floating point values, use the sql command -f flag to specify a floating point format that correctly accommodates the largest value to be copied. For information about the -i and -f flags, see the sql command description in the Ingres Command Reference Guide.
• The copy into section often uses the phrase "the display length of the corresponding table column". This means the length of the table column when formatted as a character string. This will be a standard length based on the table column type, and is independent of the actual column value. For example: the display length of an integer column is 13, the display length of a smallint column is 6, and so on.
The following table explains the details for the various copy list formats. Unless otherwise noted, all non-binary formats can be followed by an optional delim to specify a delimiter (see Delimiters in the Data File).
Format | How Stored (copy into) | How Read (copy from) |
|---|---|---|
boolean | Written as a single byte Boolean value (0=FALSE, 1=TRUE). (A binary format) | Same format as copy into |
byte(0) | Same as byte(n) where n is the display length of the corresponding table column. | Read as variable-length binary data terminated by the specified delimiter. If a delimiter is not specified, the first comma, tab, or newline encountered ends the value. |
byte(n) where n is 1 to the maximum row size configured, not exceeding 32,000. | Written as a fixed-length byte string. Exactly n bytes are written, padded with zeros if necessary. If given, the delimiter is written after the value and padding. | Read as a fixed-length byte string; exactly n bytes are read. If a delimiter is specified, one additional character is read and discarded. |
byte varying(0) | Same as byte varying(n) where n is the display length of the table column. | Read as a variable-length byte string, preceded by a 5‑character, right‑justified length specifier. If a delimiter is specified, additional input is discarded until the delimiter is found. |
byte varying(n) where n is 1 to the maximum row size configured, not exceeding 32,000. | Written as a fixed-length byte string preceded by a 5-character, right-justified length specifier. If necessary, the field is padded with zeros to the specified length. If given, the delimiter is written after the value and padding. | Read as a fixed-length byte string, preceded by a 5-character, right-justified length specifier. If a delimiter is specified, one additional character is read and discarded. |
C0 | Same as Cn where n is the display length of the corresponding table column | Read as a variable-length string, terminated by the specified delimiter. If a delimiter is not specified, the first comma, tab, or newline encountered ends the value. Any control characters or tabs in the input are converted to spaces. C0 format supports \. The \ is discarded, and the next character is taken literally as part of the value (even if it would normally be the delimiter). To read a \ character, use \\. |
Cn | Written as a fixed-length string, padded with blanks if necessary. Any "non-printing" character (meaning a control character or tab) is converted to a space. If given, the delimiter is written after the value and padding. | Read as a fixed-length string. If a delimiter is specified, one additional character is read and discarded. Any control characters or tabs in the input are converted to spaces. Fixed-length Cn format does not support \. |
char(0) | Same as char(n) where n is the display length of the corresponding table column. | Read as a variable-length string terminated by the specified delimiter. If a delimiter is not specified, the first comma, tab, or newline encountered ends the value. Unlike C format, char does not support \. char also does not convert control characters or tabs. File data is read as is. |
char(n) where n is 1 to the maximum row size configured, not exceeding 32,000 (16,000 in a UTF8 instance). | Written as a fixed-length string, padded with blanks if necessary. If given, the delimiter is written after the value and padding. Unlike C format, char does not do any conversion of control characters or tabs. Table data is output as-is. | Read as a fixed-length string. If a delimiter is specified, one additional character is read and discarded. Unlike C format, char does not convert control characters or tabs. File data is read as is. |
D0 | Instead of placing a value in the file, copy writes the specified delimiter. (Unlike the Dn format, D0 format does not write the column name.) Copy into requires that a delimiter be specified; D0 with no delimiter is not allowed. | Dummy field. Characters are read and discarded until the specified delimiter is encountered. If a delimiter is not specified, the first comma, tab, or newline ends the value. Any \ found in the input means that the next character is to be taken literally, and is not a delimiter. |
Dn | Dummy column. Instead of placing a value in the file, copy writes the name of the column n times. For example, if you specify x=D1, the column name, x, is written once; if you specify x=D3, copy writes xxx (the column name, three times), and so on. You can specify a delimiter as a column name, for example, NL=D1. | Dummy field. N characters are read and discarded. Copy from does not allow a delimiter specification with a fixed-length dummy field. |
date | Written as a date. (A binary format) | Read as a date. (A binary format) |
decimal | Written as a decimal number. (A binary format.) | Read as a decimal number. (A binary format) |
float | Written as double‑precision floating point. (A binary format) | Read as double‑precision floating point. (A binary format) |
float4 | Written as single‑precision floating point. (A binary format) | Read as single‑precision floating point. (A binary format) |
integer | Written as integer of 4‑byte length. (A binary format) | Read as integer of 4‑byte length. (A binary format) |
