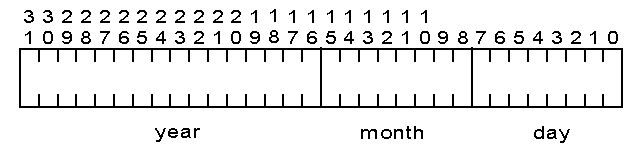The following table maps the transactional and relational data types supported by Zen. It is useful for developers of SQL applications that access data in Btrieve data files.
Table 112 Zen Transactional and Relational Data Types
Transactional Type (Size)
Relational Type
Metadata Type Code Value
Size (bytes)
Create/Add Parameters1
Data Type Notes
AUTOINCREMENT(2)
SMALLIDENTITY
15
2
AUTOINCREMENT(4)
IDENTITY
15
4
AUTOINCREMENT(8)
BIGIDENTITY
15
8
AUTOTIMESTAMP
AUTOTIMESTAMP
32
8
11
BFLOAT(4)
BFLOAT4
9
4
not null
4
BFLOAT(8)
BFLOAT8
9
8
not null
4
BLOB
LONGVARBINARY
21
n/a2
not null
2, 3, 6
BLOB(2)
NLONGVARCHAR
21
n/a2
not null case insensitive
7
CLOB
LONGVARCHAR
21
n/a2
not null case insensitive
5, 6
CURRENCY
CURRENCY
19
8
not null
DATE
DATE
3
4
not null
None
DATETIME
30
8
not null
10
DECIMAL
DECIMAL
5
1 - 64
precision scale not null
FLOAT(4)
REAL
2
4
not null
FLOAT(8)
DOUBLE
2
8
not null
GUID
UNIQUEIDENTIFIER
27
16
not null
INTEGER(1)
TINYINT
1
1
not null
INTEGER(2)
SMALLINT
1
2
not null
INTEGER(4)
INTEGER
1
4
not null
INTEGER(8)
BIGINT
1
8
not null
MONEY
DECIMAL
6
1 - 64
precision scale not null
NUMERIC
NUMERIC
8
1 - 37
precision scale not null
4
NUMERICSA
NUMERICSA
18
1 - 37
precision scale not null
4
NUMERICSLB
NUMERICSLB
28
1 - 37
precision scale not null
4
NUMERICSLS
NUMERICSLS
29
1 - 37
precision scale not null
4
NUMERICSTB
NUMERICSTB
31
1 - 37
precision scale not null
4
NUMERICSTS
NUMERICSTS
17
1 - 37
precision scale not null
4
STRING
BINARY
0
1 - 8,000
size not null case insensitive
2, 3
STRING
CHAR
0
1 - 8,000
size not null case insensitive
1
TIME
TIME
4
4
not null
TIMESTAMP
TIMESTAMP
20
8
not null
TIMESTAMP2
TIMESTAMP2
34
8
not null
11
UNSIGNED(1) BINARY
UTINYINT
14
1
not null
UNSIGNED(2) BINARY
USMALLINT
14
2
not null
UNSIGNED(4) BINARY
UINTEGER
14
4
not null
UNSIGNED(8) BINARY
UBIGINT
14
8
not null
WSTRING
NCHAR
25
2 - 8,000
size 1 - 4,000 not null case insensitive
12, 13
WZSTRING
NVARCHAR
26
2 - 8,000
size 1 - 4,000 not null case insensitive
12, 14
ZSTRING
VARCHAR
11
1 - 8,000
size not null case insensitive
5
none
BIT
16
1 bit
6, 8
LOGICAL(1)
BIT
7
1 bit
9
LOGICAL(2)
SMALLINT
1
2
not null
1 The required parameters are precision and size. The optional parameters are case insensitive, not null, and scale.
2 "n/a" stands for "not applicable"
Data Type Notes
1. Padded with spaces
2. Flag set in FIELD.DDF to tell SQL to use binary. See also COLUMNMAP Flags in Distributed Tuning Interface Guide and Column Flags in Distributed Tuning Objects Guide.
