Advanced Features
This chapter includes the following sections that describe advanced features of the data provider:
Using Connection Pooling
Connection pooling allows you to reuse connections rather than creating a new one every time the data provider needs to establish a connection to the underlying database. The data provider automatically enables connection pooling for your .NET client application.
You can control connection pooling behavior by using connection string options. For example, you can define the number of connection pools, the number of connections in a pool, and the number of seconds before a connection is discarded.
Connection pooling in ADO.NET is not provided by the .NET Framework. It must be implemented in the ADO.NET data provider itself.
Creating a Connection Pool
Each connection pool is associated with a specific connection string. By default, when the first connection with a unique connection string connects to the database, the connection pool is created. The pool is populated with connections up to the minimum pool size. Additional connections can be added until the pool reaches the maximum pool size.
The pool remains active as long as any connections remain open, either in the pool or used by an application with a reference to a Connection object that has an open connection.
If a new connection is opened and the connection string does not match an existing pool, a new pool must be created. By using the same connection string, you can enhance the performance and scalability of your application.
In the following C# code fragments, three new PsqlConnection objects are created, but only two connection pools are required to manage them. Note that the first and second connection strings differ only by the values assigned for User ID and Password, and by the value of the Min Pool Size option.
DbProviderFactory Factory = DbProviderFactories.GetFactory("Pervasive.Data.SqlClient");
DbConnection conn1 = Factory.CreateConnection();
conn1.ConnectionString = "Server DSN=DEMODATA;User ID=test;
Password=test;Host=localhost;"conn1.Open();
// Pool A is created.
DbConnection conn2 = Factory.CreateConnection();
conn2.ConnectionString = "Server DSN=DEMODATA2;User ID=lucy;
Password=quake;Host=localhost;"
conn2.Open();
// Pool B is created because the connection strings differ.
DbConnection conn3 = Factory.CreateConnection();
conn3.ConnectionString = "Server DSN=DEMODATA;User ID=test;
Password=test;Host=localhost;"
conn3.Open();
// conn3 goes into Pool A with conn1.
Adding Connections to a Pool
A connection pool is created in the process of creating each unique connection string that an application uses. When a pool is created, it is populated with enough connections to satisfy the minimum pool size requirement, set by the Min Pool Size connection string option. If an application is using more connections than Min Pool Size, the data provider allocates additional connections to the pool up to the value of the Max Pool Size connection string option, which sets the maximum number of connections in the pool.
When a Connection object is requested by the application calling the Connection.Open(…) method, the connection is obtained from the pool, if a usable connection is available. A usable connection is defined as a connection that is not currently in use by another valid Connection object, has a matching distributed transaction context (if applicable), and has a valid link to the server.
If the maximum pool size has been reached and no usable connection is available, the request is queued in the data provider. The data provider waits for the value of the Connection Timeout connection string option for a usable connection to return to the application. If this time period expires and no connection has become available, then the data provider returns an error to the application.
You can allow the data provider to create more connections than the specified maximum pool size without affecting the number of connections pooled. This may be useful, for example, to handle occasional spikes in connection requests. By setting the Max Pool Size Behavior connection string option to SoftCap, the number of connections created can exceed the value set for Max Pool Size, but the number of connections pooled does not. When the maximum connections for the pool are in use, the data provider creates a new connection. If a connection is returned and the pool contains idle connections, the pooling mechanism selects a connection to be discarded so that the connection pool never exceeds the Max Pool Size. If Max Pool Size Behavior is set to HardCap, the number of connections created does not exceed the value set for Max Pool Size.
IMPORTANT: Closing the connection using the Close() or Dispose() method of the PsqlConnection object adds or returns the connection to the pool. When the application uses the Close() method, the connection string settings remain as they were before the Open() method was called. If you use the Dispose method to close the connection, the connection string settings are cleared, and the default settings are restored.
Removing Connections from a Pool
A connection is removed from a connection pool when it either exceeds its lifetime as determined by the Load Balance Timeout connection string option, or when a new connection that has a matching connection string is initiated by the application (PsqlConnection.Open() is called).