integer1 | Written as integer of 1‑byte length. (A binary format) | Read as integer of 1‑byte length. (A binary format) |
long byte(0) | Identical to long varchar | Identical to long varchar |
long nvarchar(0) | Written in segments. Each segment is composed of an integer specifying the length of the segment, followed by a space and the specified number of bytes in UTF-8 encoding. After the last data segment, a final zero-length segment is written (that is, 0 followed by a space). The maximum segment size for the long nvarchar segment is 32727 bytes. The UTF-8 encoded long nvarchar data segments are similar to long varchar data segments. See the description for long varchar(0) for an example of the encoded data segment. If a delimiter is specified, it is written immediately following the last segment. | Read under the same format as copy into. If a delimiter is specified, one character is read and discarded after the data value is read. |
long varchar(0) | Written in segments. Each segment is composed of an integer specifying the length of the segment, followed by a space and the specified number of characters. After the last data segment, a final zero-length segment is written (that is, 0 followed by a space). If a delimiter is specified, it is written immediately following the last segment. The maximum segment length is 32767. The following example shows two data segments, followed by the termination zero length segment. The first segment is 5 characters long, the second segment is 10 characters long, and the termination segment is 0 character long: 5 abcde10 abcdefghij 0 (with a space after the terminating 0 character) (In this example, the data that is in the originating table column is abcdeabcdefghij) | Read under the same format as copy into. If a delimiter is specified, one character is read and discarded after the data value is read. |
money | Written as a scaled floating point value (a money value). (A binary format) | Read as a scaled floating-point values (a money value). (A binary format) |
nchar(0) | Written as a Unicode string in UTF-8 encoding, preceded by a 5-character, right-justified byte count. The exact length of the column value is written, without padding. If a delimiter is specified, it is written after the value. | Read as a Unicode string in UTF-8 encoding, preceded by a 5-character, right-justified length specifier. (The length is a byte count, not a character count). If a delimiter is specified, additional input is discarded until the delimiter is encountered. |
nvarchar(0) | Same as nchar(0) | Same as nchar(0) |
nchar(n) | Written as a fixed-length Unicode string in UCS-2 encoding. N is the length in characters, not bytes. The value is padded to the specified length with UCS-2 blanks, if necessary. If a delimiter is specified, it is written after the value and padding. | Read using the same format as copy into. If a delimiter is specified, after the value is read, one additional character is read and discarded. |
nvarchar(n) | Written as a 2-byte binary integer length specifier, followed by that many Unicode characters using UCS-2 encoding. The value is padded if necessary to the field length n; the padding content is undefined. If a delimiter is specified, it is written after the value and padding. The byte length of the written value excluding delimiter is 2n+2; the length n is in characters, not bytes, and does not include the initial length specifier. | Read using the same format as copy into. If a delimiter is specified, after the value is read, one additional character is read and discarded. |
smallint | Written as an integer of 2‑byte length. (A binary format.) | Read as integer of 2‑byte length. (A binary format) |
text(0) | Written as a variable length string. If a delimiter is specified, it is written after the value. If the originating column is C, char, or nchar, trailing blanks are trimmed. If the originating column is text, varchar, or nvarchar, the column value is output exactly as-is (no padding, no trimming). If the originating column is a non-character, writes the result of converting the value to a character string, as-is with no padding. Copy into using text(0) format is the way to get variable width output with no padding. | Read as variable-length character string terminated by the specified delimiter. If a delimiter is not specified, the first comma, tab, or newline encountered ends the value |
text(n) | Written as a fixed-length string. The value is padded with null bytes (zeros) if necessary. If specified, the delimiter is written after the value and padding. | Reads a fixed-length field n characters wide; however if one of those characters is a null byte, the value stored into the table is terminated at that null byte. If a delimiter is specified, one additional character is read and discarded. |
varchar(0) | Same as varchar(n), where n is the display length of the corresponding table column. | Read as a variable-length string, preceded by a 5‑character, right-justified length specifier. If a delimiter is specified, additional input is discarded until the delimiter is found. |
varchar(n) where n is 1 to the maximum row size configured, not exceeding 32,000 (16,000 in a UTF8 instance). | Written as a fixed-length string preceded by a 5-character, right‑justified length specifier. If necessary, the value is padded with null characters to the specified length. | Read as a fixed-length string, preceded by a 5-character, right-justified length specifier. If a delimiter is specified, one additional character is read and discarded. |
Note: The dummy format (dn) behaves differently for copy from and copy into. When a table is copied into a file, n specifies the number of times the column name is repeated. When copying from a file to a table, n specifies the number of bytes to skip.