3. Padded with binary zeros
4. Cannot be used as variable or in stored procedures
5. Not padded
6. Cannot be indexed
7. Flag set in FIELD.DDF to tell SQL to use NLONGVARCHAR. See also COLUMNMAP Flags in Distributed Tuning Interface Guide and Column Flags in Distributed Tuning Objects Guide.
8. TRUEBITCREATE must be set to on (the default).
9. TRUEBITCREATE must be set to off.
10. Type code 30 is not a MicroKernel Engine code. It is the identifier for DATETIME within the Relational Engine metadata.
11. Sorts like UBIGINT.
12. For Unicode types, the column size represents the number of 2-byte UCS-2 units.
13. Padded with Unicode spaces (2 bytes)
14. Padded with Unicode NUL characters (2 bytes, binary zero)
Data Type Ranges
The following table lists the value ranges for the Zen data types and their increments where appropriate.
Table 113 Zen Data Type Ranges
Relational Data Type
Valid Value Range
AUTOTIMESTAMP
1970-01-01 00:00:00.000000000 to 2554-07-21 23:34:33.709551615
Initializing with zero causes the insert or the next update to use the current time and date.
BFLOAT4
-1.70141172e+38 – +1.70141173e+38
Smallest value by which you can increment or decrement a BFLOAT4 is 2.938736e-39
BFLOAT8
-1.70141173e+38 – +1.70141173e+38
Smallest value by which you can increment or decrement a BFLOAT8 is 2.93873588e-39.
BIGIDENTITY
-9223372036854775808 – +9223372036854775807
BIGINT
-9223372036854775808 – +9223372036854775807
BINARY
Range not applicable
BIT
Range not applicable
CHAR
Range not applicable
CURRENCY
-922337203685477.5808 – +922337203685477.5807
DATE
01-01-0001 to 12-31-9999
Note: 00-00-0000 is not a valid value. If you have legacy data that contains a 00-00-0000 value of type DATE, you can query it by using "is null" in the query.
DATETIME
1753-01-01 00:00:00.000 to 9999-12-31 23:59:59.999, to an accuracy of 1 millisecond
DECIMAL
Depends on the length and number of decimal places
Expressions may have multiple operators, which are performed in order of precedence. Zen uses the following order, with level 1 highest and level 9 lowest. A higher operator is evaluated before a lower one.
4 =, >, <, >=, <=, <>, != (these comparison operators mean the following, respectively: equals, greater than, less than, greater than equal to, less than equal to, not equal, not equal)
5 ^ (bitwise Exclusive OR), | (bitwise OR)
6 NOT
7 AND
8 ALL, ANY, BETWEEN, IN, LIKE, OR, SOME
9 = (assignment)
In an expression, operators with equal precedence are evaluated left to right. For example, in SET :Counter = 12 / 4 * 7, the division is evaluated before the multiplication to return a result of 21.
Parentheses
You can use parentheses to override the precedence of operators in an expression. Everything within the parentheses is evaluated first to yield a value that is then used by an operator outside of the parentheses. For example, in the following statement, the division operator would ordinarily be evaluated before the addition operator. The result would be 12 (that is, 8 + 4). However, the addition is performed first because of the parentheses, so the procedure returns a result of 4.
SET :Counter = 32 / (4 + 4)
If an expression has nested parentheses, the deepest nested expression is evaluated first, followed by the next deepest, and so on. For example, in the following statement, the addition is performed first, then the multiplication, then the subtraction, and finally the division. The result is a value of 5.
SET :Counter = 100 / (40 - (2 * (5 + 5)));
Data Type Precedence
Data type precedence determines the result when two expressions of different types are combined by an operator. The data type with lower precedence is converted to the data type with higher precedence.
Note Operations on incompatible data types return errors, such as adding an INTEGER to a CHAR.
Numeric Data Types
Relational numeric data types use the following precedence:
1 DOUBLE, FLOAT, BFLOAT8 (highest)
2 REAL, BFLOAT4
3 DECIMAL, NUMERIC, NUMERICSA, NUMERICSTS
4 NUMERICSLS, NUMERICSTB, NUMERICSLB
5 CURRENCY, MONEY
6 BIGINT, UBIGINT, BIGIDENTITY
7 INTEGER, UINTEGER, IDENTITY
8 SMALLINT, USMALLINT, SMALLIDENTITY
9 TINYINT, UTINYINT
10 BIT (lowest)
Character Data Types
Relational character data types use the following precedence:
1 NLONGVARCHAR
2 NCHAR, NVARCHAR
3 LONGVARCHAR
4 CHAR, VARCHAR
If you concatenate an NCHAR or NVARCHAR with a NLONGVARCHAR, the result is an NLONGVARCHAR.
