SELECT
Retrieves specified information from a database. A SELECT statement creates a temporary view.
Syntax
query-specification [ [
UNION [
ALL ]
query-specification ]...
[
ORDER BY order-by-expression [ ,
order-by-expression ]... ] [
limit-clause ] [
FOR UPDATE ]
query-specification ::= ( query-specification )
FROM table-reference [ , table-reference ]...
[ WHERE search-condition ]
[
GROUP BY expression [ ,
expression ]...
expression-or-subquery ::= expression | ( query-specification ) [ ORDER BY order-by-expression
[ , order-by-expression ]... ] [ limit-clause ]
subquery-expression ::= ( query-specification ) [ ORDER BY order-by-expression
[ , order-by-expression ]... ] [ limit-clause ]
order-by-expression ::=
expression [
CASE (string) |
COLLATE collation-name ] [
ASC |
DESC ]
limit-clause ::= [ LIMIT [offset,] row_count | row_count OFFSET offset | ALL [OFFSET offset] ]
offset ::= number | ?
row_count ::= number | ?
select-list ::= * | select-item [ , select-item ]...
select-item ::=
expression [ [
AS ]
alias-name ] |
table-name.*
table-reference ::= { OJ outer-join-definition }
| [
db-name.]
table-name [ [
AS ]
alias-name ] [
WITH (
table-hint )
]
| [
db-name.]
view-name [ [
AS ]
alias-name ]
| dbo.f
system-catalog-function-name [ [
AS ]
alias-name ]
| join-definition
| ( join-definition )
| (
table-subquery )[
AS ]
alias-name [ (
column-name [ ,
column-name ]... ) ]
outer-join-definition ::= table-reference outer-join-type JOIN table-reference
ON search-condition
outer-join-type ::= LEFT [ OUTER ] | RIGHT [ OUTER ] | FULL [ OUTER ]
table-hint ::= INDEX ( index-value [ , index-value ]... )
index-value ::= 0 | index-name
index-name ::= user-defined-name
join-definition ::= table-reference [ join-type ] JOIN table-reference ON search-condition
| table-reference CROSS JOIN table-reference
| outer-join-definition
join-type ::= INNER | LEFT [ OUTER ] | RIGHT [ OUTER ] | FULL [ OUTER ]
table-subquery ::=
query-specification [ [
UNION [
ALL ]
query-specification ]... ][
ORDER BY order-by-expression [ ,
order-by-expression ]... ]
search-condition ::= search-condition AND search-condition
| search-condition OR search-condition
| ( search-condition )
| predicate
predicate ::=
expression [
NOT ]
BETWEEN expression AND expression | expression-or-subquery comparison-operator expression-or-subquery
|
expression [
NOT ]
IN (
query-specification )
|
expression [
NOT ]
IN (
value [ ,
value ]... )
|
expression IS [
NOT ]
NULL|
expression comparison-operator
ANY (
query-specification )
|
expression comparison-operator
ALL (
query-specification )
comparison-operator ::= < | > | <= | >= | = | <> | !=
expression-or-subquery ::= expression | ( query-specification )
value ::=
literal |
USER | ?
expression ::= expression - expression
| expression + expression
| expression * expression
| expression / expression
| expression & expression
| expression | expression
| expression ^ expression
| ( expression )
| -expression
| +expression
| column-name
| ?
| literal
| set-function
| scalar-function
| { fn scalar-function }
|
CASE case_value_expression WHEN when_expression THEN then_expression [...] [
ELSE else_expression ]
END|
COALESCE (
expression, expression[,...])
|
IF (
search-condition ,
expression ,
expression )
| SQLSTATE
| subquery-expression
| NULL
| : user-defined-name
| @:IDENTITY
| @:ROWCOUNT
| @@BIGIDENTITY
| @@IDENTITY
| @@ROWCOUNT
| @@SPID
subquery-expression ::= ( query-specification )
set-function ::=
AVG ( [
DISTINCT |
ALL ]
expression )
|
COUNT ( < * | [
DISTINCT |
ALL ]
expression > )
|
COUNT_BIG ( < * | [
DISTINCT |
ALL ]
expression > )
|
MAX ( [
DISTINCT |
ALL ]
expression )
|
MIN ( [
DISTINCT |
ALL ]
expression )
|
STDEV ( [
DISTINCT |
ALL ]
expression )
|
STDEVP ( [
DISTINCT |
ALL ]
expression )
|
SUM ( [
DISTINCT |
ALL ]
expression )
|
VAR ( [
DISTINCT |
ALL ]
expression )
|
VARP ( [
DISTINCT |
ALL ]
expression )
Remarks
The following remarks cover the following topics related to use of SELECT:
FOR UPDATE
SELECT FOR UPDATE locks the row or rows within the table that is selected by the query. The record locks are released when the next COMMIT or ROLLBACK statement is issued.
To avoid contention, SELECT FOR UPDATE locks the rows as they are retrieved.
