Designing a Database
The following topics provide formulas and guidelines for designing your database:
Understanding Data Files
The MicroKernel Engine stores information in data files. Inside each data file is a collection of records and indexes. A record contains bytes of data. That data might represent an employee’s name, ID, address, phone number, rate of pay, and so on. An index provides a mechanism for quickly finding a record containing a specific value for a portion of the record.
The MicroKernel Engine interprets a record only as a collection of bytes. It does not recognize logically discrete pieces, or fields, of information within a record. To the MicroKernel Engine, a last name, first name, employee ID, and so on do not exist inside a record. The record is simply a collection of bytes.
Because it is byte-oriented, the MicroKernel Engine performs no translation, type verification, or validation of the data in a record – even on keys (for which you declare a data type). The application interfacing with the data file must handle all information about the format and type of the data in that file. For example, an application might use a data structure based on the following format:
Information in Record | Length (in Bytes) | Data Type |
Last name | 25 | Null-terminated string |
First name | 25 | Null-terminated string |
Middle initial | 1 | Char (byte) |
Employee ID | 4 | Long (4-byte integer) |
Phone number | 13 | Null-terminated string |
Pay rate per month | 4 | Float |
Total Record Length | 72 bytes |
Inside the file, an employee’s record is stored as a collection of bytes. The following diagram shows the data for the record for Cliff Jones, as it is stored in the file. (This diagram replaces ASCII values in strings with the appropriate letter or number. Integers and other numeric values are unchanged from their normal hexadecimal representation.)
Byte Position | 00 | 01 | 02 | 03 | 04 | 05 | 06 | 07 | 08 | 09 | 0A | 0B | 0C | 0D | 0E | 0F |
Data Value | J | o | n | e | s | 00 | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? |
| | | | | | | | | | | | | | | | |
Byte Position | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 1A | 1B | 1C | 1D | 1E | 1F |
Data Value | ? | ? | ? | ? | ? | ? | ? | ? | ? | C | l | i | f | f | 00 | ? |
| | | | | | | | | | | | | | | | |
Byte Position | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 2A | 2B | 2C | 2D | 2E | 2F |
Data Value | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? |
| | | | | | | | | | | | | | | | |
Byte Position | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 3A | 3B | 3C | 3D | 3E | 3F |
Data Value | ? | ? | D | 2 | 3 | 4 | 1 | 5 | 1 | 2 | 5 | 5 | 5 | 1 | 2 | 1 |
| | | | | | | | | | | | | | | | |
Byte Position | 40 | 41 | 42 | 43 | 44 | 45 | 46 | 47 | | | | | | | | |
Data Value | 2 | ? | ? | ? | 3 | 5 | 0 | 0 | | | | | | | | |
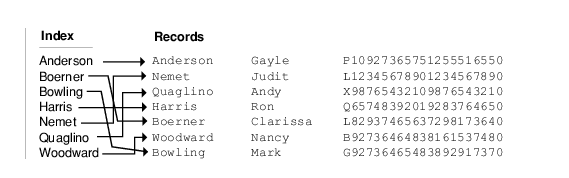
The only discrete portions of information that the MicroKernel Engine recognizes in a file are keys. An application (or user) can designate one or more collection of bytes in a record as a key, but the bytes must be contiguous inside each key segment.
The MicroKernel Engine sorts records on the basis of the values in any specified key, providing direct access to return the data in a particular order. The MicroKernel Engine can also find a particular record based on a specified key value. In the preceding example, the 25 bytes that contain a last name in each record might be designated as a key in the file. An application could use the last name key to obtain a listing of all the employees named Smith, or it could obtain a listing of all employees and then display that listing, sorted by last name.
Keys also allow the MicroKernel Engine to access information quickly. For each key defined in a data file, the MicroKernel Engine builds an index. The index is stored inside the data file itself and contains a collection of pointers to the actual data within that file. A key value is associated with each pointer.
In the preceding example, the index for the Last Name key sorts the Last Name values and has a pointer indicating where the record is located in the data file:
Normally, when accessing or sorting information for an application, the MicroKernel Engine does not search through all the data in its data file. Instead, it goes to the index, performs the search, and then manipulates only those records that meet the application’s request.
Creating a Data File
The MicroKernel Engine gives developers tremendous flexibility in optimizing database applications. In providing such flexibility, the MicroKernel Engine exposes a great deal of the inner workings of the MicroKernel Engine. If you are new to the MicroKernel Engine, the Create (14) operation may appear quite complex to you, but you do not need all of the features this operation provides to get started. This section highlights the basic requirements by stepping you through the creation of a simple, transaction-based data file. For simplification where necessary, this section uses C interface terminology.
Note In the same directory, no two files should share the same file name and differ only in their file name extension. For example, do not name a data file invoice.btr and another one invoice.mkd in the same directory. This restriction applies because the database engine uses the file name for various areas of functionality while ignoring the file name extension. Since only the file name is used to differentiate files, files that differ only in their file name extension look identical to the database engine.
Data Layout
This section uses an example data file that stores employee records. The application will retrieve employee information by providing either a unique employee ID or the employee last name. Because more than one employee can have the same last name, the database will allow duplicate values for the last name. Based on these criteria, the following table shows the data layout for the file.
Information in Record | Data Type | Key/Index Characteristics |
Last name | 25 character string | Duplicatable |
First name | 25 character string | None |
Middle initial | 1 character string | None |
Employee ID | 4 byte integer | Unique |
Phone number | 13 character string | None |
Pay rate per month | 4 byte float | None |
Now that the basic data layout is established, you can begin applying the terminology and requirements of the MicroKernel Engine. This includes determining information about the key structure and file structure before you actually create the file. You must work out these details in advance, because Create (14) creates the file, index, and key information all at once. The following sections discuss the issues to consider in working out these details.
Key Attributes
First, determine any special functionality for the keys. The MicroKernel Engine supports a variety of key attributes you can assign, as shown in the following table.
Table 9 Key Attributes
Constant | Description |
EXTTYPE_KEY | Extended Data Type. Stores a MicroKernel Engine data type other than string or unsigned binary. Use this attribute, rather than the standard binary data type. This key attribute can accommodate the standard binary and string data types, plus many others. |
BIN | Standard BINARY Data Type. Supported for historical reasons. Stores an unsigned binary number. Default data type is string. |
DUP | Linked Duplicates. Allows duplicate values, which are linked by pointers from the index page to the data page. For more information, see
Duplicatable Keys. |
REPEAT_DUPS_KEY | Repeating Duplicates. Allows duplicate values, which are stored on both the index page and the data page. For more information, see
Duplicatable Keys. |
MOD | Modifiable. Allows the key value to be modified after the record is inserted. |
SEG | Segmented. Specifies that this key has a segment that follows the current key segment. |
NUL | Null Key (All Segments). Excludes any records from the index if all segments of the key contain a specified null value. (You assign the null value when you create the file.) |
MANUAL_KEY | Null Key (Any Segment). Excludes any records from the index if any segment in the key contains a specified null value. (You assign the null value when you create the file.) |
DESC_KEY | Descending Sort Order. Orders the key values in descending order (highest to lowest). Default is ascending order (lowest to highest). |
NOCASE_KEY | Case Insensitive. Sorts string values without distinguishing upper and lower case letters. Do not use if the key has an alternate collating sequence (ACS). In the case of a Null Indicator segment, this attribute is overloaded to indicate that non-zero null values should be treated distinctly. |
ALT | Alternate Collating Sequence. Uses collating sequence to sort string keys differently from the standard ASCII sequence. Different keys can use different collations. You can specify the default ACS (the first one defined in the file), a numbered ACS defined in the file, or a named ACS defined in the collate.cfg system file. |
NUMBERED_ACS |
NAMED_ACS |
For simplicity these constants, defined in btrconst.h, are consistent with the C interface. Some interfaces may use other names or no constants at all. For bit masks, hexadecimal, and decimal equivalents for the key attributes, see Btrieve API Guide. |
You assign these key attributes for each key you define. Each key has its own key specification. If the key has multiple segments, you have to provide the specification for each segment. Some of these attributes can have different values for different segments within the same key. Using the previous example, the keys are the last name and the employee ID. Both keys use extended types; the last name is a string and the employee ID is an integer. Both are modifiable, but only the last name is duplicatable. In addition, the last name is case insensitive.