Before returning a connection from the connection pool to an application, the Pool Manager checks to see if the connection has been closed at the server. If the connection is no longer valid, the Pool Manager discards it, and returns another connection from the pool, if one is available and valid.
You can control the order in which a connection is removed from the connection pool for reuse, based on how frequently or how recently the connection has been used, with the Connection Pool Behavior connection string option. For a balanced use of connections, use the LeastFrequentlyUsed or LeastRecentlyUsed values. Alternatively, for applications that perform better when they use the same connection every time, you can use the MostFrequentlyUsed or MostRecentlyUsed values.
The ClearPool and ClearAllPools methods of the Connection object remove all connections from connection pools. ClearPool clears the connection pool associated with a specific connection. In contrast, ClearAllPools clears all of the connection pools used by the data provider. Connections that are in use when the method is called are discarded when they are closed.
Note: By default, if discarding an invalid connection causes the number of connections to drop below the number specified in the Min Pool Size attribute, a new connection will not be created until an application needs one.
Handling Dead Connection in a Pool
What happens when an idle connection loses its physical connection to the database? For example, suppose the database server is rebooted or the network experiences a temporary interruption. An application that attempts to connect using an existing Connection object from a pool could receive errors because the physical connection to the database has been lost.
The PSQL ADO.NET Data Provider handles this situation transparently to the user. The application does not receive any errors on the Connection.Open() attempt because the data provider simply returns a connection from a connection pool. The first time the Connection object is used to execute a SQL statement (for example, through the Execute method on the Command object), the data provider detects that the physical connection to the server has been lost and attempts to reconnect to the server
before executing the SQL statement. If the data provider can reconnect to the server, the result of the SQL execution is returned to the application; no errors are returned to the application. The data provider uses the connection failover options, if enabled, when attempting this seamless reconnection. See
Using Connection Failover for information about configuring the data provider to connect to a backup server when the primary server is not available.
Note: Because the data provider can attempt to reconnect to the database server when executing SQL statements, connection errors can be returned to the application when a statement is executed. If the data provider cannot reconnect to the server (for example, because the server is still down), the execution method throws an error indicating that the reconnect attempt failed, along with specifics about the reason the connection failed.
This technique for handling dead connections in connection pools allows for the maximum performance out of the connection pooling mechanism. Some data providers periodically ping the server with a dummy SQL statement while the connections sit idle. Other data providers ping the server when the application requests the use of the connection from the connection pool. Both of these approaches add round trips to the database server and ultimately slow down the application during normal operation of the application is occurring.
Tracking Connection Pool Performance
The data providers install a set of PerfMon counters that let you tune and debug applications that use the data provider. See
PerfMon Support for information about using the PerfMon counters.
Using Statement Caching
A statement cache is a group of prepared statements or instances of Command objects that can be reused by an application. Using statement caching can improve application performance because the actions on the prepared statement are performed once even though the statement is reused multiple times over an application’s lifetime. You can analyze the effectiveness of the statements in the cache (see
Analyzing Performance With Connection Statistics).
A statement cache is owned by a physical connection. After being executed, a prepared statement is placed in the statement cache and remains there until the connection is closed.
Statement caching can be used across multiple data sources and can be used beneath abstraction technologies such as the Microsoft Enterprise Libraries with the Data Access Application Blocks.
Enabling Statement Caching
By default, statement caching is not enabled. To enable statement caching for existing applications, set the Statement Cache Mode connection string option to Auto. In this case, all statements are eligible to be placed in the statement cache.
You can also configure statement caching so that only statements that you explicitly mark to be cached are placed in the statement cache. To do this, set the StatementCacheBehavior property of the statement’s Command object to Cache and set the Statement Cache Mode connection string option to ExplicitOnly.
Table
2 summarizes the statement caching settings and their effects.