For user-defined data types (UDTs), use char or varchar.
Delimiters in the Data File
Delimiters are characters in the data file that separate fields and mark the end of records. Valid delimiters are listed in the following table:
Delimiter | Description |
|---|---|
nl | Newline character |
tab | Tab character |
sp | Space |
csv | Comma separated values |
ssv | Semicolon separated values |
nul or null | Null/zero character |
comma | Comma |
colon | Colon |
dash | Dash |
lparen | Left parenthesis |
rparen | Right parenthesis |
X | Any non-numeric character |
When a single character is specified as the delimiter, enclose that character in quotes. If the data type specification is C or D, the quotes must enclose the entire format. For example, 'd0%' specifies a dummy column delimited by a percent sign (%). If the data type specification uses parentheses around the length, quote only the delimiter. For example, char(0)'%' specifies a char field delimited by a percent sign.
Be careful using the sp (space) or null delimiters, especially with copy from. Spaces or nulls are used as padding characters by many of the copy formats. If a pad character is improperly treated as a delimiter, the copy from will get out of sync with the input, eventually producing an error. When designing a data file format, use delimiters that will not appear in the data or padding, or use CSV or SSV forms.
CSV and SSV Delimiters
The CSV and SSV delimiters allow copy to read and write files that contain comma separated values (CSV).
The rules for a CSV-delimited field are:
• The field is delimited by a comma, unless it is the last CSV-delimited field in the copy list and all following fields are dummy fields; in that case, the field is delimited by a newline.
• Copy from: If the first non-blank character in the field is a double quote ("), the field extends until a closing double quote. Commas or newlines inside the quoted string are not delimiters and do not end the value. If a doubled double quote ("") is seen while looking for the closing quote, it is translated to one double quote and the value continues. For example, the data file value:
“There is a double quote “” here”
is translated to the table value:
There is a double quote “ here
Whitespace before the opening double quote, or between the closing double quote and the delimiter (comma or newline), is not part of the value and is discarded.
• Copy into: If the value to be written contains a comma, newline, or double quote, it is written enclosed in double quotes using quote doubling as described in the previous bullet item. If the value does not contain a comma, newline, or double quote, it is written as is.
The SSV delimiter works exactly the same as the CSV delimiter, with semicolon in place of comma.
CSV and SSV delimiters are only allowed with byte(0), C0, char(0), and text(0). They are not allowed with the “counted” formats (varchar(0) and so on); the count defines the value exactly and there is no need for quoting. (If delimiting is desired, use the comma or nl delimiters on counted formats.)
Copy from: Some CSV file variants use quote escaping (\") instead of quote doubling ("") to indicate a quote inside a quoted string. The C format handles\- escaping, so use the C0CSV format and delimiter to handle this type of file. (CSV with copy into always writes quote doubling—never quote escaping—when needed.)
With Null Clause for Copy
The with null clause allows the data file to contain null data. There are two methods of indicating a null: an indicator byte (no value given), or a special user-defined marker value. The indicator byte method does not depend on a particular marker value, but it is a binary form not suited to human readable text files. Also, the indicator byte method is not available for variable-length data fields. The user-defined marker value method works with any file format, but depends on a user chosen value that must not otherwise appear in the data.
With Null (value) Clause
When copying data from a table to a file, the with null (value) clause directs copy to put the specified value in the file when a null is detected in the corresponding column. If a null is detected and there is no with null clause, a runtime error occurs, and aborts the copy statement.
When copying data from a file to a table, the with null (value) clause specifies a marker value to be interpreted as a null. When copy encounters this value in the file, it writes a null to the corresponding table column. The table column must be nullable; if it is not, a runtime error occurs, and aborts the copy statement.