SELECT FOR UPDATE takes precedence within a transactions if statement level SQL_ATTR_CONCURRENCY is set to SQL_CONCUR_LOCK. If SQL_ATTR_CONCURRENCY is set to SQL_CONCUR_READ_ONLY, the database engine does not return an error.
SELECT FOR UPDATE does not support a WAIT or NOWAIT keyword. SELECT FOR UPDATE returns status code
84: The record or page is locked if it cannot lock the rows within a brief period (20 retries).
Constraints
The SELECT FOR UPDATE statement has the following constraints:
•Is valid only within a transaction. The statement is ignored if used outside of a transaction.
•Is supported only for a single table. You cannot use SELECT FOR UPDATE with JOIN, nonsimple views, or the GROUP BY, DISTINCT, or UNION keywords.
•Is not supported within a CREATE VIEW statement.
GROUP BY
In addition to supporting a GROUP BY on a column list, PSQL supports a GROUP BY on an expression list or on any expression in a GROUP BY expression list. See
GROUP BY for more information on GROUP BY extensions. HAVING is not supported without GROUP BY.
Result sets and stored views generated by executing SELECT statements with any of the following characteristics are read-only (they cannot be updated). That is, using a positioned UPDATE or a positioned DELETE and a SQLSetPos call to add, alter or delete data is not allowed on the result set or stored view if:
•The selection list contains an aggregate:
SELECT SUM(c1) FROM t1
•The selection list specifies DISTINCT:
SELECT DISTINCT c1 FROM t1
•The view uses GROUP BY:
SELECT SUM(c1), c2 FROM t1 GROUP BY c2
•The view is a join (references multiple tables):
SELECT * FROM t1, t2
•The view uses the UNION operator and UNION ALL is not specified or all SELECT statements do not reference the same table:
SELECT c1 FROM t1 UNION SELECT c1 FROM t1
SELECT c1 FROM t1 UNION ALL SELECT c1 FROM t2
•Note that stored views do not allow the UNION operator.
•The view contains a subquery that references a table other than the table in the outer query:
SELECT c1 FROM t1 WHERE c1 IN (SELECT c1 FROM t2)
Dynamic Parameters
Dynamic parameters (?) are not supported as SELECT items. You may use dynamic parameters in any SELECT statement if the dynamic parameter is part of the predicate. For example, SELECT * FROM faculty WHERE id = ? is valid because the dynamic parameter is part of the predicate.
Note that you cannot use SQL Editor in PSQL Control Center to execute a SQL statement with a dynamic parameter in the predicate.
You may use variables as SELECT items only within stored procedures. See
CREATE PROCEDURE.
Aliases
Aliases may appear in a WHERE, HAVING, ORDER BY, or GROUP BY clause. Alias names must differ from any column names within the table. The following statement shows the use of aliases, a and b, in a WHERE clause and in a GROUP BY clause.
SELECT Student_ID a, Transaction_Number b, SUM (Amount_Owed) FROM Billing WHERE a < 120492810 GROUP BY a, b UNION SELECT Student_ID a, Transaction_Number b, SUM (Amount_Paid) FROM Billing WHERE a > 888888888 GROUP BY a, b
SUM and DECIMAL Precision
When using the SUM aggregate function to sum a field that is of type DECIMAL, the following rules apply:
The precision of the result is 74, while the scale is dependent on the column definition.
The result may cause an overflow error if a number with precision greater than 74 is calculated (a very large number indeed). If an overflow occurs, no value is returned, and SQLSTATE is set to 22003, indicating a numeric value is out of range.
Subqueries
A subquery is a SELECT statement with one or more SELECT statements within it. A subquery produces values for further processing within the statement. The maximum number of nested subqueries allowed within the topmost SELECT statement is 16.
The following types of subqueries are supported:
•comparison
•quantified
•in
•exists
•correlated
•expression
•table
Correlated subquery predicates are not supported in a HAVING clause that references grouped columns.
Expression subqueries allow the subquery within the SELECT list. For example, SELECT (SELECT SUM(c1) FROM t1 WHERE t1.c2 = t1.(c2) FROM t2. Only one item is allowed in the subquery SELECT list. For example, the following statement returns an error because the subquery SELECT list contains more than one item: SELECT p.id, (SELECT SUM(b.amount_owed), SUM(b.amount_paid) FROM billing b) FROM person p.
A subquery as an expression may be correlated or noncorrelated. A correlated subquery references one or more columns in any of the tables in the topmost statement. A noncorrelated subquery references no columns in any of the tables in the topmost statement. The following example illustrates a correlated subquery in a WHERE clause:
SELECT * FROM student s WHERE s.Tuition_id IN
(SELECT t.ID FROM tuition t WHERE t.ID = s.Tuition_ID);
Note Table subqueries support noncorrelated subqueries but not correlated subqueries.
A subquery connected with the operators
IN,
EXISTS,
ALL, or
ANY is
not considered an expression.