Table 2 Summary of Statement Cache Behavior
Behavior | StatementCacheBehavior | Statement Cache Mode |
Explicitly add the statement to the statement cache. | Cache | ExplicitOnly (the default) |
Add the statement to the statement cache. If necessary, the statement is removed to make room for a statement marked Cache. | Implicit (the default) | Auto |
Specifically exclude the statement from the statement cache. | DoNotCache | Auto or ExplicitOnly |
Choosing a Statement Caching Strategy
Statement caching provides performance gains for applications that reuse prepared statements multiple times over the lifetime of an application. You set the size of the statement cache with the Max Statement Cache Size connection string option. If space in the statement cache is limited, do not cache prepared statements that are used only once.
Caching all of the prepared statements that an application uses might appear to offer the best performance. However, this approach may come at a cost of database memory if you implement statement caching with connection pooling. In this case, each pooled connection has its own statement cache that may contain all of the prepared statements used by the application. All of these pooled prepared statements are also maintained in the database’s memory.
Using Connection Failover
Connection failover allows an application to connect to an alternate, or backup, database server if the primary database is unavailable, for example, because of a hardware failure or traffic overload. Connection failover ensures that the data on which your critical .NET applications depend is always available.
You can customize the data provider for connection failover by configuring a list of alternate databases that are tried if the primary server is not accepting connections. Connection attempts continue until a connection is successfully established or until all of the alternate databases have been tried the specified number of times.
For example, Figure
1 shows an environment with multiple database servers. Database Server A is designated as the primary database server, Database Server B is the first alternate server, and Database Server C is the second alternate server.
Figure 1 Connection Failover
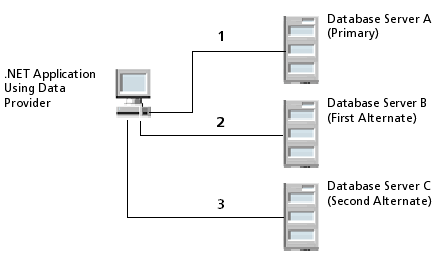
First, the application attempts to connect to the primary database, Database Server A (1). If connection failover is enabled and Database Server A fails to accept the connection, the application attempts to connect to Database Server B (2). If that connection attempt also fails, the application attempts to connect to Database Server C (3).
In this scenario, it is probable that at least one connection attempt would succeed, but if no connection attempt succeeds, the data provider can retry the primary server and each alternate database for a specified number of attempts. You can specify the number of attempts that are made through the
connection retry feature. You can also specify the number of seconds of delay, if any, between attempts through the
connection delay feature. For more information about connection retry, see
Using Connection Retry.
The data provider fails over to the next alternate server only if it cannot establish communication with the current alternate server. If the data provider successfully establishes communication with a database and the database rejects the connection request because, for example, the login information is invalid, then the data provider generates an exception and does not try to connect to the next database in the list. It is assumed that each alternate server is a mirror of the primary and that all authentication parameters and other related information are the same.
Connection failover provides protection for new connections only and does not preserve states for transactions or queries. For details on configuring connection failover for your data provider, see
Configuring Connection Failover.
Using Client Load Balancing
Client load balancing works with connection failover to distribute new connections in your environment so that no one server is overwhelmed with connection requests. When both connection failover and client load balancing are enabled, the order in which primary and alternate databases are tried is random.
For example, suppose that client load balancing is enabled as shown in Figure
2:
Figure 2 Client Load Balancing Example
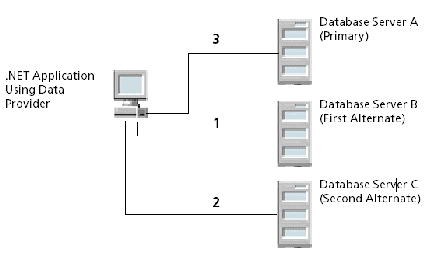
First, Database Server B is tried (1). Then, Database Server C may be tried (2), followed by a connection attempt to Database Server A (3); subsequent connection attempts use this same sequence. In contrast, if client load balancing was not enabled in this scenario, each database would be tried in sequential order, primary server first, then alternate servers based on their entry order in the alternate servers list.
For details on configuring client and load balancing for your data provider, see
Configuring Connection Failover.