If you concatenate an NCHAR with a LONGVARCHAR, the result is an NLONGVARCHAR.
If you concatenate a CHAR or VARCHAR with a LONGVARCHAR, the result is a LONGVARCHAR.
If you concatenate a CHAR with a VARCHAR, the result is the type of the first data type in the concatenation, moving left to right. For example, if c1 is a CHAR and c2 is a VARCHAR, the result of (c1 + c2) is a CHAR. The result of (c2 + c1) is a VARCHAR.
Data Types with No Precedence
The BINARY, LONGVARBINARY, and UNIQUEIDENTIFIER data types have no precedence because operations to combine them are not allowed.
No date and time data type may be combined with any other date and time data type.
Precision and Scale of Decimal Data Types
Precision is the number of digits in a number. Scale is the number of digits to the right of the decimal point in a number. The number 909.777 has a precision of 6 and a scale of 3, for instance.
The maximum precision of NUMERIC, NUMERICSA, and DECIMAL data types is 64. The maximum precision of NUMERICSTS and NUMERICSLS is 63 because it reserves one byte for the plus or minus sign.
Precision and scale are fixed for all numeric data types except DECIMAL. An arithmetic operation on two expressions of the same data type results in the same data type, with the precision and scale for that type. If the operation involves expressions with different data types, the precedence rules determine the data type of the result. The result has the precision and scale defined for its data type.
The result is a DECIMAL for operations under the following conditions:
•Both expressions are DECIMAL.
•One expression is DECIMAL and the other is a data type with a precedence lower than DECIMAL.
Table 114 defines how precision and scale are derived when the result of an operation is of data type DECIMAL. Exp stands for expression, s stands for scale, and p stands for precision.
Table 114 Calculation of Precision and Scale for DECIMAL Operation
Operation
Precision
Scale
Addition (exp1 + exp2)
max(s1, s2) + max(p1 - s1, p2 - s2) +1
max(s1, s2)
Subtraction (exp1 - exp2)
max(s1, s2) + max(p1 - s1, p2 - s2) +1
max(s1, s2)
Multiplication (exp1 * exp2)
p1 + p2 + 1
s1 + s2
Division (exp1 / exp2)
p1 - s1 + s2 + max(6, s1 + p2 +1)
max(6, s1 + p2 +1)
UNION (exp1 UNION exp2)
max(s1, s2) + max(p1 - s1, p2 - s2) +1
max(s1, s2)
For example, if you add or subtract two fields defined as DECIMAL(8,2) and DECIMAL(7,4), the resulting field is DECIMAL(11,4).
Scale of Time Stamp Data Types and Returned Function Values
In time stamp data types, scale is the number of digits to the right of the decimal point in the fractional second part of the time stamp. For instance, 2019-12-31 23:59:59.782 has a scale of 3, or milliseconds.
Starting in Zen 14.10, you can choose the scale for the TIMESTAMP and TIMESTAMP2 data types. For example, the following SQL script creates a table with four columns, the first two using TIMESTAMP and TIMESTAMP2 with default scale, and the second two setting the scale to one decimal point:
Note that shortening the scale does not round fractional seconds.
The following table lists Zen data types that support date and time stamps with scale.
Data Type
Format with Default Scale
Scale
AUTOTIMESTAMP
yyyy-mm-dd hh:mm:ss.nnnnnnnnn (nanoseconds)
9
DATETIME
yyyy-mm-dd hh:mm:ss.nnn (milliseconds)
3
TIMESTAMP
yyyy-mm-dd hh:mm:ss.nnn (milliseconds)
3
TIMESTAMP(n)
yyyy-mm-dd hh:mm:ss.nnnnnnn (none up to septaseconds)
0–7
TIMESTAMP2
yyyy-mm-dd hh:mm:ss.nnnnnnnnn (nanoseconds)
9
TIMESTAMP2(n)
yyyy-mm-dd hh:mm:ss.nnnnnnnnn (none up to nanoseconds)
0–9
The following table lists Zen scalar functions that return date and time stamp values with scale.