Both correlated and noncorrelated subqueries can return only a single value. For this reason, both correlated and noncorrelated subqueries are also referred to as scalar subqueries.
Scalar subqueries may appear in the DISTINCT, GROUP BY, and ORDER BY clause.
You may use a subquery on the left-hand side of an expression:
Expr-or-SubQuery CompareOp Expr-or-SubQuery
where Expr is an expression, and CompareOp is one of:
<
(less than) | >
(greater than) | <=
(less than or equal to) | >=
(greater than or equal to) | =
(equals) |
<>
(not equal) | !=
(not equal) | LIKE | IN | NOT IN |
The rest of this section covers the following topics:
Subquery Optimization
Left-hand subquery behavior has been optimized for IN, NOT IN, and =ANY in cases where the subquery is not correlated and any join condition is an outer join. Other conditions may not be optimized. Here is an example of a query that meets these conditions:
SELECT count(*) FROM person WHERE id IN (SELECT faculty_id FROM class)
Performance improves if you use an index in the subquery because PSQL optimizes a subquery based on the index. For example, the subquery in the following statement is optimized on student_id because it is an index in the Billing table:
SELECT (SELECT SUM(b.amount_owed) FROM billing b WHERE b.student_id = p.id) FROM person p
UNION in Subquery
Parentheses on different UNION groups within a subquery are not allowed. Parentheses are allowed within each SELECT statement.
For example, the parenthesis following IN and the last parenthesis are not allowed the following statement:
SELECT c1 FROM t5 WHERE c1 IN ( (SELECT c1 FROM t1 UNION SELECT c1 FROM t2) UNION ALL (SELECT c1 FROM t3 UNION SELECT c1 from t4) )
Table Subqueries
Table subqueries can be used to combine multiple queries into one detailed query. A table subquery is a dynamic view, which is not persisted in the database. When the topmost SELECT query finishes, all resources associated with table subqueries are released.
Note Only noncorrelated subqueries are allowed in table subqueries. Correlated subqueries are not allowed.
The following examples of pagination (1500 rows with 100 rows per page) show the use of table subqueries with the ORDER BY keyword:
The first 100 rows
SELECT * FROM ( SELECT TOP 100 * FROM ( SELECT TOP 100 * FROM person ORDER BY last_name asc ) AS foo ORDER BY last_name desc ) AS bar ORDER BY last_name ASC
The second 100 rows
SELECT * FROM ( SELECT TOP 100 * FROM ( SELECT TOP 200 * FROM person ORDER BY last_name asc ) AS foo ORDER BY last_name DESC ) AS bar ORDER BY last_name ASC
…
The fifteenth 100 rows
SELECT * FROM ( SELECT TOP 100 * FROM ( SELECT TOP 1500 * FROM person ORDER BY last_name ASC ) AS foo ORDER BY last_name DESC ) AS bar ORDER BY last_name ASC
Using Table Hints
The table hint functionality allows you to specify which index, or indexes, to use for query optimization. A table hint overrides the default query optimizer used by the database engine.
If the table hint specifies INDEX(0), the engine performs a table scan of the associated table. (A table scan reads each row in the table rather than using an index to locate a specific data element.)
If the table hint specifies INDEX(index-name), the engine uses index-name to optimize the table based on restrictions of any JOIN conditions, or based on the use of DISTINCT, GROUP BY, or ORDER BY. If the table cannot be optimized on the specified index, the engine attempts to optimize the table based on any existing index.
If you specify multiple index names, the engine chooses the index that provides optimal performance or uses the multiple indexes for OR optimization. An example helps clarify this. Suppose that you have the following:
CREATE INDEX ndx1 on t1(c1)
CREATE INDEX ndx2 on t1(c2)
CREATE INDEX ndx3 on t1(c3)
SELECT * FROM t1 WITH (INDEX (ndx1, ndx2)) WHERE c1 = 1 AND c2 > 1 AND c3 = 1
The database engine uses ndx1 to optimize on c1 = 1 rather than using ndx2 for optimization. Ndx3 is not considered because the table hint does not include ndx3.
Now consider the following:
SELECT * FROM t1 WITH (INDEX (ndx1, ndx2)) WHERE (c1 = 1 OR c2 > 1) AND c3 = 1
The engine uses both ndx1 and ndx2 to optimize on (c1 = 1 OR c2 > 1).
The order in which the multiple index names appear in the table hint does not matter. The database engine chooses from the specified indexes the one(s) that provides for the best optimization.
Duplicate index names within the table hint are ignored.
For a joined view, specify the table hint after the appropriate table name, not at the end of the FROM clause. For example, the following statement is correct:
SELECT * FROM person WITH (INDEX(Names)), student WHERE student.id = person.id AND last_name LIKE 'S%'
Contrast this with the following statement, which is incorrect:
SELECT * FROM person, student WITH (INDEX(Names)) WHERE student.id = person.id AND last_name LIKE 'S%'
Note The table hint functionality is intended for advanced users. Typically, table hints are not required because the database query optimizer usually picks the best optimization method.