Using Connection Retry
Connection retry defines the number of times that the data provider attempts to connect to the primary, and, if configured, alternate database servers after the first unsuccessful connection attempt. Connection retry can be an important strategy for system recovery. For example, suppose you have a power failure scenario in which both the client and the server fail. When the power is restored and all computers are restarted, the client may be ready to attempt a connection before the server has completed its startup routines. If connection retry is enabled, the client application can continue to retry the connection until a connection is successfully accepted by the server.
Connection retry can be used in environments that only have one server or can be used as a complementary feature in connection failover scenarios with multiple servers.
Using connection string options, you can specify the number of times the data provider attempts to connect and the time in seconds between connection attempts. For details on configuring connection retry, see
Configuring Connection Failover.
Configuring Connection Failover
Connection failover allows an application to connect to an alternate, or backup, database server if the primary database server is unavailable, for example, because of a hardware failure or traffic overload.
See
Using Connection Failover for more information about connection failover.
To configure connection failover to another server, you must specify a list of alternate database servers that are tried at connection time if the primary server is not accepting connections. To do this, use the Alternate Servers connection string option. Connection attempts continue until a connection is successfully established or until all the databases in the list have been tried once (the default).
Optionally, you can specify the following additional connection failover features:
•The number of times the data provider attempts to connect to the primary and alternate servers after the initial connection attempt. By default, the data provider does not retry. To set this feature, use the Connection Retry Count connection string option.
•The wait interval, in seconds, used between attempts to connect to the primary and alternate servers. The default interval is 3 seconds. To set this feature, use the Connection Retry Delay connection option.
•Whether the data provider will use load balancing in its attempts to connect to primary and alternate servers. If load balancing is enabled, the data provider uses a random pattern instead of a sequential pattern in its attempts to connect. The default value is not to use load balancing. To set this feature, use the Load Balancing connection string option.
You use a connection string to direct the data provider to use connection failover. See
Using Connection Strings.
The following C# code fragment includes a connection string that configures the data provider to use connection failover in conjunction with all of its optional features – load balancing, connection retry, and connection retry delay:
Conn = new PsqlConnection Conn = new PsqlConnection();
Conn = new PsqlConnection("Host=myServer;User ID=test;Password=secret;
Server DSN=SERVERDEMO;Alternate Servers="Host=AcctServer, Host=AcctServer2";
Connection Retry Count=4;Connection Retry Delay=5;Load Balancing=true;
Connection Timeout=60")
Specifically, this connection string configures the data provider to use two alternate servers as connection failover servers, to attempt to connect four additional times if the initial attempt fails, to wait five seconds between attempts, and to try the primary and alternate servers in a random order. Each connection attempt lasts for 60 seconds, and uses the same random order that was established on the first retry.
Setting Security
The data provider supports Encrypted Network Communications, also known as wire encryption, on connections. By default, the data provider reflects the server's setting. See Table
27 for more information on encryption settings.
The level of encryption allowed by the data provider depends on the encryption module used. With the default encryption module, the data provider supports 40-, 56-, and 128-bit encryption.
Data encryption may adversely affect performance because of the additional overhead, mainly CPU usage, required to encrypt and decrypt data.
In addition to encryption, the PSQL ADO.NET Data Provider implements security through the security permissions defined by the .NET Framework.
Code Access Permissions
The data provider requires the FullTrust permission to be set in order to load and run. This requirement is due to underlying classes in System.Data that demand FullTrust for inheritance. All ADO.NET data providers require these classes to implement a DataAdapter.
Security Attributes
The data provider is marked with the AllowPartiallyTrustedCallers attribute.
Using PSQL Bulk Load
PSQL Bulk Load offers a one-stop approach for all of your bulk load needs, with a simple, consistent way to do bulk load operations for PSQL and for all of the DataDirect Connect products that support this bulk load feature. This means that you can write your bulk load applications using the standards-based API bulk interfaces, and then, just plug in the database data providers or drivers to do the work for you.
Suppose you need to load data into PSQL, Oracle, DB2, and Sybase. In the past, you probably had to use a proprietary tool from each database vendor for bulk load operations, or write your own tool. Now, because of the interoperability built into PSQL Bulk Load, your task is much easier. Another advantage is that PSQL Bulk Load uses 100% managed code, and requires no underlying utilities or libraries from other vendors.