To prevent conflicts between valid data and null entries, choose a value that does not occur as part of the data in your table. The value chosen to represent nulls must be compatible with the format of the field in the file: character formats require quoted values, and binary numeric formats require unquoted numeric values.
For example, this example of a value is incorrect:
c0comma with null(0)
because the value specified for nulls (numeric zero) conflicts with the character data type of the field. However, this example is correct:
c0comma with null('0')
because the null value is character data, specified in quotes, and does not conflict with the data type of the field. Do not use the keyword null, quoted or unquoted, for a numeric format.
When copying from a table to a file, be sure that the specified field format is at least as large as the value specified for the with null clause. If the column format is too small, the DBMS Server truncates the null value written to the data file to fit the specified format.
For example, in the following statement the string, 'NULL,' is truncated to 'N' because the format is incorrectly specified as one character:
copy table t1 (col1 = char(1) with null ('NULL')) into 't1.dat';
The correct version specifies a 4-character format for the column.
copy table t1 (col1 = char(4) with null ('NULL')) into 't1.dat';
With Null Clause Omitting Value
If with null is specified but value is omitted, copy uses a trailing indicator byte in the file to determine whether a file value is a null. Copy into writes a zero trailing byte if the value is not null; it writes a nonzero trailing byte to indicate a null. (The value written prior to the indicator byte is undefined if the indicator shows null.) Copy from reads and interprets a trailing indicator byte in the same manner, zero for not null and nonzero for null. Indicator bytes are not allowed for variable-length formats such as char(0); variable-length formats must specify a value clause.
Filename Specification for Copy
Filename must be enclosed in single quotation marks; the file specification can include a directory/path name. For copy into, if the file does not exist, copy creates the file.
UNIX: For copy into, if the file already exists, copy overwrites it.
Windows File Types for Copy
File type can be specified using the optional type parameter. Type must be either T for text, or B for binary.
The traditional Windows newline indicator is a CR-LF pair (carriage return / linefeed). The newline indicator on other operating systems (such as UNIX) is a single linefeed with no carriage return. Windows uses the file type to control translation between Windows and UNIX style newline indicators, as well as control-Z translation.
A file in binary type mode reads or writes the data exactly as is, with no translation. A file in text type mode translates a single LF to CR-LF when writing. When reading a file in text mode, CR-LF pairs are read as single LF's, and if a control-Z occurs in the data file, end-of-file is returned and Windows stops reading data from that file.
By default, Ingres uses text mode for copy into and copy from only if all of the listed field formats are character types (c, char, text, varchar, or dummy). Otherwise, binary mode is used.
The binary-copy forms (copy () from or copy () into) use binary mode.
Note: Unicode formats (nchar, nvarchar), long varchar format, and the byte formats cause binary mode to be used by default.
Copy from recognizes CR-LF as a newline (nl) delimiter even if the input file is read in binary type mode. (This is true on non-Windows systems too, so that data files that were created by Windows applications can be read.)
For situations where the default file type choice is inappropriate, the file type can be specified explicitly. For example, if copy into is creating a file to be read on a UNIX system, a file type of B (Binary) is appropriate. The resulting file will contain UNIX-style newlines (single linefeeds) instead of Windows-style newlines.
With Clause for Copy
Valid with clause options for the copy statement are as follows:
On_error=TERMINATE|CONTINUE
on_error = TERMINATE | CONTINUE
Directs copy to continue after encountering conversion errors.
To direct copy to continue until a specified number of conversion errors have occurred, specify the error_count option instead.
By default, copy terminates when an error occurs while converting between table format and file format
When on_error is set to CONTINUE, copy displays a warning whenever a conversion error occurs, skips the row that caused the error, and continues processing the remaining rows. At the end of the processing, copy displays a message that indicates how many warnings were issued and how many rows were successfully copied.
Setting on_error to CONTINUE does not affect how copy responds to errors other than conversion errors. Any other error, such as an error writing the file, terminates the copy operation.
Error_count=n
error_count = n
Specifies how many errors can occur before processing terminates.
Default: 1.
If on_error is set to continue, setting error_count has no effect.
Log='filename'
log = 'filename'
Stores to a file any rows that copy cannot process. This option can be used only if on_error CONTINUE is specified. When specified with log, copy places any rows that it cannot process into the specified log file. For copy into, the logged rows are in database (binary) format; for copy from, the logged rows are in file format.