Table Hint Restrictions
•The maximum number of index names that can be used in a table hint is limited only by the maximum length of a SQL statement (64 KB).
•The index name within a table hint must not be fully qualified with the table name.
Incorrect SQL: | SELECT * FROM t1 WITH (INDEX(t1.ndx1)) WHERE t1.c1 = 1 |
Returns: | SQL_ERROR |
szSqlState: | 37000 |
Message: | Syntax Error: SELECT * FROM t1 WITH (INDEX(t1.<< ??? >>ndx1)) WHERE t1.c1 = 1 |
•Table hints are ignored if they are used in a SELECT statement with a view.
Incorrect SQL: | SELECT * FROM myt1view WITH (INDEX(ndx1)) |
Returns: | SQL_SUCCESS_WITH_INFO |
szSqlState: | 01000 |
Message: | Index hints supplied with views will be ignored |
•Zero is the only valid hint that is not an index name.
Incorrect SQL: | SELECT * FROM t1 WITH (INDEX(85)) |
Returns: | SQL_ERROR |
szSqlState: | S1000 |
Message: | Invalid index hint |
•The index name in a table hint must specify an existing index.
Incorrect SQL: | SELECT * FROM t1 WITH (INDEX(ndx4)) |
Returns: | SQL_ERROR |
szSqlState: | S0012 |
Message: | Invalid index name; index not found |
•A table hint cannot be specified on a subquery AS table.
Incorrect SQL: | SELECT * FROM (SELECT c1, c2 FROM t1 WHERE c1 = 1) AS a WITH (INDEX(ndx2)) WHERE a.c2 = 10 |
Returns: | SQL_ERROR |
szSqlState: | 37000 |
Message: | syntax Error: SELECT * FROM (SELECT c1, c2 FROM t1 WHERE c1 = 1) AS a WITH<< ??? >>(INDEX(ndx2)) WHERE a.c2 = 10 |
Examples
This simple SELECT statement retrieves all the data from the Faculty table.
SELECT * FROM Faculty
This statement retrieves the data from the person and the faculty table where the id column in the person table is the same as the id column in the faculty table.
SELECT Person.id, Faculty.salary FROM Person, Faculty WHERE Person.id = Faculty.id
The rest of this section provides examples of variations on SELECT statements. Some of these headings are based on the variable given in the syntax definition for SELECT.
FOR UPDATE
The following example uses table t1 to demonstrate the use of FOR UPDATE. Assume that t1 is part of the Demodata sample database. The stored procedure creates a cursor for the SELECT FOR UPDATE statement. A loop fetches each record from t1 and, for those rows where c1=2, sets the value of c1 to four.
The procedure is called by passing the value 2 as the IN parameter.
The example assumes two users, A and B, logged in to Demodata. User A performs the following:
DROP TABLE t1
CREATE TABLE t1 (c1 INTEGER, c2 INTEGER)
INSERT INTO t1 VALUES (1,1)
INSERT INTO t1 VALUES (2,1)
INSERT INTO t1 VALUES (1,1)
INSERT INTO t1 VALUES (2,1)
CREATE PROCEDURE p1 (IN :a INTEGER)
AS
BEGIN
DECLARE :b INTEGER;
DECLARE :i INTEGER;
DECLARE c1Bulk CURSOR FOR SELECT * FROM t1 WHERE c1 = :a FOR UPDATE;
START TRANSACTION;
OPEN c1Bulk;
BulkLinesLoop:
LOOP
FETCH NEXT FROM c1Bulk INTO :i;
IF SQLSTATE = '02000' THEN
LEAVE BulkLinesLoop;
END IF;
UPDATE SET c1 = 4 WHERE CURRENT OF c1Bulk;
END LOOP;
CLOSE c1Bulk;
SET :b = 0;
WHILE (:b < 100000) DO
BEGIN
SET :b = :b + 1;
END;
END WHILE;
COMMIT WORK;
END;
CALL p1(2)
Notice that a WHILE loop delays the COMMIT of the transaction. During that delay, assume that User B attempts to update t1. Status code 84 is returned to User B because those rows are locked by the SELECT FOR UPDATE statement from User A.
============
The following example uses table t1 to demonstrate how SELECT FOR UPDATE locks records when the statement is used outside of a stored procedure. Assume that t1 is part of the Demodata sample database.
The example assumes that two users, A and B, are logged in to Demodata. User A performs the following:
DROP TABLE t1
CREATE TABLE t1 (c1 INTEGER, c2 INTEGER)
INSERT INTO t1 VALUES (1,1)
INSERT INTO t1 VALUES (2,1)
INSERT INTO t1 VALUES (1,1)
INSERT INTO t1 VALUES (2,1)
(turn off AUTOCOMMIT)
(execute and fetch): "SELECT * FROM t1 WHERE c1 = 2 FOR UPDATE"
The two records where c1 = 2 are locked until User A issues a COMMIT WORK or ROLLBACK WORK statement.