Bulk load operations between dissimilar data stores are accomplished by persisting the results of the query in a comma-separated value (CSV) format file, a bulk load data file. The file can be used between the PSQL ADO.NET Data Provider and any DataDirect Connect for ADO.NET data providers that support bulk load. In addition, the bulk load data file can be used with any DataDirect Connect product driver or data provider that supports the Bulk load functionality. For example, the CSV file generated by the PSQL data provider can be used by a DataDirect Connect for ODBC driver that supports bulk load.
Use Scenarios for PSQL Bulk Load
You can use PSQL Bulk Load with the PSQL ADO.NET Data Provider in two ways:
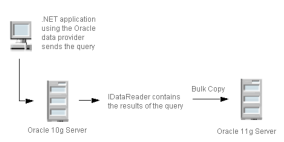
•Upgrade to a new PSQL version and copy data from the old PSQL data source to the new one, as shown in Figure
3.
Figure 3 Using PSQL Bulk Load Between Two Data Sources
•Export data from a database and migrate the results to a PSQL database. Figure
4 shows an ODBC environment copying data to an ADO.NET database server.
Figure 4 Copying Data from ODBC to ADO.NET
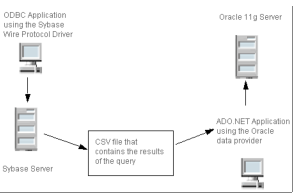
In this figure, the ODBC application includes code to export data to the CSV file, and the ADO.NET application includes code to specify and open the CSV file. Because the PSQL ADO.NET Data Provider and the DataDirect ODBC drivers use a consistent format, interoperability is supported via these standard interfaces.
PSQL Common Assembly
The PSQL Bulk Load implementation for ADO.NET uses the de facto standard defined by the Microsoft SqlBulkCopy classes, and adds powerful built-in features to enhance interoperability as well as the flexibility to make bulk operations more reliable.
The data provider includes provider-specific classes to support PSQL Bulk Load. See
Data Provider-Specific Classes for more information. If you use the Common Programming Model, you can use the classes in the PSQL Common Assembly (see
PSQL Common Assembly Classes).
The Pervasive.Data.Common assembly includes classes that support PSQL Bulk Load, such as the CsvDataReader and CsvDataWriter classes that provide functionality between bulk data formats.
The Common assembly also extends support for bulk load classes that use the Common Programming Model. This means that the SqlBulkCopy patterns can now be used in a new DbBulkCopy hierarchy.
Future versions of the data provider will include other features that enhance the Common Programming Model experience. See
PSQL Common Assembly Classes for more information on the classes supported by the Pervasive.Data.Common assembly.
Bulk Load Data File
The results of queries between dissimilar data stores are persisted in a comma-separated value (CSV) format file, a bulk load data file. The file name, which is defined by the BulkFile property, is using for writing and reading the bulk data. If the file name does not contain an extension, the ".csv" extension is assumed.
Example
The PSQL source table GBMAXTABLE contains four columns. The following C# code fragment writes the GBMAXTABLE.csv and GBMAXTABLE.xml files that will be created by the CsvDataWriter. Note that this example uses the DbDataReader class.
cmd.CommandText = "SELECT * FROM GBMAXTABLE ORDER BY INTEGERCOL";
DbDataReader reader = cmd.ExecuteReader();
CsvDataWriter csvWriter = new CsvDataWriter();
csvWriter.WriteToFile("\\NC1\net\PSQL\GBMAXTABLE\GBMAXTABLE.csv", reader);
The bulk load data file GBMAXTABLE.csv contains the results of the query:
1,0x6263,"bc","bc"
2,0x636465,"cde","cde"
3,0x64656667,"defg","defg"
4,0x6566676869,"efghi","efghi"
5,0x666768696a6b,"fghijk","fghijk"
6,0x6768696a6b6c6d,"ghijklm","ghijklm"
7,0x68696a6b6c6d6e6f,"hijklmno","hijklmno"
8,0x696a6b6c6d6e6f7071,"ijklmnopq","ijklmnopq"
9,0x6a6b6c6d6e6f70717273,"jklmnopqrs","jklmnopqrs"
10,0x6b,"k","k"
The GBMAXTABLE.xml file, which is the bulk load configuration file that provides the format of this bulk load data file, is described in the following section.