Regarding the data type you assign to a key, the MicroKernel Engine does not validate that the records you input adhere to the data types defined for the keys. For example, you could define a TIMESTAMP key in a file, but store a character string there or define a date key and store a value for February 30. Your MicroKernel Engine application would work fine, but an ODBC application that tries to access the same data might fail, because the byte format could be different and the algorithms used to generate the time stamp value could be different. For complete descriptions of the data types, see SQL Engine Reference.
File Attributes
Next, determine any special functionality for the file.
The MicroKernel Engine supports a variety of file attributes you can assign, as follows:
Table 10 File Attributes
Constant | Description |
VAR_RECS | Variable Length Records. Use in files that contain variable length records. |
BLANK_TRUNC | Blank Truncation. Conserves disk space by dropping any trailing blanks in the variable-length portion of the record. Applicable only to files that allow variable-length records and that do not use data compression. For more information, see
Blank Truncation. |
PRE_ALLOC | Page Preallocation. Reserves contiguous disk space for use by the file as it is populated. Can speed up file operations if a file occupies a contiguous area on the disk. The increase in speed is most noticeable on very large files. For more information, see
Page Preallocation. |
DATA_COMP | Data Compression. Compresses records before inserting or updating them and uncompresses records when retrieving them. For more information, see
Record Compression. |
KEY_ONLY | Key-Only File. Includes only one key, and the entire record is stored with the key, so no data pages are required. Key-only files are useful when your records contain a single key and that key takes up most of each record. For more information, see
Key-Only Files. |
BALANCED_KEYS | Index Balancing. Rotates values from full index pages onto index pages that have space available. Index balancing enhances performance during read operations, but may require extra time during write operations. For more information, see
Index Balancing. |
FREE_10
FREE_20
FREE_30 | Free Space Threshold. Sets the threshold percentage for reusing disk space made available by deletions of variable length records, thus eliminating the need to reorganize files and reducing the fragmentation of variable-length records across several pages.
A larger Free Space Threshold reduces fragmentation of the variable-length portion of records which increases performance. However, it requires more disk space. If higher performance is desired, increase the Free Space Threshold to 30 percent. |
DUP_PTRS | Reserve Duplicate Pointers. Preallocates pointer space for linked duplicatable keys added in the future. If no duplicate pointers are available for creating a linked-duplicatable key, the MicroKernel Engine creates a repeating-duplicatable key. |
INCLUDE_SYSTEM_DATA | System Data. Includes system data upon file creation, which allows the MicroKernel Engine to perform transaction logging on the file. This is useful in files that do not contain a unique key. |
NO_INCLUDE_SYSTEM_DATA |
SPECIFY_KEY_NUMS | Key Number. Allows you to assign a specific number to a key, rather than letting the MicroKernel Engine assign numbers automatically. Some applications may require a specific key number. |
VATS_SUPPORT | Variable-tail Allocation Tables (VATs). Uses VATs (arrays of pointers to the variable-length portion of the record) to accelerate random access and to limit the size of the compression buffer used during data compression. For more information, see
Variable-tail Allocation Tables. |
For simplicity, these constants, defined in btrconst.h, are consistent with the C interface. Some interfaces may use other names or no constants at all. For bit masks, hexadecimal, and decimal equivalents for the file attributes, see Btrieve API Guide. |
The example data file does not use any of these file attributes, because the records are fixed-length records of small size.
For definitions of file attributes, see
File Types. For more information about specifying file attributes during the Create operation, see
Btrieve API Guide.Creating File and Key Specification Structures
When you use the Create operation, you pass in a data buffer that contains file and key specification structures. The following structure uses the example employee data file.
Table 11 Sample Data Buffer for File and Key Specifications Using BTRV Entry Point
Description | Data Type1 | Byte # | Example Value2 |
File Specification |
Logical Fixed Record Length. (Size of all fields combined: 25 + 25 + 1 + 4 + 13 + 4). For instructions, see
Calculating the Logical Record Length.3 | Short Int4 | 0–1 | 72 |
Page Size. | File Format | Short Int | 2–3 | |
6.0-9.0 | 512 |
6.0 and later | 1024 |
6.0-9.0 | 1536 |
6.0 and later | 2048 |
6.0-9.0 | 3072 |
3584 |
6.0 and later | 4096 |
9.0 and later | 8192 |
9.5 and later | 16384 |
A minimum size of 4096 bytes works best for most files. If you want to fine-tune this, see
Choosing a Page Size for more information. 6.0 to 8.0 file formats support page sizes of 512 times x, where x is any number up to the product 4096. 9.0 file format supports page sizes identical to previous versions except that it also supports a page size of 8192. 9.5 file format supports page sizes of 1024 times 2 0 thru 4. In creating 9.5 format files, if the logical page size specified is valid for the file format, the MicroKernel rounds the specified value to the next higher valid value if one exists. For all other values and file formats, the operation fails with status 24. No rounding is done for the older file formats. |
Number of Keys. (Number of keys in the file: 2) | Byte | 4 | 2 |
File Version | Byte | 5 | 0x60 | Version 6.0 |
0x70 | Version 7.0 |
0x80 | Version 8.0 |
0x90 | Version 9.0 |
0x95 | Version 9.5 |
0xD0 | Version 13.0 |
0x00 | Use database engine default |
Reserved. (Not used during a Create operation.) | Reserved | 6–9 | 0 |
File Flags. Specifies the file attributes. The example file does not use any. | Short Int | 10–11 | 0 |
Number of Extra Pointers. Sets the number of duplicate pointers to reserve for future key additions. Used if the file attributes specify Reserve Duplicate Pointers. | Byte | 12 | 0 |
Physical page size. Used when compression flag is set. Value is the number of 512-byte blocks. | Byte | 13 | 0 |
Preallocated Pages. Sets the number of pages to preallocate. Used if the file attributes specify Page Preallocation. | Short Int | 14–15 | 0 |
Key Specification for Key 0 (Last Name) |
Key Position. Provides the position of the first byte of the key within the record. The first byte in the record is 1. | Short Int | 16–17 | 1 |
Key Length. Specifies the length of the key, in bytes. | Short Int | 18–19 | 25 |
Key Flags. Specifies the key attributes. | Short Int | 20–21 | EXTTYPE_KEY + NOCASE_KEY + DUP + MOD |
Not Used for a Create. | Byte | 22–25 | 0 |
Extended Key Type. Used if the key flags specify Use Extended Key Type. Specifies one of the extended data types. | Byte | 26 | ZSTRING |