Logging works as follows:
Windows: Copy opens the log file prior to the start of data transfer. If it cannot open the log file, copy halts. If an error occurs when writing to the log file, copy issues a warning, but continues. If the specified log file already exists, it is overwritten with the new values (or truncated if the copy operation encounters no bad rows).
UNIX: Copy opens the log file prior to the start of data transfer. If it cannot open the log file, copy halts. If an error occurs when writing to the log file, copy issues a warning, but continues. If the specified log file already exists, it is overwritten with the new values (or truncated if the copy operation encounters no bad rows).
The log option is not available if the table contains any long columns, whether they are part of the copy list or not.
If copying from a data file that contains duplicate rows (or rows that duplicate rows already in the table) to a table that was created with noduplicates and has a HASH, ISAM or BTREE storage structure, copy displays a warning message and does not add the duplicate rows. If the with log option is specified, copy does not write the duplicate rows to the log file.
If copying from a data file that contains duplicate keys (or keys that duplicate keys already in the table) to a table that enforces the unique key, copy displays a warning message and does not add the rows containing the duplicate keys. This operation is sequential so that the first row is copied to the table and a second row with the same key fails.
Rollback=ENABLED|DISABLED
rollback = ENABLED | DISABLED
Enables or disables rollback, as follows:
ENABLED
Directs the DBMS Server to back out all rows appended by the copy if the copy is terminated due to an error.
DISABLED
Retains the appended rows.
The rollback=DISABLED option does not mean that the copy cannot be rolled back. Database server errors that indicate data corruption will always roll back the copy statement. In addition, the user may decide to rollback the entire transaction rather than committing it with a commit.
Default: ENABLED
When copying to a file, the with rollback clause has no effect.
Row_estimate
row_estimate
Specifies the estimated number of rows to be copied from a file to a table during a bulk copy operation. The DBMS Server uses the specified value to allocate memory for sorting rows before inserting them into the table. An accurate estimate can enhance the performance of the copy operation.
The estimated number of rows must be no less than 0 and no greater than 2,147,483,647. If this parameter is omitted, the default value is 0, in which case the DBMS Server makes its own estimates for disk and memory requirements.
Permissions
To use the copy statement, one of the following must apply:
• You own the table.
• The table has select (for copy into) or insert (for copy from) privilege granted to PUBLIC.
• You have been granted COPY_INTO (for copy into) or COPY_FROM (for copy from) privileges on the table.
Locking
• When copying from a table into a file, the DBMS Server takes a shared lock on the table.
• When performing a bulk copy into a table, the DBMS Server takes an exclusive lock on the table. Because bulk copy cannot start until it gets an exclusive lock, this operation can be delayed due to lock contention.
• When performing a non-bulk copy into a table, the DBMS server takes an “intent exclusive” lock on the table, and uses insert to update the table. As a result, the operation can be aborted due to deadlock.
Restrictions and Considerations
Copy cannot be used to add data to a view, index, or system catalog.
When copying data into a table, copy ignores any integrity constraints defined (using the create integrity statement (see Create Integrity Statement)) against the table.
When copying data into a table, copy ignores ANSI/ISO Entry SQL-92 check and referential constraints (defined using the create table (see Create Table Statement) and alter table statements), but does not ignore unique (and primary key) constraints.
The copy statement does not fire any rules defined against the table.
Values cannot be assigned to SYSTEM_MAINTAINED logical key columns. The DBMS Server assigns values when copying from a data file to a table. This occurs even if the logical key column is being implicitly loaded using an unformatted copy; the values in the data file are ignored, and new values assigned by the DBMS Server.
Copy treats a present-but-empty field in the data file as:
• A blank default for character-based columns
• A zero default for numeric columns
• December 31 00-1 for date and timestamp columns
• 00:00:00 for time columns (and the time component in a timestamp)
For example, if you load a data file (copy from) that contains a record with one empty value into a table with a mandatory (not default) integer field, the load of the one record does not fail due to the missing value, but succeeds and loads a 0. You do get the error for the missing value if the column is omitted from the copy list. Note that if the table has a column defined with a default value and the field in the data file is present but empty, copy loads the default as listed above. If you omit the column from the copy list then you will get the proper default value.