Bulk Load Configuration File
A bulk load configuration file is produced when the CsvDataWriter.WriteToFile method is called (see
CsvDataWriter for more information).
The bulk load configuration file defines the names and data types of the columns in the bulk load data file. These names and data types are defined the same way as the table or result set from which the data was exported.
If the bulk data file cannot be created or does not comply with the schema described in the XML configuration file, an exception is thrown. See
XML Schema Definition for a Bulk Data Configuration File for more information about using an XML schema definition.
If a bulk load data file that does not have a configuration file is read, the following defaults are assumed:
•All data is read in as character data. Each value between commas is read as character data.
•The default character set is the character set of the platform on which the Bulk Load CSV file is being read. See
Character Set Conversions for more information.
The bulk load configuration file describes the bulk data file and is supported by an underlying XML Schema defined at:
Example
The format of the bulk load data file shown in the previous section is defined by the bulk load configuration file, GBMAXTABLE.xml. The file describes the data type and other information about each of the four columns in the table.
<?xml version="1.0" encoding="utf-8"?>
<table codepage="UTF-16LE" xsi:noNamespaceSchemaLocation="http://www.datadirect.com/ns/bulk/BulkData.xsd" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<row>
<column datatype="DECIMAL" precision="38" scale="0" nullable=
"false">INTEGERCOL</column>
<column datatype="VARBINARY" length="10" nullable=
"true">VARBINCOL</column>
<column datatype="VARCHAR" length="10" sourcecodepage="Windows-1252"
externalfilecodepage="Windows-1252" nullable="true">VCHARCOL</column>
<column datatype="VARCHAR" length="10" sourcecodepage="Windows-1252"
externalfilecodepage="Windows-1252" nullable="true">UNIVCHARCOL</column>
</row>
</table>
Determining the Bulk Load Protocol
Bulk operations can be performed using dedicated bulk protocol, that is, the data provider uses the protocol of the underlying database. In some cases, the dedicated bulk protocol is not available, for example, when the data to be loaded is in a data type not supported by the dedicated bulk protocol. Then, the data provider automatically uses a non-bulk method such as array binding to perform the bulk operation, maintaining optimal application uptime.
Character Set Conversions
At times, you might need to bulk load data between databases that use different character sets.
For the PSQL ADO.NET Data Provider, the default source character data, that is, the output from the CsvDataReader and the input to the CsvDataWriter, is in Unicode (UTF-16) format. The source character data is always transliterated to the code page of the CSV file. If the threshold is exceeded and data is written to the external overflow file, the source character data is transliterated to the code page specified by the externalfilecodepage attribute defined in the bulk configuration XML schema (see
XML Schema Definition for a Bulk Data Configuration File). If the configuration file does not define a value for externalfilecodepage, the CSV file code page is used.
To avoid unnecessary transliteration, it's best for the CSV and external file character data to be stored in Unicode (UTF-16). You might want your applications to store the data in another code page in one of the following scenarios:
•The data will be written by ADO.NET and read by ODBC. In this case, the read (and associated transliteration) is done by ODBC. If the character data is already in the correct code page, no transliteration is necessary.
•Space is a consideration. Depending on the code page, the character data could be represented more compactly. For example, ASCII data is a single byte per character, UTF-16 is 2 bytes per character).
The configuration file may optionally define a second code page for each character column. When character data exceeds the value defined by the CharacterThreshold property and is stored in a separate file (see
External Overflow File), the value defines the code page for that file.
If the value is omitted or if the code page defined by the source column is unknown, the code page defined for the CSV file will be used.
External Overflow File
If the value of the BinaryThreshold or CharacterThreshold property of the CsvDataWriter object is exceeded, separate files are generated to store the binary or character data. These overflow files are located in the same directory as the bulk data file.