Null Value (legacy nulls only). Used if the key flags specify Null Key (All Segments) or Null Key (Any Segment). Specifies an exclusion value for the key. See
Null Value for more conceptual information on legacy nulls and true nulls. | Byte | 27 | 0 |
Not Used for a Create. | Byte | 28–29 | 0 |
Manually Assigned Key Number. Used if the file attributes specify Key Number. Assigns a key number. | Byte | 30 | 0 |
ACS Number. Used if the key flags specify Use Default ACS, Use Numbered ACS in File, or Use Named ACS. Specifies the ACS number to use. | Byte | 31 | 0 |
Key Specification for Key 1 (Employee ID) |
Key Position. (Employee ID starts at first byte after Middle Initial.) | Short Int | 32–33 | 52 |
Key Length. | Short Int | 34–35 | 4 |
Key Flags. | Short Int | 36–37 | EXTTYPE_KEY + MOD |
Not Used for a Create. | Byte | 38–41 | 0 |
Extended Key Type. | Byte | 42 | INTEGER |
Null Value. | Byte | 43 | 0 |
Not Used for a Create. | Byte | 44–45 | 0 |
Manually Assigned Key Number. | Byte | 46 | 0 |
ACS Number. | Byte | 47 | 0 |
Key Specification for Page Compression |
Physical Page Size5 | Char | A | 512
(default value) |
1Unless specified otherwise, all data types are unsigned. 2For simplification, the non-numeric example values are for C applications. 3For files with variable-length records, the logical record length refers only to the fixed-length portion of the record. 4Short Integers (Short Int) must be stored in little-endian byte order, which is the low-to-high ordering of Intel-class computers. 5Only used with page level compression. Must be used in conjunction with the Page Compression file flag (see
Key Flag Values). See also
Creating a File with Page Level Compression for more information. |
Creating a File with Page Level Compression
For PSQL 9.5 and later, you can use Create (14) to create data files with page level compression. For earlier data files, logical pages map to physical pages, and this mapping is stored in a Page Allocation Table (PAT). A physical page is exactly the same size as a logical page.
When a file is compressed, each logical page is compressed into one or more physical page units that are smaller in size than a logical page. The physical page size is specified by the Physical Page Size attribute (see Table
11).
The Page Compression file flag (see
Key Flag Values) is used in conjunction with the Physical Page Size key specification to tell the MicroKernel to create the new data file with page level compression turned on. The logical and physical page sizes are validated as follows:
The value specified for the physical page size cannot be larger than the value specified for the logical page size. If it is then the MicroKernel will round down the value specified for the physical page size so that it is the same as the logical page size. The logical page size needs to be an exact multiple of the physical page size. If it is not then the logical page size is rounded down so that it becomes an exact multiple of the physical page size. If, as a result of these manipulations, the logical and physical values end up to be the same, then page level compression will not turned on for this file.
Calling the Create Operation
Create (14) requires the following values:
•Operation code, which is 14 for a Create.
•Data buffer containing the file and key specifications.
•Length of the data buffer.
•Key buffer containing the full path for the file.
•Key number containing a value to determine whether the MicroKernel Engine warns you if a file of the same name already exists (-1 = warning, 0 = no warning).
In C, the API call would resemble the following:
Create Operation
/* define the data buffer structures */
/*The following three structures need to have 1-byte alignment for their fields. This can be done either through compiler pragmas or through compiler options. */
typedef struct
{
BTI_SINT recLength;
BTI_SINT pageSize;
BTI_SINT indexCount;
BTI_CHAR reserved[4];
BTI_SINT flags;
BTI_BYTE dupPointers;
BTI_BYTE notUsed;
BTI_SINT allocations;
} FILE_SPECS;
typedef struct
{
BTI_SINT position;
BTI_SINT length;
BTI_SINT flags;
BTI_CHAR reserved[4];
BTI_CHAR type;
BTI_CHAR null;
BTI_CHAR notUsed[2];
BTI_BYTE manualKeyNumber;
BTI_BYTE acsNumber;
} KEY_SPECS;
typedef struct
{
FILE_SPECS fileSpecs;
KEY_SPECS keySpecs[2];
} FILE_CREATE_BUF;
/* populate the data buffer */
FILE_CREATE_BUF dataBuf;
memset (dataBuf, 0, size of (databuf)); /* initialize databuf */
dataBuf.recLength = 72;
dataBuf.pageSize = 4096;
dataBuf.indexCount = 2;
dataBuf.keySpecs[0].position = 1;
dataBuf.keySpecs[0].length = 25;
dataBuf.keySpecs[0].flags = EXTTYPE_KEY + NOCASE_KEY + DUP + MOD;
dataBuf.keySpecs[0].type = ZSTRING;
dataBuf.keySpecs[1].position = 52;
dataBuf.keySpecs[1].length = 4;
dataBuf.keySpecs[1].flags = EXTTYPE_KEY;
dataBuf.keySpecs[1].type = INTEGER;
/* create the file */
strcpy((BTI_CHAR *)keyBuf, "c:\\sample\\sample2.mkd");
dataLen = sizeof(dataBuf);
status = BTRV(B_CREATE, posBlock, &dataBuf, &dataLen, keyBuf, 0);
Create Index Operation
If you create files with predefined keys, the indexes are populated with each insert, update, or delete. This is necessary for most database files. However, there is a class of database files that are fully populated before being read. These include temporary sort files and fully populated files that are delivered as part of a product.
For these files, it may be faster to build the keys with Create Index (31) after the records are written. The file should be created with no index defined so that inserting records can be accomplished faster. Then the Create Index operation will sort the keys and build the indexes in a more efficient manner.
Indexes created this way are also more efficient and provide faster access. There is no need for the MicroKernel Engine to leave empty space at the end of each page during a Create Index (31) because the index pages are loaded in key order. Each page is filled to nearly 100%. In contrast, when an Insert (2) or Update (3) operation fills an index page, the page is split in half, with half of the records being copied to a new page. This process causes the average index page to be about 50 to 65 percent full. If index balancing is used, it may be 65 to 75 percent full.
Another advantage of Create Index (31) is that all the new index pages created are located close together at the end of the file. For large files, this means less distance for the read head to cover between reads.
This technique may not be faster when files are small, such as a few thousand records. The file would also need larger index fields to benefit. Moreover, if all index pages can fit into the MicroKernel Engine cache, this method shows no improvement in speed. But if only a small percentage of the index pages are in cache at any one time, this method saves a lot of extra index page writes. This technique can greatly reduce the time needed to build a file with many records. The greater the number of index pages in the file, the faster it is to build indexes with Create Index (31) than it is one record insert at a time.
In summary, the critical thing to avoid in loading a PSQL file from scratch is not enough cache memory to hold all the index pages. If this is the case, use Create (14) to create the file without indexes and use Create Index (31) when all the data records have been inserted.