Function
Format
Scale
CURRENT_TIMESTAMP()
yyyy-mm-dd hh:mm:ss.nnn (milliseconds)
3
NOW()
yyyy-mm-dd hh:mm:ss.nnn (milliseconds)
3
SYSDATETIME()
yyyy-mm-dd hh:mm:ss.nnnnnnnnn (nanoseconds)
9
SYSUTCDATETIME()
yyyy-mm-dd hh:mm:ss.nnnnnnnnn (nanoseconds)
9
If the time stamp returned by a function has smaller scale than the data type of the column to which it is written, then trailing decimal places are filled with zeros. For example, the value 2019-12-10 14:23:46.292000000 is returned by CURRENT_TIMESTAMP() in a TIMESTAMP2 column.
Truncation
If your application runs against different SQL DBMS products, you may encounter the following issues pertaining to truncation.
In certain situations, some SQL DBMS products prevent insertion of data because of truncation, while Zen allows the insertion of that same data. Additionally, reporting of SQL_SUCCESS_WITH_INFO and the information being truncated differs in Zen from some SQL DMBS products in certain scenarios based on when the message is reported.
Numeric string data and true numeric data are always truncated by Zen, whereas other SQL DBMS products round the data. For example, if you have a numeric string or true numeric value of 123.457 and you insert it into a 6-byte string column or precision 2 numeric column, Zen always inserts 123.45. Other DBMS products, by comparison, may insert a value of 123.46.
Notes on Data Types
This topic covers various behaviors and key information regarding the available data types.
CHAR, NCHAR, VARCHAR, NVARCHAR, LONGVARCHAR, and NLONGVARCHAR
•CHAR and NCHAR columns are padded with trailing blanks. These blanks are not counted in comparison operations (LIKE and =). However, in the LIKE case, if a space is explicitly entered in the query (like 'abc %'), then the space before the wild card is counted. In this example you are looking for 'abc<space><any other character>'.
•The CHAR types store characters using the database code page, that is, using one or more bytes per character. The NCHAR types store characters as UCS-2 two-byte values.
•VARCHAR, NVARCHAR, LONGVARCHAR, and NLONGVARCHAR values are not padded with trailing blanks. The significant data is terminated with a NULL character.
•Trailing blanks are significant in VARCHAR and NVARCHAR comparison operations. For example, c1 = 'Test ' does not find rows where c1 is a VARCHAR type containing the value 'Test'.
•LONGVARBINARY columns are not padded with trailing blanks.
•The database engine does not compare LONGVARBINARY columns. The database engine does compare fixed-length BINARY data.
Zen supports multiple LONGVARCHAR and LONGVARBINARY columns per table. The data is stored according to the offset in the variable length portion of the record. The variable length portion of data can vary from the column order of the data depending on how the data is manipulated. Consider the following example:
CREATE TABLE BlobDataTest
(
Nbr UINT, // Fixed record (Type 14)
Clob1 LONGVARCHAR, // Fixed record (Type 21)
Clob2 LONGVARCHAR, // Fixed record (Type 21)
Blob1 LONGVARBINARY, // Fixed record (Type 21)
)
On disk, the physical record would normally look like this:
[Fixed Data (Nbr, Clob1header, Clob2header, Blob1header)][ClobData1][ClobData2][BlobData1]
Now alter column Nbr to a LONGVARCHAR column:
ALTER TABLE BlobDataTest ALTER Nbr LONGVARCHAR
On disk, the physical record now looks like this:
[Fixed Data (Nbrheader, Clob1header, Clob2header, Blob1header)][ClobData1][ClobData2][BlobData1] [NbrClobData]
As you can see, the variable length portion of the data is not in the column order for the existing data.
For newly inserted records, however, the variable length portion of the data is in the column order for the existing data. This assumes that all columns have data assigned (the columns are not NULL).