Related Statements
Examples--Copy Statement
The following examples illustrate the correct use of the copy statement:
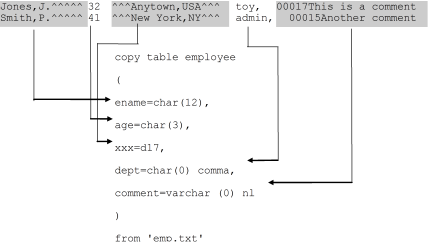
1. In the following Data File Format example, the contents of the file, emp.txt, are copied into the employee table. To omit the city column, a dummy column is employed. The format of the employee table is as follows:
ename char(15)
age integer4
dept char(10)
comment varchar(20)
age integer4
dept char(10)
comment varchar(20)
The emp.txt file contains the following data:
Jones,J. 32 Anytown,USA toy,00017A This is a comment
Smith,P. 41 New York,NY admin,00015 Another comment
The following diagram illustrates the copy statement that copies the file, emp.txt, into the employee table, and maps the fields in the file to the portions of the statement that specify how the field is to be copied. Note the following points:
A dummy column is used to skip the city and state field in the data file, because there is no matching column in the employee table.
The department field is delimited by a comma.
The comment field is a variable-length varchar field, preceded by a five-character length specifier.
2. Load the employee table from a data file. The data file contains binary data (rather than character data that can be changed using a text editor).
copy table employee (eno=integer2, ename=char(10),
age=integer2, job=integer2, sal=float4,
dept=integer2, xxx=d1)
from 'myfile.in';
age=integer2, job=integer2, sal=float4,
dept=integer2, xxx=d1)
from 'myfile.in';
3. Copy data from the employee table into a file. The example copies employee names, employee numbers, and salaries into a file, inserting commas and newline characters so that the file can be printed or edited. All items are stored as character data. The sal column is converted from its table format (money) to ASCII characters in the data file.
copy table employee (ename=char(0)comma,
eno=char(0)comma, sal= char(0)nl)
into 'mfile.out';
eno=char(0)comma, sal= char(0)nl)
into 'mfile.out';
Joe Smith , 101, $25000.00
Shirley Scott , 102, $30000.00
Shirley Scott , 102, $30000.00
4. The same example as #3, except that text format is used to eliminate all padding. The comma-separated-values delimiter is used.
copy table employee (ename = text(0)csv,
eno = text(0)csv, sal = text(0)csv)
into 'mfile.out';
Joe Smith,101,$25000.00
Shirley Scott,102,$30000.00
5. Bulk copy the employee table into a file. The resulting data file contains binary data.
copy table employee () into 'ourfile.dat';
6. Bulk load the file created in the preceding example into another table. The other_employee_table must have the same column definitions as the employee table.
copy table other_employee_table () from 'ourfile.dat';
7. Copy the acct_recv table into a file. The following statement skips the address column, uses the percent sign (%) as a field delimiter, uses 'xx' to indicate null debit and credit fields, and inserts a newline at the end of each record.
copy table acct_recv
(acct_name=char(0)'%',
address='d0%',
credit=char(0)'%' with null('xx'),
debit=char(0)'%' with null('xx'),
acct_mngr=char(15),
xx=d0nl)
into 'qtr_result';
(acct_name=char(0)'%',
address='d0%',
credit=char(0)'%' with null('xx'),
debit=char(0)'%' with null('xx'),
acct_mngr=char(15),
xx=d0nl)
into 'qtr_result';
Smith Corp%% $12345.00% $-67890.00%Jones
ABC Oil %% $54321.00% $-98765.00%Green
Spring Omc%%xx %xx %Namroc
8. Copy a table called, gifts, to a file for archiving. This table contains a record of all non-monetary gifts received by a charity foundation. The columns in the table contain the name of the item, when it was received, and who sent it. Because givers are often anonymous, the column representing the sender is nullable.
copy table gifts
(item_name=char(0)tab,
date_recd=char(0)tab,
sender=char(20)nl with null('anonymous'))
into 'giftdata';
(item_name=char(0)tab,
date_recd=char(0)tab,
sender=char(20)nl with null('anonymous'))
into 'giftdata';
toaster 04-mar-1993 Nicholas
sled 10-oct-1993 anonymous
rocket 01-dec-1993 Francisco
9. Create a table and load it using bulk copy, specifying structural options.
create table mytable (name char 25, ...);
modify mytable to hash;
copy mytable() from 'myfile' with minpages = 16384,
maxpages = 16384, allocation = 16384;
modify mytable to hash;
copy mytable() from 'myfile' with minpages = 16384,
maxpages = 16384, allocation = 16384;
Last modified date: 05/07/2026