See Btrieve API Guide for detailed information on these operations.
Calculating the Logical Record Length
You must supply the logical record length to Create (14). The logical record length is the number of bytes of fixed-length data in the file. To obtain this value, calculate how many bytes of data you need to store in the fixed-length portion of each record.
For example, the following table shows how the data bytes in the example Employees file are added together to obtain a logical record length.
Field | Length (in Bytes) |
Last Name | 25 |
First Name | 25 |
Middle Initial | 1 |
Employee ID | 4 |
Phone Number | 13 |
Pay Rate | 4 |
Logical Record Length | 72 |
In calculating the logical record length, you do not count variable-length data, because variable-length information is stored apart from the fixed-length record in the file (on variable pages).
The maximum logical record length depends on the file format as defined in the following table.
Table 12 Maximum Logical Record Length by File Format
PSQL Version | Example |
13.0 | page size minus 18 minus 2 (record overhead) |
9.5 | page size minus 10 minus 2 (record overhead) |
8.x through 9.x | page size minus 8 minus 2 (record overhead) |
6.x through 7.x | page size minus 6 minus 2 (record overhead) |
Pre-6.x | page size minus 6 minus 2 (record overhead) |
Note: The record overhead in these examples is for a fixed-length record (not a variable record) without record compression. |
Choosing a Page Size
All pages in a data file are the same size. Therefore, when you determine the size of the pages in your file, you must answer the following questions:
•What is the optimum size for data pages, which hold the fixed-length portion of records to reduce wasted bytes.
•What is the smallest size that allows index pages to hold your largest key definition? (Even if you do not define keys for your file, the MicroKernel Engine adds a key if the Transaction Durability feature is enabled.)
The following topics guide you through answering these questions. With your answers, you can select a page size that best fits your file.
Optimum Page Size For Minimizing Disk Space
Before you can determine the optimum page size for your file, you must first calculate the file’s
physical record length. The physical record length is the sum of the logical record length and the overhead required to store a record on a data page of the file. For more generalized information about page size, see
Page Size.
The MicroKernel Engine always stores a minimum of 2 bytes of overhead information in every record as a usage count for that record. The MicroKernel Engine also stores an additional number of bytes in each record, depending on how you define the records and keys in your file.
The following table shows how many bytes of record overhead required without record compression, depending on the characteristics of your file.
Table 13 Record Overhead in Bytes Without Record Compression
File Characteristic | File Format |
6.x | 7.x | 8.x | 9.0, 9.5, 13.0 |
Usage Count | 2 | 2 | 2 | 2 |
Duplicate Key (per key) | 8 | 8 | 8 | 8 |
Variable Pointer (with variable record) | 4 | 4 | 6 | 6 |
Record Length (if VATs1 used) | 4 | 4 | 4 | 4 |
Blank Truncation Use (without VATs/with VATs) | 2/4 | 2/4 | 2/4 | 2/4 |
System Data | NA2 | 8 | 8 | 8 |
1VAT: variable-tail allocation table
2NA: not applicable |
The following table shows how many bytes of record overhead required when using record compression, depending on the characteristics of your file.
Table 14 Record Overhead in Bytes With Record Compression
File Characteristic | File Format |
6.x | 7.x | 8.x | 9.0, 9.5, 13.0 |
Usage Count | 2 | 2 | 2 | 2 |
Duplicate Key (per key) | 8 | 8 | 8 | 8 |
Variable Pointer | 4 | 4 | 6 | 6 |
Record Length (if VATs1 used) | 4 | 4 | 4 | 4 |
Record Compression Flag | 1 | 1 | 1 | 1 |
System Data | NA2 | 8 | 8 | 8 |
1VAT: variable-tail allocation table
2NA: not applicable |
The following table shows how many bytes of page overhead are required depending on the page type.
Table 15 Page Overhead in Bytes
Page Type | File Format |
6.x | 7.x | 8.x | 9.0 | 9.5 | 13.0 |
Data | 6 | 6 | 8 | 8 | 10 | 18 |
Index | 12 | 12 | 14 | 14 | 16 | 24 |
Variable | 12 | 12 | 16 | 16 | 18 | 26 |
The following table shows how many bytes of overhead you must add to the logical record length to obtain the physical record length (based on how you define the records and keys for your file). You can also find a summary of this record overhead information in Table
13 and Table
14.
Table 16 Physical Record Length Worksheet
Task Description | Example |
1 | Determine the logical record length. For instructions, see
Calculating the Logical Record Length. The example file for this worksheet uses a logical record length of 72 bytes. For files with variable-length records, the logical record length refers only to the fixed-length portion of the record. | 72 |
2 | Add 2 for the record usage count. For a compressed record’s entry, you need to add the usage count plus the variable pointer plus the record compression flag: 6.x and 7.x: 7 bytes (2 + 4 + 1)
8.x and later: 9 bytes (2 + 6 + 1) | 72 + 2 = 74 |
3 | For each linked-duplicatable key, add 8. When calculating the number of bytes for duplicatable keys, the MicroKernel Engine does not allocate duplicate pointer space for keys defined as repeating duplicatable at creation time. By default, keys that allow duplicates created at file creation time are linked-duplicate keys. For a compressed record’s entry, add 9 (nine) for pointers for duplicate keys. The example file has one linked-duplicatable key. | 74 + 8 = 82 |
4 | For each reserved duplicate pointer, add 8. The example file has no reserved duplicate pointers. | 82 + 0 = 82 |
5 | If the file allows variable-length records, add 4 for pre-8.x files and 6 for 8.x or later files. The example file does not allow variable-length records. | 82 + 0 = 82 |
6 | If the file uses VATs, add 4. The example file does not use VATs. | 82 + 0 = 82 |
7 | If the file uses blank truncation, add one of the following: •2 if the file does not use VATs •4 if the file uses VATs. The example file does not use blank truncation. | 82 + 0 = 82 |
8 | If the file uses system data to create a system key, add 8. The example file does not use system data. | 82 + 0 = 82 |
| Physical Record Length | 82 |
Using the physical record length, you now can determine the file’s optimum page size for data pages.
The MicroKernel Engine stores the fixed length portion of a data record in the data pages; however, it does not break the fixed-length portion of a record across pages. Also, in each data page, the MicroKernel Engine stores overhead information (see Tables
13 and
14). You must account for this additional overhead when determining the page size.
A file contains unused space if the page size you choose minus the overhead information amount is not an exact multiple of the physical record length. You can use the formula to find an efficient page size:
Unused bytes = (Page Size minus Data Page Overhead per Table
13 and Table
14) mod (Physical Record Length)
To optimize your file’s use of disk space, select a page size that can buffer your records with the least amount of unused space. The supported page size varies with the file format. See Table
17. If the internal record length (user data + record overhead) is small and the page size is large, the wasted space could be substantial.
Optimum Page Size Example
Consider an example where the physical record length is 194 bytes. The following table shows how many records can be stored on a page and how many bytes of unused space remain for each possible page size.