[Fixed Data (Nbrheader, Clob1header, Clob2header, Blob1header)][NbrClobData][ClobData1][ClobData2] [BlobData1]
Limitations on LONGVARCHAR, NLONGVARCHAR and LONGVARBINARY
The following limitations apply to the LONGVARCHAR and LONGVARBINARY data types:
•The LIKE predicate operates on the first 65500 bytes of the column data.
•All other predicates operate on the first 256 bytes of the column data.
•SELECT statements with GROUP BY, DISTINCT, and ORDER BY return all the data but only order on the first 256 bytes of the column data.
•Though the maximum amount of data that can be inserted into a LONGVARCHAR/LONGVARBINARY column is 2GB, using a literal in an INSERT statement reduces this amount to 15000 bytes. You can insert more than 15000 bytes by using a parameterized insert.
•The maximum number of bytes returned in a single call by Zen for a LONGVARCHAR, NLONGVARCHAR or LONGVARBINARY columns depends on the access method used by the application. In most cases, the limit is 65500 bytes. For more information, see the documentation for your specific development environment.
DATETIME
The DATETIME data type represents a date and time value. This type is stored internally as two 4-byte integers. The first four bytes store the number of days before or after the base date of January 1, 1900. The other four bytes store the time of day, represented as the number of milliseconds after midnight.
The DATETIME data type can be indexed. The accuracy of DATETIME is 1 millisecond.
DATETIME is a relational data type only. No corresponding Btrieve data type is available.
Format of DATETIME
The format for DATETIME is YYYY-MM-DD HH:MM:SS.mmm. If you need to truncate the millisecond portion, the CONVERT function offers parameter to do so. The following table gives the data components and their range of values for DATETIME.
Component
Valid Values
Year (YYYY)
1753 to 9999
Month (MM)
01 to 12
Day (DD)
01 to 31
Hour (HH)
00 to 23
Minute (MM)
00 to 59
Second (SS)
00 to 59
Millisecond (mmm)
000 to 999
Compatibility of Date and Time Data Types
If you need to perform addition or subtraction involving date and time data types, we recommend using the scalar functions TIMESTAMPADD(), DATEADD(), TIMESTAMPDIFF(), and DATEDIFF(). The use of these functions is required if your expression includes the newer AUTOTIMESTAMP and TIMESTAMP2 data types. Other data types can in some cases be used directly in expressions with operators. For example, the following statements are valid:
SELECT "Start_Date" + 5 FROM "Class"
SELECT "Finish_Time" – "Start_Time" FROM "Class"
SELECT current_timestamp() – "Log" FROM "Billing"
Some queries may return "incompatible types" or "error in expression" messages if you try to add or subtract values that are not compatible, or if the result would not be valid. For example, the following statements return such errors:
SELECT "Start_Date" + 5.0 FROM "Class"
SELECT "Start_Time" + "Finish_Time" FROM "Class"
SELECT current_timestamp() + "Log" FROM "Billing"
The CONVERT and CAST functions can be used with DATE, DATETIME, TIME, and TIMESTAMP in the ways shown in the following tables.
Any of the supported CONVERT data types except for GUID, BINARY, and LONGVARBINARY. The type parameter for CONVERT requires a prefix of “SQL_.” See CONVERT (exp, type [, style ]).
Note The CONVERT function contains an optional parameter that allows you to truncate the milliseconds portion of DATETIME. See the Convert function under Conversion Functions.
Table 116 Permitted CAST Operations
CAST From
Permitted Resultant Data Type (to)
AUTOTIMESTAMP
DATE, DATETIME, TIME, TIMESTAMP, TIMESTAMP2, VARCHAR
DATE
DATE, DATETIME, TIMESTAMP, VARCHAR
DATETIME
Any of the relational data types
TIME
TIME, DATETIME, TIMESTAMP, TIMESTAMP2, VARCHAR
TIMESTAMP
DATE, DATETIME, TIME, TIMESTAMP, TIMESTAMP2, VARCHAR
TIMESTAMP2
DATE, DATETIME, TIME, TIMESTAMP, TIMESTAMP2, VARCHAR
VARCHAR
DATE, DATETIME, TIME, TIMESTAMP, TIMESTAMP2
UNIQUEIDENTIFIER
The UNIQUEIDENTIFIER data type is a 16-byte binary value known as a globally unique identifier (GUID). A GUID is useful when a row must be unique among other rows.