If the overflow file contains character data, the character set of the file is governed by the character set specified in the CSV bulk configuration file.
The filename contains the CSV filename and a ".lob" extension (for example, CSV_filename_nnnnnn.lob). These files exist in the same location as the CSV file. Increments start at _000001.lob.
Bulk Copy Operations and Transactions
By default, bulk copy operations are performed as isolated operations and are not part of a transaction. This means there is no opportunity for rolling the operation back if an error occurs.
PSQL allows bulk copy operations to take place within an existing transaction. You can define the bulk copy operation to be part of a transaction that occurs in multiple steps. Using this approach enables you to perform more than one bulk copy operation within the same transaction, and commit or roll back the entire transaction.
Refer to the Microsoft online help topic "Transaction and Bulk Copy Operations (ADO.NET)" for information about rolling back all or part of the bulk copy operation when an error occurs.
Using Diagnostic Features
The .NET Framework provides a Trace class that can help end users identify the problem without the program having to be recompiled.
The PSQL ADO.NET Data Provider delivers additional diagnostic capability:
•Ability to trace method calls
•Performance Monitor hooks that let you monitor connection information for your application
Tracing Method Calls
Tracing capability can be enabled either through environment variables or the PsqlTrace class. The data provider traces the input arguments to all of its public method calls, as well as the outputs and returns from those methods (anything that a user could potentially call). Each call contains trace entries for entering and exiting the method.
During debugging, sensitive data can be read, even if it is stored as a private or internal variable and access is limited to the same assembly. To maintain security, trace logs show passwords as five asterisks (*****).
Using Environment Variables
Using environment variables to enable tracing means that you do not have to modify your application. If you change the value of an environment variable, you must restart the application for the new value to take effect.
Table
3 describes the environment variables that enable and control tracing.
Table 3 Environment Variables
Environment Variable | Description |
PVSW_NET_Enable_Trace | If set to 1 or higher, enables tracing. If set to 0 (the default), tracing is disabled. |
PVSW_NET_Recreate_Trace | If set to 1, recreates the trace file each time the application restarts. If set to 0 (the default), the trace file is appended. |
PVSW_NET_Trace_File | Specifies the path and name of the trace file. |
Notes
•Setting PVSW_NET_Enable_Trace = 1 starts the tracing process. Therefore, you must define the property values for the trace file before enabling the trace. Once the trace processing starts, the values of the other environment variables cannot be changed.
•If tracing is enabled and no trace file is specified by either the connection string option or the environment variable, the data provider saves the results to a file named PVSW_NETTrace.txt.
Using Static Methods
Some users may find that using static methods on the data provider’s Trace class to be a more convenient way to enable tracing. The following C# code fragment uses static methods on the .NET Trace object to create a PsqlTrace class with a trace file named MyTrace.txt. The values set override the values set in the environmental variables. All subsequent calls to the data provider will be traced to MyTrace.txt.
PsqlTrace.TraceFile="C:\\MyTrace.txt";
PsqlTrace.RecreateTrace = 1;
PsqlTrace.EnableTrace = 1;
The trace output has the following format:
<Correlation#> <Timestamp> <CurrentThreadName>
<Object Address> <ObjectName.MethodName> ENTER (or EXIT)
Argument #1 : <Argument#1 Value>
Argument #2 : <Argument#2 Value>
...
RETURN: <Method ReturnValue> // This line only exists for EXIT
where:
Correlation# is a unique number that can be used to match up ENTER and EXIT entries for the same method call in an application.
Value is the hash code of an object appropriate to the individual function calls.
During debugging, sensitive data can be read, even if it is stored as private or internal variable and access is limited to the same assembly. To maintain security, trace logs show passwords as five asterisks (*****).
PerfMon Support
The Performance Monitor (PerfMon) and VS Performance Monitor (VSPerfMon) utilities allow you to record application parameters and review the results as a report or graph. You can also use Performance Monitor to identify the number and frequency of CLR exceptions in your applications. In addition, you can fine-tune network load by analyzing the number of connections and connection pools being used.