Table 17 Physical Record Length Example: 194 Bytes
Applicable File Format | Page Size | Records per Page | Unused Bytes |
Pre-8.x | 512 | 2 | 118 | (512 – 6) mod 194 |
8.x through 9.0 | 116 | (512 – 8) mod 194 |
Pre-8.x | 1024 | 5 | 48 | (1024 – 6) mod 194 |
8.x through 9.0 | 46 | (1024 – 8) mod 194 |
9.5 | 44 | (1024 – 10) mod 194 |
Pre-8.x | 1536 | 7 | 172 | (1536 – 6) mod 194 |
8.x through 9.0 | 172 | (1536 – 6) mod 194 |
Pre-8.x | 2048 | 10 | 102 | (2048 – 6) mod 194 |
8.x through 9.0 | 100 | (2048 – 8) mod 194 |
9.5 | 98 | (2048 – 10) mod 194 |
Pre-8.x | 2560 | 13 | 32 | (2560 – 6) mod 194 |
8.x through 9.0 | 32 | (2560 – 6) mod 194 |
Pre-8.x | 3072 | 15 | 156 | (3072 – 6) mod 194 |
8.x through 9.0 | 156 | (3072 – 6) mod 194 |
Pre-8.x | 3584 | 18 | 86 | (3584 – 6) mod 194 |
8.x through 9.0 | 86 | (3584 – 6) mod 194 |
Pre-8.x | 4096 | 21 | 16 | (4096 – 6) mod 194 |
8.x through 9.0 | 14 | (4096 – 8) mod 194 |
9.5 | 12 | (4096 – 10) mod 194 |
13.0 | 4 | (4096 – 18) mod 194 |
9.0 | 8192 | 42 | 36 | (8192 – 8) mod 194 |
9.5 | 34 | (8192 – 10) mod 194 |
13.0 | 26 | (8192 – 18) mod 194 |
9.5 | 16384 | 84 | 78 | (16384 – 10) mod 194 |
13.0 | 70 | (16384 – 18) mod 194 |
For planning purposes, note that page and record overhead may rise in future file formats. Given a current file format, a record size that exactly fits on a page may require a larger page size the future. Also note that the database engine automatically upgrades the page size if the record and overhead cannot fit within a specified page size. For example, if you specify a page size of 4096 for a 9.x file, but the record and overhead requirement is 4632, then the engine will use a page size of 8192.
As the table above indicates, if you select a page size of 512, only 2 records can be stored per page and 114 to 118 bytes of each page are unused depending on the file format. However, if you select a page size of 4096, 21 records can be stored per page and only 16 bytes of each page are unused. Those same 21 records would result in over 2 KB of lost space with a page size of 512.
If you have a very small physical record length, most page sizes will result in very little wasted space. However, pre-8.x file versions have a maximum limit of 256 records per page. In that case, if you have a small physical record length, and if you choose a larger page size (for example, 4096 bytes), it will result in a large amount of wasted space. For example, Table
18 shows the behavior of 14 byte record length for a pre-8.x file version.
Table 18 Example of Pre-8.x File Versions: Record Length 14 Bytes
Page Size | Records per Page | Unused Bytes |
512 | 36 | 2 | (512 – 6) mod 14 |
1024 | 72 | 10 | (1024 – 6) mod 14 |
1536 | 109 | 4 | (1536 – 6) mod 14 |
2048 | 145 | 12 | (2048 – 6) mod 14 |
2560 | 182 | 6 | (2560 – 6) mod 14 |
3072 | 219 | 0 | (3072 – 6) mod 14 |
3584 | 255 | 8 | (3584 – 6) mod 14 |
4096 | 256 | 506 | (4096 – 6) mod 14 |
Minimum Page Size
The page size you choose must be large enough to hold eight key values (plus overhead). To find the smallest page size allowable for your file, add the values specified in Table
19.
The table uses a 9.5 file format as an example.
Table 19 Minimum Page Size Worksheet
Task Description | Example |
1 | Determine the size of the largest key in the file, in bytes. (Using the example Employee file, the largest key is 25 bytes.) In files that do not have a unique key defined, the system-defined log key (also called system data) may be the largest key. Its size is 8 bytes. | 25 |
2 | Add one of the following: •For keys that do not allow duplicates or that use repeating duplicates, add 8 bytes. •For keys that use linked duplicates, add 12 bytes. (This example uses linked duplicates.) | 25 + 12 = 37 |
3 | Multiply the result by 8. (The MicroKernel Engine requires room for a minimum of 8 keys on a page.) | 37 * 8 = 296 |
4 | Add index page overhead for the file format: See entry for Index pages in Table
15. | 296 + 16 = 312 |
MINIMUM PAGE SIZE | 312 bytes |
Select any valid page size that is equal to or greater than the result. Remember that the page size you select must accommodate the size of any keys created after file creation. The total number of key segments may dictate the minimum page size. For example, you can only have eight key segments defined in a file using a 512 page size.
Table 20 Minimum Page Size Worksheet
Page Size | Number of Key Segments by File Version |
6.x and 7.x | 8.x | 9.0 | 9.5 | 13.0 |
512 | 8 | 8 | 8 | n/a | n/a |
1024 | 23 | 23 | 23 | 97 | 97 |
1536 | 24 | 24 | 24 | n/a | n/a |
2048 | 54 | 54 | 54 | 97 | 97 |
2560 | 54 | 54 | 54 | n/a | n/a |
3072 | 54 | 54 | 54 | n/a | n/a |
3584 | 54 | 54 | 54 | n/a | n/a |
4096 | 119 | 119 | 119 | 204 | 204 |
8192 | n/a | n/a | 119 | 420 | 420 |
16384 | n/a | n/a | n/a | 420 | 420 |
“n/a” stands for “not applicable” |
Estimating File Size
You can estimate the number of pages, and therefore the number of bytes required to store a file. However, when using the formulas, consider that they only approximate file size because of the way the MicroKernel Engine dynamically manipulates pages.
Note The following discussion and the formulas for determining file size do not apply to files that use data compression, because the record length for those files depends on the number of repeating characters in each record.
While the formulas are based on the maximum storage required, they assume that only one task is updating or inserting records into the file at a time. File size increases if more than one task updates or inserts records into the file during simultaneous concurrent transactions.
The formulas also assume that no records have been deleted yet from the file. You can delete any number of records in the file, and the file remains the same size. The MicroKernel Engine does not deallocate the pages that were occupied by the deleted records. Rather, the MicroKernel Engine reuses them as new records are inserted into the file (before allocating new pages).
If the final outcome of your calculations contains a fractional value, round the number to the next highest whole number.
Formula and Derivative Steps
The following formula is use to calculate the maximum number of bytes required to store the file. The “see step” references are to the steps following the formula that explain the individual components of the formula.
