VectorH and Apache Hadoop Integration
VectorH integrates with two of Hadoop’s core services.
• HDFS – VectorH distributes its data by leveraging the native file system APIs
• YARN – VectorH integrates with YARN for resource and workload management
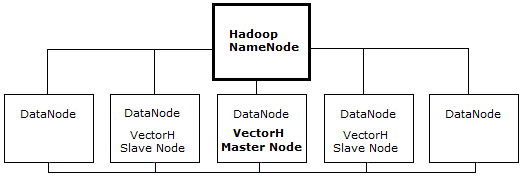
The VectorH engine runs natively within a Hadoop cluster and can use all or a subset of the nodes in a Hadoop cluster. VectorH is installed on one DataNode, which becomes the VectorH master node. The master node is a full installation and acts as the primary node for the VectorH instance. The master node drives the setup for the VectorH slave nodes.
Although VectorH can be installed on a single DataNode, we recommend using at least three DataNodes (one of which is the VectorH master node). The following illustrates VectorH installed on a five node Hadoop cluster but using only three nodes.
YARN can be used to control and share resources within a Hadoop cluster so that processes can share the available resources without conflicting. These resources can be decreased or increased as demand requires, for example, for month-end ETL processing. VectorH is compliant with YARN.