(User B attempts to update t1): "UPDATE t1 SET c1=3 WHERE c1=2" A status code 84 is returned to User B because those rows are locked by the SELECT FOR UPDATE statement from User A.
(Now assume that User A commits the transaction.) The two records where c1 = 2 are unlocked.
User B could now execute "UPDATE t1 SET c1=3 WHERE c1=2" and change the values for c1.
============
Approximate Numeric Literal
SELECT * FROM results WHERE quotient =-4.5E-2
INSERT INTO results (quotient) VALUES (+5E7)
============
Between Predicate
The syntax expression1 BETWEEN expression2 and expression3 returns TRUE if expression1 >= expression2 and expression1<= expression3. FALSE is returned if expression1 >= expression3, or is expression1 <= expression2.
Expression2 and expression3 may be dynamic parameters (for example, SELECT * FROM emp WHERE emp_id BETWEEN ? AND ?).
The next example retrieves the first names from the Person table whose ID falls between 10000 and 20000.
SELECT First_name FROM Person WHERE ID BETWEEN 10000 AND 20000
============
Correlation Name
Both table and column correlation names are supported.
The following example selects data from both the person table and the faculty table using the aliases T1 and T2 to differentiate between the two tables.
SELECT * FROM Person t1, Faculty t2 WHERE t1.id = t2.id
The correlation name for a table name can also be specified in using the FROM clause, as seen in the following example:
SELECT a.Name, b.Capacity FROM Class a, Room b
WHERE a.Room_Number = b.Number
============
Exact Numeric Literal
SELECT car_num, price FROM cars WHERE car_num =49042 AND price=49999.99
============
In Predicate
This selects the records from table Person table where the first names are Bill and Roosevelt.
SELECT * FROM Person WHERE First_name IN ('Roosevelt', 'Bill')
============
Set Function
The aggregate functions for AVG (average), MAX (maximum), MIN (minimum), and SUM operate as commonly expected. The following examples use these functions with the Salary field in the Faculty sample table.
SELECT AVG(Salary) FROM Faculty
SELECT MAX(Salary) FROM Faculty
SELECT MIN(Salary) FROM Faculty
SELECT SUM(Salary) FROM Faculty
============
The following example retrieves student_id and sum of the amount_paid where it is greater than or equal to 100 from the billing table. It then groups the records by student_id.
SELECT Student_ID, SUM(Amount_Paid)
FROM Billing
GROUP BY Student_ID
HAVING SUM(Amount_Paid) >=100.00
If the expression is a positive integer literal, then that literal is interpreted as the number of the column in the result set and ordering is done on that column. No ordering is allowed on set functions or an expression that contains a set function.
============
COUNT(expression) and COUNT_BIG(expression) count all nonnull values for an expression across a predicate. COUNT(*) and COUNT_BIG(*) count all values, including NULL values. COUNT() returns an INTEGER data type with a maximum value of 2,147,483,647. COUNT_BIG() returns a BIGINT data type with a maximum value of 9,223,372,036,854,775,807.
The following example returns a count of chemistry majors who have a grade point average of 3.5 or greater (and the result does not equal null).
SELECT COUNT(*) FROM student WHERE (CUMULATIVE_GPA > 3.4 and MAJOR='Chemistry')
The STDEV function returns the standard deviation of all values based on a sample of the data. The STDEVP function returns the standard deviation for the population for all values in the specified expression. Here are the equations for each function:
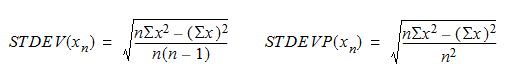
The following returns the standard deviation of the grade point average by major from the Student sample table.
SELECT STDEV(Cumulative_GPA), Major FROM Student GROUP BY Major
The following returns the standard deviation for the population of the grade point average by major from the Student sample table.
SELECT STDEVP(Cumulative_GPA), Major FROM Student GROUP BY Major
The VAR function returns the statistical variance for all values on a sample of the data. The VARP function returns the statistical variance for the population for all values in the specified expression. Here are the equations for each function:
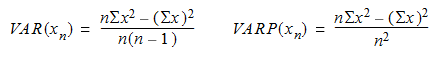
The following returns the statistical variance of the grade point average by major from the Student sample table.
SELECT VAR(Cumulative_GPA), Major FROM Student GROUP BY Major
The following returns the statistical variance for the population of the grade point average by major from the Student sample table.
SELECT VARP(Cumulative_GPA), Major FROM Student GROUP BY Major
Note that for STDEV, STDEVP, VAR, and VARP, the expression must be a numeric data type and an eight-byte DOUBLE is returned. A floating-point overflow error results if the difference between the minimum and maximum values of the expression is out of range. Expression cannot contain aggregate functions. There must be at least two rows with a value in the expression field or a result is not calculated and returns a NULL.