File size in bytes =
(page size * (number of data pages [see step
1]
+
number of index pages [see step
2]
+
number of variable pages [see step
3]
+
number of other pages [see step
4]
+
number of shadow pool pages [see step
5]
)) + (special page size [see step
6]
*
(number of PAT pages [see step
7]
+
number of FCR pages + number of reserved pages [see step
8]
)) Determining file size requires that you account for two different categories of pages. The standard page category includes the pages when a data file is first created (see also
Create (14) in
Btrieve API Guide). In addition, the formula must account for special (nonstandard) pages as listed in Table
21. The special pages are not always a multiple of the file page size.
1 Calculate the number of data pages using the following formula.
Number of data pages =
#r /
( (PS - DPO) / PRL )
where:
•#r is the number of records
•PS is the page size
•DPO is the data page overhead (see Table
15)
•PRL is the physical record length (see Table
16)
2 Calculate the number of index pages for each defined key using one of the following formulas.
For each index that does not allow duplicates or that allows repeating-duplicatable keys:
Number of index pages =
( #r /
( (PS - IPO) / (KL + 8) ) ) * 2
where:
•#r is the number of records
•PS is the page size
•IPO is the index page overhead (see Table
15)
•KL is the key length
For each index that allows linked-duplicatable keys:
Number of index pages =
( #UKV /
( (PS - IPO) / (KL + 12) ) ) * 2
where:
•#UKV is the number of unique key values
•PS is the page size
•IPO is the index page overhead (see Table
15)
•KL is the key length
The B-tree index structure guarantees at least 50 percent usage of the index pages. Therefore, the index page calculations multiply the minimum number of index pages required by 2 to account for the maximum size.
3 If your file contains variable-length records, calculate the number of variable pages using the following formula:
Number of variable pages =
(AVL * #r) / (1 - (FST + (VPO/PS))
where:
•AVL is the average length of the variable portion of a typical record
•#r is the number of records
•FST is the free space threshold specified when the file is created (see also
Create (14) in
Btrieve API Guide)
•VPO is the variable page overhead (see Table
15)
•PS is the page size
Note You can gain only a very rough estimate of the number of variable pages due to the difficulty in estimating the average number of records whose variable-length portion fit on the same page.
4 Calculate the number for any other regular pages:
•1 page for each alternate collating sequence used (if any)
•1 page for a referential integrity (RI) page if the file has RI constraints.
The sum of steps
1,
2,
3, and
4 represents the estimated total number of logical pages that the file will contain.
5 Calculate the estimated number of pages in the shadow page pool. The database engine uses a pool for shadow paging. Use the following formula to estimate the number of pages in the pool:
Size of the shadow page pool = (number of keys + 1) * (average number of inserts, updates, and deletes) * (number of concurrent transactions)
This formula applies if tasks execute insert, update, and delete operations outside transactions. If tasks are executing these operations inside transactions, multiply the average number of insert, update, and delete operations expected in the inside transactions times the outside-transactional value determined by the formula. You must further increase the estimated size of the pool of unused pages if tasks are executing simultaneous concurrent transactions.
6 Determine special page size from Table
21 by referencing file version and data page size. Depending on the file format version, the pages sizes for FCR, reserved, and PAT pages are different from the normal pages sizes for data, index, and variable pages.
Table 21 Page Sizes of Special Pages by File Format
Normal
Page Size | File Format
v6.x and 7.x | File Format 8.x | File Format
9.0 through 9.4 | File Format
9.5, 13.0 |
SpecialPage Size | PAT Page Entries | Special Page Size | PAT Page Entries | Special Page Size | PAT Page Entries | Special Page Size | PAT Page Entries |
512 | 512 | n/a | 2048 | 320 | 2048 | 320 | n/a | n/a |
1024 | 1024 | n/a | 2048 | 320 | 2048 | 320 | 4096 | 480 |
1536 | 1536 | n/a | 3072 | 480 | 3072 | 480 | n/a | n/a |
2048 | 2048 | n/a | 4096 | 640 | 4096 | 640 | 4096 | 480 |
2560 | 2560 | n/a | 5120 | 800 | 5120 | 800 | n/a | n/a |
3072 | 3072 | n/a | 6144 | 960 | 6144 | 960 | n/a | n/a |
3584 | 3584 | n/a | 7168 | 1120 | 7168 | 1120 | n/a | n/a |
4096 | 4096 | n/a | 8192 | 1280 | 8192 | 1280 | 8192 | 1280 |
8192 | n/a | n/a | n/a | n/a | n/a | n/a | 16384 | 16000 |
16384 | n/a | n/a | n/a | n/a | n/a | n/a | 16384 | 16000 |
“n/a” stands for “not applicable” |
7 Calculate the number of Page Allocation Table (PAT) pages.
Every file has a minimum of two PAT pages. To calculate the number of PAT pages in a file, use one of the following formulas:
For pre-8.x file formats:
For 8.x or later file formats:
For number of PAT entries, see Table
21 and look up file version and data page size.
8 Include 2 pages for the file control record (FCR) pages (see also
File Control Record (FCR)). If you are using 8.
x or later file format, also include 2 pages for the reserved pages.
Optimizing Your Database
The MicroKernel Engine provides several features that allow you to conserve disk space and improve system performance. These features include the following:
Duplicatable Keys
If you define a key to be duplicatable, the MicroKernel Engine allows more than one record to have the same value for that key. Otherwise, each record must have a unique value for the key. If one segment of a segmented key is duplicatable, all the segments must be duplicatable.
Linked-Duplicatable Keys
By default in a v7.0 or later file, the MicroKernel Engine stores duplicatable keys as linked-duplicatable keys. When the first record with a duplicate key value is inserted into a file, the MicroKernel Engine stores the key value on an index page. The MicroKernel Engine also initializes two pointers to identify the first and last record with this key value. Additionally, the MicroKernel Engine stores a pair of pointers at the end of the record on the data page. These pointers identify the previous and next record with the same key value. When you create a file, you can reserve pointers for use in creating linked-duplicatable keys in the future.
If you anticipate adding duplicatable keys after you create a data file and you want the keys to use the linked-duplicatable method, you can preallocate space for pointers in the file.
Repeating-Duplicatable Keys
If no room is available to create a linked-duplicatable key (that is, if no duplicate pointers are available), the MicroKernel Engine creates a repeating-duplicatable key. The MicroKernel Engine stores every key value of a repeating-duplicatable key both on a data page and on an index page. In other words, the key’s value resides in the record on a data page and is repeated in the key entry on an index page.
Note For users of pre-6.0 Btrieve, the term linked-duplicatable corresponds to permanent, and the term repeating-duplicatable corresponds to supplemental.
You can define a key as a repeating-duplicatable key by setting bit 7 (0x80) of the key flags in the key specification block on a Create (14) or Create Index (31) operation. Before 6.10, you could not define a key to be a repeating-duplicatable key, and bit 7 of the key flags was not user-definable. In 6.0 and later, the Stat (15) operation sets bit 7 if no room is available to create a linked-duplicatable key (and therefore, if the MicroKernel Engine has to create the key as a repeating-duplicatable key).
Files that use the 5.x format use this same key flag (called the supplemental key attribute in 5.x) to designate that a key was created with the 5.x Create Supplemental Index (31) operation.
Note In pre-6.0 files, you can drop supplemental indexes only. Permanent indexes, as their name implies, cannot be dropped. In 6.0 and later files, you can drop any index.
Linked vs. Repeating
Each method has performance advantages:
•Linked-duplicatable keys provide faster lookup, because the MicroKernel Engine reads fewer pages.
•Repeating-duplicatable keys result in fewer index page conflicts when multiple users access the same page concurrently.