The data provider installs a set of PerfMon counters that let you tune and debug applications that use the data provider. The counters are located in the Performance Monitor under the category name PSQL ADO.NET data provider.
Table
4 describes the PerfMon counters that you can use to tune connections for your application.
Table 4 PerfMon Counters
Counter | Description |
Current # of Connection Pools | Current number of pools associated with the process. |
Current # of Pooled and Non-Pooled Connections | Current number of pooled and non-pooled connections. |
Current # of Pooled Connections | Current number of connections in all pools associated with the process. |
Peak # of Pooled Connections | The highest number of connections in all connection pools since the process started. |
Total # of Failed Commands | The total number of command executions that have failed for any reason since the process started. |
Total # of Failed Connects | The total number of attempts to open a connection that have failed for any reason since the process started. |
For information on using PerfMon and performance counters, refer to the Microsoft documentation library.
Analyzing Performance With Connection Statistics
The .NET Framework 2.0 and higher supports run-time statistics, which are gathered on a per-connection basis. The PSQL ADO.NET Data Provider supports a wide variety of run-time statistical items. These statistical items provide information that can help you to:
•Automate analysis of application performance
•Identify trends in application performance
•Detect connectivity incidents and send notifications
•Determine priorities for fixing data connectivity problems
Measuring the statistics items affects performance slightly. For best results, consider enabling statistics gathering only when you are analyzing network or performance behavior in your application.
Statistics gathering can be enabled on any Connection object, for as long as it is useful. For example, you can define your application to enable statistics before beginning a complex set of transactions related to performing a business analysis, and disable statistics when the task is complete. You can retrieve the length of time the data provider had to wait for the server and the number of rows that were returned as soon as the task is complete, or wait until a later time. Because the application disables statistics at the end of the task, the statistical items are measured only during the period in which you are interested.
Functionally, the statistical items can be grouped into four categories:
•Network layer items retrieve values associated with network activities, such as the number of bytes and packets that are sent and received and the length of time the data provider waited for replies from the server.
•Aggregate items return a calculated value, such as the number of bytes sent or received per round trip to the server.
•Row disposition statistical items provide information about the time and resources required to dispose of rows not read by the application.
•Statement cache statistical items return values that describe the activity of statements in a statement cache (see
Using Statement Caching for more information on using the statement cache).
Enabling and Retrieving Statistical Items
When you create a Connection object, you can enable statistics gathering using the StatisticsEnabled property. The data provider begins the counts for the statistical items after you open a connection, and continues until the ResetStatistics method is called. If the connection is closed and reopened without calling ResetStatistics, the count on the statistical items continues from the point when the connection was closed.
Calling the RetrieveStatistics method retrieves the count of one or more statistical items. The values returned form a "snapshot in time" at the moment when the RetrieveStatistics method was called.
You can define the scope for the statistics gathering and retrieval. In the following C# code fragment, the statistical items measure only the Task A work; they are retrieved after processing the Task B work:
connection.StatisticsEnabled = true;
// do Task A work
connection.StatisticsEnabled = false;
// do Task B work
IDictionary currentStatistics = connection.RetrieveStatistics();
To view all the statistical items, you can use code like the following C# code fragment:
foreach (DictionaryEntry entry in currentStatistics) {
Console.WriteLine(entry.Key.ToString() + ": " + entry.Value.ToString());
}
Console.WriteLine();
To view only the SocketReads and SocketWrites statistical items, you can use code like the following C# code fragment:
foreach (DictionaryEntry entry in currentStatistics) {
Console.WriteLine("SocketReads = {0}",
currentStatistics["SocketReads"]);
Console.WriteLine("SocketWrites = {0}",
currentStatistics["SocketWrites"]);
}
Console.WriteLine();
Note for ADO.NET Entity Framework Users: The PsqlConnection methods and properties for statistics are not available at the ADO.NET Entity Framework layer. Instead, the data provider exposes the same functionality through "pseudo" stored procedures. See
Using Stored Procedures with the ADO.NET Entity Framework for more information.