============
Date Literal
============
Time Literal
============
Time Stamp Literal
String Literal
============
Date Arithmetic
SELECT * FROM person P, Class C WHERE p.Date_Of_Birth < ' 1973-09-05' and c.Start_date >{d '1995-05-08'} + 30
PSQL supports adding or subtracting an integer from a date where the integer is the number of days to add or subtract, and the date is embedded in a vendor string. (This is equivalent to executing a convert on the date).
You may also subtract one date from another to yield a number of days.
============
IF
The IF system scalar function provides conditional execution based on the truth value of a condition
This expression prints the column header as Prime1 and amount owed as 2000 where the value of the column amount_owed is 2000 or it prints a 0 if the value of the amount_owed column is not equal to 2000.
SELECT Student_ID, Amount_Owed,
IF (Amount_Owed = 2000, Amount_Owed, Convert(0, SQL_DECIMAL)) "Prime1"
FROM Billing
From table Class, the following example prints the value in the Section column if the section is equal to 001, else it prints “xxx” under column header Prime1.
Under column header Prime2, it prints the value in the Section column if the value of the section column is equal to 002, or else it prints “yyy.”
SELECT ID, Name, Section,
IF (Section = '001', Section, 'xxx') "Prime1",
IF (Section = '002', Section, 'yyy') "Prime2"
FROM Class
You can combine header Prime1 and header Prime2 by using nested IF functions. Under column header Prime, the following query prints the value of the Section column if the value of the Section column is equal to 001 or 002. Otherwise, it print “xxx.”
SELECT ID, Name, Section,
IF (Section = '001', Section, IF(Section = '002', Section, 'xxx')) Prime
FROM Class
============
Multidatabase Join
When needed, a database name may be prepended to an aliased table name in the FROM clause, to distinguish among tables from two or more different databases that are used in a join.
All of the specified databases must be serviced by the same database engine and have the same database code page settings. The databases do not need to reside on the same physical volume. The current database may be secure or unsecure, but all other databases in the join must be unsecure. With regard to Referential Integrity, all RI keys must exist within the same database. (See also
Encoding.)
Literal database names are not permitted in the select-list or in the WHERE clause. If you wish to refer to specific columns in the select-list or in the WHERE clause, you must use an alias for each specified table. See examples.
Assume two separate databases, named accounting and customers, exist on the same server. You can join tables from the two databases using table aliases and SQL syntax similar to the following example:
SELECT ord.account, inf.account, ord.balance, inf.address
FROM accounting.orders ord, customers.info inf
WHERE ord.account = inf.account
============
In this example, the two separate databases are acctdb and loandb. The table aliases are a and b, respectively.
SELECT a.loan_number_a, b.account_no, a.current_bal, b.balance
FROM acctdb.ds500_acct_master b LEFT OUTER JOIN loandb.ml502_loan_master a ON (a.loan_number_a = b.loan_number)
WHERE a.current_bal <> (b.balance * -1)
ORDER BY a.loan_number_a
============
Left Outer Join
The following example shows how to access the Person and Student tables from the Demodata database to obtain the Last Name, First Initial of the First Name and GPA of students. With the LEFT OUTER JOIN, all rows in the Person table are fetched (the table to the left of LEFT OUTER JOIN). Since not all people have GPAs, some of the columns have NULL values for the results. This is how outer join works, returning nonmatching rows from either table.
SELECT Last_Name,Left(First_Name,1) AS First_Initial,Cumulative_GPA AS GPA FROM "Person"
LEFT OUTER JOIN "Student" ON Person.ID=Student.ID
ORDER BY Cumulative_GPA DESC, Last_Name
Assume that you want to know everyone with perfectly rounded GPAs and have them all ordered by the length of their last name. Using the MOD statement and the LENGTH scalar function, you can achieve this by adding the following to the query:
WHERE MOD(Cumulative_GPA,1)=0 ORDER BY LENGTH(Last_Name)
============
Right Outer Join
The difference between LEFT and RIGHT OUTER JOIN is that all non matching rows show up for the table defined to the right of RIGHT OUTER JOIN. Change the query for LEFT OUTER JOIN to include a RIGHT OUTER JOIN instead. The difference is that the all nonmatching rows from the right table, in this case Student, show up even if no GPA is present. However, since all rows in the Student table have GPAs, all rows are fetched.
SELECT Last_Name,Left(First_Name,1) AS First_Initial,Cumulative_GPA AS GPA FROM "Person"
RIGHT OUTER JOIN "Student" ON Person.ID=Student.ID
ORDER BY Cumulative_GPA DESC, Last_Name
============
Cartesian Join
A Cartesian join is the matrix of all possible combinations of the rows from each of the tables. The number of rows in the Cartesian product equals the number of rows in the first table times the number of rows in the second table.
Assume you have the following tables in your database.