There are trade-offs in performance between linked-duplicate keys and repeating-duplicate keys. Generally, if the average number of duplicates of a key is two or more, a linked-duplicate key will take up less space on the disk and searches will be generally faster because there are fewer index pages. However, the opposite is true if your file stores very few records with duplicate keys and the key length is very short. This is because an entry in the linked-duplicatable tree requires 8 bytes for pointers, whereas a repeating-duplicatable key entry requires 4.
If only a small percentage of keys have any duplicates, it is advantageous to use repeating-duplicate keys to save the extra 8 bytes in each data record. There is no noticeable performance advantage to either choice when the average number of duplicates of a key is less than two.
If you expect several concurrent transactions to be active on the same file at the same time, repeating-duplicate keys will provide a greater probability that these transactions do not try to access the same pages. All pages involved in writes during a concurrent transaction have implicit locks on them. When a page is required in order to make a change during a concurrent transaction and the page is involved in another concurrent transaction, the MicroKernel Engine might wait until the other transaction is complete. If these kind of implicit waits happen very often, the performance of the application goes down.
Neither key storage method is recommended as a shortcut for tracking chronological order. For linked-duplicatable keys, the MicroKernel Engine does maintain the chronological order of records that are inserted after the key is created, but if you rebuild the key’s index, the chronological order is lost. For repeating-duplicatable keys, the MicroKernel Engine maintains the chronological order of the records only if there was no record deletion between the time the key is built and a new record is inserted. To track chronological order, use an AUTOINCREMENT data type on the key.
Page Preallocation
Preallocation guarantees that disk space is available when the MicroKernel Engine needs it. The MicroKernel Engine allows you to preallocate up to 65535
pages to a file when you create a data file. Table
22 shows the maximum number of
bytes the MicroKernel Engine allocates for a file of each possible page size, assuming you allocate 65535 full pages of disk space.
Table 22 Disk Space Allocation based on Page Size
Page Size | Disk Space Allocated1 |
512 | 33,553,920 |
1024 | 67,107,840 |
1536 | 100,661,760 |
2048 | 134,215,680 |
2560 | 167,769,600 |
3072 | 201,323,520 |
3584 | 243,877,440 |
4096 | 268,431,360 |
8192 | 536,862,720 |
16384 | 1,073,725,440 |
1Value is page size multiplied by 65535 |
If not enough space exists on the disk to preallocate the number of pages you specify, the MicroKernel Engine returns status code 18 (disk full) and does not create the file.
The speed of file operations can be enhanced if a data file occupies a contiguous area on the disk. The increase in speed is most noticeable on very large files. To preallocate contiguous disk space for a file, the device on which you are creating the file must have the required number of bytes of contiguous free space available. The MicroKernel Engine preallocates the number of pages you specify, whether or not the space on the disk is contiguous.
Use the formulas described earlier in this chapter to determine the number of data and index pages the file requires. Round any remainder from this part of the calculation to the next highest whole number.
When you preallocate pages for a file, that file actually occupies that area of the disk. No other data file can use the preallocated area of disk until you delete or replace that file.
As you insert records, the MicroKernel Engine uses the preallocated space for data and indexes. When all the preallocated space for the file is in use, the MicroKernel Engine expands the file as new records are inserted.
When you issue Stat (15), the MicroKernel Engine returns the difference between the number of pages you allocated at the time you created the file and the number of pages that the MicroKernel Engine currently has in use. This number is always less than the number of pages you specify for preallocation because the MicroKernel Engine considers a certain number of pages to be in use when a file is created, even if you have not inserted any records.
Once a file page is in use, it remains in use even if you delete all the records stored on that page. The number of unused pages that the Stat operation returns never increases. When you delete a record, the MicroKernel Engine maintains a list of free space in the file and reuses the available space when you insert new records.
Even if the number of unused pages that the Stat operation returns is zero, the file might still have free space available. The number of unused pages can be zero if one of the following is true:
•You did not preallocate any pages to the file.
•All the pages that you preallocated were in use at one time or another.
Blank Truncation
If you choose to truncate blanks, the MicroKernel Engine does not store any trailing blanks (ASCII Space code 32 or hexadecimal 0x20) in the variable-length portion of the record when it writes the record to a file. Blank truncation has no effect on the fixed-length portion of a record. The MicroKernel Engine does not remove blanks that are embedded in the data.
When you read a record that contains truncated trailing blanks, the MicroKernel Engine expands the record to its original length. The value the MicroKernel Engine returns in the Data Buffer Length parameter includes any expanded blanks. Blank truncation adds either 2 bytes or 4 bytes of overhead to the physical size of the record (stored with the fixed-record portion): 2 if the file does not use VATs, 4 if it does.
Record Compression
When you create a file, you can specify whether you want the MicroKernel Engine to compress the data records when it stores them in the file. Record compression can result in a significant reduction of the space needed to store records that contain many repeating characters. The MicroKernel Engine compresses five or more of the same contiguous characters into 5 bytes.
Consider using record compression in the following circumstances:
•The records to be compressed are structured so that the benefits of using compression are maximized.
•The need for better disk utilization outweighs the possible increased processing and disk access times required for compressed files.
•The computer running the MicroKernel Engine can supply the extra memory that the MicroKernel Engine uses for compression buffers.
Note The database engine automatically uses record compression on files that use system data and have a record length that exceeds the maximum length allowed. See Table
8.
When you perform record I/O on compressed files, the MicroKernel Engine uses a compression buffer to provide a block of memory for the record compression and expansion process. To ensure sufficient memory to compress or expand a record, the MicroKernel Engine requires enough buffer space to store twice the length of the longest record your task inserts into the compressed file. This requirement can have an impact on the amount of free memory remaining in the computer after the MicroKernel Engine loads. For example, if the longest record your task writes or retrieves is 64 KB long, the MicroKernel Engine requires 128 KB of memory to compress and expand that record.
Note If your file uses VATs, the MicroKernel Engine’s requirement for buffer space is the product of 16 times the file’s page size. For example, on a 4 KB record, 64 KB of memory are required to compress and expand the record.
Because the final length of a compressed record cannot be determined until the record is written to the file, the MicroKernel Engine always creates a compressed file as a variable-length record file. In the data page, the MicroKernel Engine stores either 7 bytes (if the file does not use VATs) or 11 bytes (if it does), plus an additional 8 bytes for each duplicate key pointer. The MicroKernel Engine then stores the record on the variable page. Because the compressed images of the records are stored as variable-length records, individual records may become fragmented across several file pages if your task performs frequent inserts, updates, and deletes. The fragmentation can result in slower access times because the MicroKernel Engine may need to read multiple file pages to retrieve a single record.
The record compression option is most effective when each record has the potential for containing a large number of repeating characters. For example, a record may contain several fields, all of which may be initialized to blanks by your task when it inserts the record into the file. Compression is more efficient if these fields are grouped together in the record, rather than being separated by fields containing other values.
To use record compression, the file must have been created with the compression flag set. Key-only files do not allow compression.
Index Balancing
The MicroKernel Engine allows you to further conserve disk space by employing index balancing. By default, the MicroKernel Engine does not use index balancing, so that each time a current index page is filled, the MicroKernel Engine must create a new index page. When index balancing is active, the MicroKernel Engine can frequently avoid creating a new index page each time a current index page is filled. Index balancing forces the MicroKernel Engine to look for available space on adjoining index pages. If space is available on one of those pages, the MicroKernel Engine moves keys from the full index page to the page with free space.
The balancing process not only results in fewer index pages but also produces more densely populated indexes, better overall disk usage, and faster response on most read operations. If you add keys to the file in sorted order, index page usage increases from 50 percent to nearly 100 percent when you use index balancing. If you add keys randomly, the minimum index page usage increases from 50 percent to 66 percent.
On insert and update operations, the balancing logic requires the MicroKernel Engine to examine more pages in the file and might possibly require more disk I/O. The extra disk I/O slows down file updates. Although the exact effects of balancing indexes vary in different situations, using index balancing typically degrades performance on write operations by about 5 to 10 percent.
The MicroKernel Engine allows you to fine-tune your MicroKernel Engine environment by offering two ways to turn on index balancing: at the engine level or at the file level. If you specify the Index Balancing configuration option during setup, the MicroKernel Engine applies index balancing to every file. For a description of how to specify the Index Balancing configuration option, see PSQL User's Guide.
You can also designate that only specific files are to be index balanced. To do so, set bit 5 (0x20) of the file’s file flags at creation time. If the index Balancing configuration option is off when the MicroKernel Engine is started, the MicroKernel Engine applies index balancing only to indexes on files that have bit 5 of the file flags set.
The MicroKernel Engine ignores bit 5 in all files’ file flags if the index balancing configuration option was on when the MicroKernel Engine was started. In this situation, the MicroKernel Engine applies index balancing to every file.
Files remain compatible regardless of whether index balancing is active. Also, you do not have to specify index balancing to access files that contain balanced index pages. If you turn on the MicroKernel Engine’s index balancing option, index pages in existing files are not affected until they become full. The MicroKernel Engine does not rebalance indexes on existing files as a result of enabling this option. Similarly, turning off the index balancing option does not affect existing indexes. Whether this option is on or off determines how the MicroKernel Engine handles full index pages.
Variable-tail Allocation Tables
Variable-tail allocation tables give the MicroKernel Engine faster access to data residing at large offsets in very large records and significantly reduce the buffer sizes the MicroKernel Engine needs when processing records in files that use data compression. Using a record’s VAT, the MicroKernel Engine can divide the variable-length portion of a record into smaller portions and then store those portions in any number of variable tails. The MicroKernel Engine stores an equal amount of the record’s data in each of the record’s variable tails (except the final variable tail). The MicroKernel Engine calculates the amount to store in each variable tail by multiplying the file’s page size by 8. The last variable tail contains any data that remains after the MicroKernel Engine divides the data among the other variable tails.
Note The formula for finding the length of a variable tail (eight times the page size) is an implementation detail that may change in future versions of the MicroKernel Engine.
In a file that employs VATs and has a 4096-byte page size, the first variable tail stores the bytes from offset 0 through 32767 of the record’s variable portion, the second tail stores offsets 32768 through 65535, and so on. The MicroKernel Engine can use the VAT to accelerate a seek to a large offset in a record because the VAT allows it to skip the variable tails containing the record’s lower-offset bytes.
An application specifies whether a file will use VATs when it creates the file. If your application uses chunk operations on huge records (larger than eight times the physical page size) and accesses chunks in a random, nonsequential fashion, VATs may improve your application’s performance. If your application uses whole record operations, VATs do not improve performance because the MicroKernel Engine reads or writes the record sequentially; the MicroKernel Engine skips no bytes in the record.
If your application uses chunk operations but accesses records sequentially (for example, it reads the first 32 KB of a record, then reads the next 32 KB of the record, and so on until the end of the record), VATs do not improve performance, because the MicroKernel Engine saves your position in a record between operations, thereby eliminating the need to seek at the beginning of a chunk operation.
VATs also provide another advantage. When the MicroKernel Engine reads or writes a compressed record, it uses a buffer that must be up to twice as large as the record’s uncompressed size. If the file has VATs, that buffer needs to be only as large as two variable tails (16 times the physical page size).
Key-Only Files
In a key-only file, the entire record is stored with the key, so no data pages are required. Key-only files are useful when your records contain a single key, and that key takes up most of the record. Another common use for a key-only file is as an external index for a standard file.
The following restrictions apply to key-only files:
•Each file can contain only a single key.
•The maximum record length you can define is 253 bytes.
•Key-only files cannot use data compression.
•Step operations do not function with key-only files.
•Although you can do a Get Position on a record in a key-only file, that position will change whenever the record is updated.
Key-only files contain only File Control Record pages followed by a number of PAT pages and index pages. If a key-only file has an ACS, it may also have an ACS page. If you use ODBC to define referential integrity constraints on the file, the file may contain one or more variable pages, as well.
Setting Up Security
The MicroKernel Engine provides three methods of setting up file security:
•Assign an owner name to the file
•Open the file in exclusive mode
•Use the PSQL Control Center (PCC) security settings
In addition, the MicroKernel Engine supports the native file-level security (if available) on the server platforms.
Note Windows developers: File-level security is available on the server if you installed the NTFS file system on your server. File system security is not available if you installed the FAT file system.
The MicroKernel Engine provides the following features for enhancing data security.
Owner Names
The MicroKernel Engine allows you to restrict access to a file by assigning an owner name using the Set Owner operation (see
Set Owner (29) in
Btrieve API Guide.) Once you assign an owner name to a file, the MicroKernel Engine requires that the name be provided to access the file. This prevents users or applications that do not provide the owner name from having unauthorized access to or changing file contents.
Likewise, you can clear the owner name from a file if you know the owner name assigned to it.
Owner names are case-sensitive and can be short or long. A short owner name can be up to 8 bytes long, and a long one up to 24 bytes. For more information, see
Owner Names in
Advanced Operations Guide.
You can restrict access to the file in these ways:
•Users can have read-only access without supplying an owner name. However, neither a user nor a task can change the file contents without supplying the owner name. Attempting to do so causes the MicroKernel Engine to return an error.
•Users can be required to supply an owner name for any access mode. The MicroKernel Engine restricts all access to the file unless the correct owner name is supplied.
When you assign an owner name, you can also request that the database engine encrypt the data in the disk file using the owner name as the encryption key. Encrypting the data on the disk ensures that unauthorized users cannot examine your data by using a debugger or a file dump utility. When you use the Set Owner operation and select encryption, the encryption process begins immediately. The MicroKernel Engine has control until the entire file is encrypted, and the larger the file, the longer the encryption process takes. Because encryption requires additional processing time, you should select this option only if data security is important in your environment.
You can use the
Clear Owner (30) operation to remove ownership restrictions from a file if you know the owner name assigned to it. In addition, if you use the Clear Owner operation on an encrypted file, the database engine decrypts it.
Note Set Owner (29) and Clear Owner (30) do not process hexadecimal long owner names. Any owner name submitted to them is treated as an ASCII string.
Exclusive Mode
To limit access to a file to a single client, you can specify that the MicroKernel Engine open the file in exclusive mode. When a client opens a file in exclusive mode, no other client can open the file until the client that opened the file in exclusive mode closes it.
SQL Security
See
Database URIs for information on database Uniform Resource Indicator (URI) strings. See the
PSQL User Guide for how to access the PCC security settings.