Table 37 Addr Table
EmpID | Street |
E1 | 101 Mem Lane |
E2 | 14 Young St. |
Table 38 Loc Table
LocID | Name |
L1 | PlanetX |
L2 | PlanetY |
The following performs a Cartesian JOIN on these tables:
SELECT * FROM Addr,Loc
This results in the following data set:
Table 39 SELECT Statement with Cartesian JOIN
EmpID | Street | LocID | Name |
E1 | 101 Mem Lane | L1 | PlanetX |
E1 | 101 Mem Lane | L2 | PlanetY |
E2 | 14 Young St | L1 | PlanetX |
E2 | 14 Young St | L2 | PlanetY |
============
DISTINCT in Aggregate Functions
DISTINCT is useful in aggregate functions. When used with SUM, AVG, and COUNT, it eliminates duplicate values before calculating the sum, average or count. With MIN, and MAX, however, it is allowed but does not change the result of the returned minimum or maximum.
For example, assume you want to know the salaries for different departments, including the minimum, maximum and salary, and you want to remove duplicate salaries. The following statement does this, excluding the computer science department:
SELECT dept_name, MIN(salary), MAX(salary), AVG(DISTINCT salary) FROM faculty WHERE dept_name<>'computer science' GROUP BY dept_name
On the other hand, to include duplicate salaries, drop DISTINCT:
SELECT dept_name, MIN(salary), MAX(salary), AVG(salary) FROM faculty WHERE dept_name<>'computer science' GROUP BY dept_name
For the use of DISTINCT in SELECT statements, see
DISTINCT.
TOP or LIMIT
You can set the maximum number of rows returned by a SELECT statement by using the keywords TOP or LIMIT. The number must be a literal positive value. It is defined as a 32-bit unsigned integer. For example:
SELECT TOP 10 * FROM Person
returns the first 10 rows of the Person table in Demodata.
LIMIT is identical to TOP except that it provides the OFFSET keyword to enable you to “scroll” through the result set by choosing the first row in the returned records. For example, if the offset is 5, then the first row returned is row 6. LIMIT has two ways to specify the offset, both with and without the OFFSET keyword, as shown in the following examples, which return identical results:
SELECT * FROM Person LIMIT 10 OFFSET 5
SELECT * FROM Person LIMIT 5,10
Note that when you do not use the OFFSET keyword, you must put the offset value before the row count, separated by a comma.
You can use TOP or LIMIT with ORDER BY. If so, then the database engine generates a temporary table and populates it with the entire query result set if no index can be used for ORDER BY. The rows in the temporary table are arranged as specified by ORDER BY in the result set, but only the number of rows determined by TOP or LIMIT are returned by the query.
Views that use TOP or LIMIT may be joined with other tables or views.
The main difference between TOP or LIMIT and
SET ROWCOUNT is that TOP or LIMIT affect only the current statement, while SET ROWCOUNT affects all subsequent statements issued during the current database session.
If SET ROWCOUNT and TOP or LIMIT are both used in a query, the query returns a number of rows equal to the lowest of the two values.
Either TOP or LIMIT is allowed within a single query or subquery, but not both.
Cursor Types and TOP or LIMIT
A SELECT query with a TOP or LIMIT clause that uses a dynamic cursor converts the cursor type to static. Forward-only and static cursors are not affected.
TOP or LIMIT Examples
The following examples use both TOP and LIMIT clauses, which are interchangeable as keywords and give the same results, although LIMIT offers more control of which rows are returned.
SELECT TOP 10 * FROM person; -- returns 10 rows
SELECT * FROM person LIMIT 10; -- returns 10 rows
SELECT * FROM person LIMIT 10 OFFSET 5; -- returns 10 rows starting with row 6
SELECT * FROM person LIMIT 5,10; -- returns 10 rows starting with row 6
SET ROWCOUNT = 5;
SELECT TOP 10 * FROM person; -- returns 5 rows
SELECT * FROM person LIMIT 10; -- returns 5 rows
SET ROWCOUNT = 12;
SELECT TOP 10 * FROM person ORDER BY id; -- returns the first 10 rows of the full list ordered by column id.
SELECT * FROM person LIMIT 20 ORDER BY id; -- returns the first 12 rows of the full list ordered by column id.
============
The following examples show a variety of behaviors when TOP or LIMIT is used in views, unions, or subqueries.
CREATE VIEW v1 (c1) AS SELECT TOP 10 id FROM person;
CREATE VIEW v2 (d1) AS SELECT TOP 5 c1 FROM v1;
SELECT * FROM v2 -- returns 5 rows
SELECT TOP 10 * FROM v2 -- returns 5 rows
SELECT TOP 2 * FROM v2 -- returns 2 rows
SELECT * FROM v2 LIMIT 10 -- returns 5 rows
SELECT * FROM v2 LIMIT 10 OFFSET 3 -- returns 2 rows starting with row 4
SELECT * FROM v2 LIMIT 3,10 -- returns 2 rows starting with row 4
SELECT TOP 10 id FROM person UNION SELECT TOP 13 faculty_id FROM class -- returns 17 rows
SELECT TOP 10 id FROM person UNION ALL SELECT TOP 13 faculty_id FROM class -- returns 23 rows
SELECT id FROM person WHERE id IN (SELECT TOP 10 faculty_id from class) -- returns 5 rows
SELECT id FROM person WHERE id >= any (SELECT TOP 10 faculty_id from class) -- returns 1040 rows
============
The following example returns last name and amount owed for students above a certain ID number.
SELECT p_last_name, b_owed FROM
(SELECT TOP 10 id, last_name FROM person ORDER BY id DESC) p (p_id, p_last_name),
(SELECT TOP 10 student_id, SUM (amount_owed) FROM billing GROUP BY student_id ORDER BY student_id DESC) b (b_id, b_owed)
WHERE p.p_id = b.b_id AND p.p_id > 714662900
ORDER BY p_last_name ASC
Table Hint Examples
This topic provides working examples for table hints. Use the SQL statements to create them in PSQL.
DROP TABLE t1
CREATE TABLE t1 (c1 INTEGER, c2 INTEGER)
INSERT INTO t1 VALUES (1,10)
INSERT INTO t1 VALUES (1,10)
INSERT INTO t1 VALUES (2,20)
INSERT INTO t1 VALUES (2,20)
INSERT INTO t1 VALUES (3,30)
INSERT INTO t1 VALUES (3,30)
CREATE INDEX it1c1 ON t1 (c1)
CREATE INDEX it1c1c2 ON t1 (c1, c2)
CREATE INDEX it1c2 ON t1 (c2)
CREATE INDEX it1c2c1 ON t1 (c2, c1)
DROP TABLE t2
CREATE TABLE t2 (c1 INTEGER, c2 INTEGER)
INSERT INTO t2 VALUES (1,10)
INSERT INTO t2 VALUES (1,10)
INSERT INTO t2 VALUES (2,20)
INSERT INTO t2 VALUES (2,20)
INSERT INTO t2 VALUES (3,30)
INSERT INTO t2 VALUES (3,30)
Certain restrictions apply to the use of table hints. See
Table Hint Restrictions for examples.
============
The following example optimizes on index it1c1c2.
SELECT * FROM t1 WITH (INDEX(it1c1c2)) WHERE c1 = 1
Contrast this with the following example, which optimizes on index it1c1 instead of on it1c2 because the restriction consists of only c1 = 1. If a query specifies an index that cannot be used to optimize the query, the hint is ignored.
SELECT * FROM t1 WITH (INDEX(it1c2)) WHERE c1 = 1
============
The following example performs a table scan of table t1.
SELECT * FROM t1 WITH (INDEX(0)) WHERE c1 = 1
============
The following example optimizes on indexes it1c1c2 and it1c2c1.
SELECT * FROM t1 WITH (INDEX(it1c1c2, it1c2c1)) WHERE c1 = 1 OR c2 = 10
============
The following example using a table hint in the creation of a view. When all records are selected from the view, the SELECT statement optimizes on index it1c1c2.
DROP VIEW v2
CREATE VIEW v2 as SELECT * FROM t1 WITH (INDEX(it1c1c2)) WHERE c1 = 1
SELECT * FROM v2
============
The following example uses a table hint in a subquery and optimizes on index it1c1c2.
SELECT * FROM (SELECT c1, c2 FROM t1 WITH (INDEX(it1c1c2)) WHERE c1 = 1) AS a WHERE a.c2 = 10
============
The following example uses a table hint in a subquery and an alias name “a.” The alias name is required.
SELECT * FROM (SELECT Last_Name FROM Person AS P with (Index(Names)) ) a
============
The following example optimizes the query based on the c1 = 1 restriction and optimizes the GROUP BY clause based on index it1c1c2.
SELECT c1, c2, count(*) FROM t1 WHERE c1 = 1 GROUP BY c1, c2
============
The following example optimizes on index it1c1 and, unlike the previous example, optimizes only on the restriction and not on the GROUP BY clause.
SELECT c1, c2, count(*) FROM t1 WITH (INDEX(it1c1)) WHERE c1 = 1 GROUP BY c1, c2
Since the GROUP BY clause cannot be optimized using the specified index, it1c1, the database engine uses a temporary table to process the GROUP BY.
============
The following example uses a table hint in a JOIN clause and optimizes on index it1c1c2.
SELECT * FROM t2 INNER JOIN t1 WITH (INDEX(it1c1c2)) ON t1.c1 = t2.c1
Contrast this with the following statement, which does not use a table hint and optimizes on index it1c1.
SELECT * FROM t2 INNER JOIN t1 ON t1.c1 = t2.c1
============
The following example uses a table hint in a JOIN clause to perform a table scan of table t1.
SELECT * FROM t2 INNER JOIN t1 WITH (INDEX(0)) ON t1.c1 = t2.c1
Contrast this with the following example which also performs a table scan of table t1. However, because no JOIN clause is used, the statement uses a temporary table join.
SELECT * FROM t2, t1 WITH (INDEX(0)) WHERE t1.c1 = t2.c1
See Also