UNIQUEIDENTIFIER requires a file format of 9.5 or higher.
You can initialize a column or local variable of UNIQUEIDENTIFIER the following ways:
•By using the NEWID() scalar function. See NEWID().
•By providing a quoted string in the form 'xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx' in which each x is a hexadecimal digit in the range 0-9 or A-F. For example, '1129619D-772C-AAAB-B221-00FF00FF0099' is a valid UNIQUEIDENTIFIER value.
If you provide a quoted string, all 32 digits are required. The database engine does not pad a partial string.
You may use only the following comparison operators with UNIQUEIDENTIFIER values:
Operator
Meaning
=
Equals
<> or !=
Not equal to
<
Less than
>
Greater than
<=
Less than or equal to
>=
Greater than or equal to
IS NULL
the value is NULL
IS NOT NULL
the value is not NULL
Note that ordering is not implemented by comparing the bit patterns of the two values.
Declaring Variables
You may declare variables of the UNIQUEIDENTIFIER data type and set the variable value with the SET statement.
DECLARE :Cust_ID UNIQUEIDENTIFIER DEFAULT NEWID()
DECLARE :ISO_ID uniqueidentifier
SET :ISO_ID = '1129619D-772C-AAAB-B221-00FF00FF0099'
Converting UNIQUEIDENTIFIER to Another Data Type
The UNIQUEIDENTIFER can be converted with the CAST or CONVERT scalar functions to any of the following data types:
When Zen is required by an application to represent infinity, it can do so in either a 4-byte (C float type) or 8-byte (C double type) form, and in either a hexadecimal or character representation, as shown in the following table.
Table 117 Infinity Representation
Value
Float Hexadecimal
Float Character
Double Hexadecimal
Double Character
Maximum Positive
0x7FEFFFFFFFFFFFFF
Maximum Negative
0xFFEFFFFFFFFFFFFF
Infinity Positive
0x7F800000
1E999
0x7FF0000000000000
1E999
Infinity Negative
0xFF800000
-1E999
0xFFF0000000000000
-1E999
Legacy Data Types
Some older (legacy) data types are not supported in the current release of Zen. The following table shows the new data type to use in place of the legacy data type.
Table 118 Data Types Used to Replace Legacy Data Types
Legacy Type
Type Code
Replaced by
Type Code
LOGICAL(1)
7
BIT
16
LOGICAL(2)
7
SMALLINT
14
LSTRING
10
VARCHAR
11
LVAR
13
LONGVARCHAR
21
NOTE
12
LONGVARCHAR
21
Existing databases that use these data types are supported and function correctly. New databases cannot create tables with the legacy data types. However, a table with legacy data types can be added to the DDFs for a new database with the IN DICTIONARY clause. See CREATE TABLE.
Btrieve Key Data Types
This topic discusses the Btrieve data types that can be indexed (key types). Internally, the MicroKernel compares string keys on a byte-by-byte basis, from left to right. By default, the MicroKernel sorts string keys according to their ASCII value. You may, however, define string keys to be case insensitive or to use an alternate collating sequence (ACS).
The MicroKernel compares unsigned binary keys one word at a time. It compares these keys from right to left because the Intel 8086 family of processors reverses the high and low bytes in an integer.
If a particular data type is available in more than one size (for example, both 4- and 8-byte FLOAT values are allowed), the Key Length parameter (used in the creation of a new key) defines the size that will be expected for all values of that particular key. Any attempt to define a key using a key length that is not allowed results in a status 29 (Invalid Key Length).
The following table lists the key types and their associated codes. Following the table is a discussion of the internal storage formats for each key type.
The AUTOINCREMENT key type is a signed Intel integer that can be either 2, 4, or 8 bytes long. Internally, autoincrement keys are stored in Intel binary integer format, with the high-order and low-order bytes reversed within a word. The MicroKernel sorts autoincrement keys by their absolute (positive) values, comparing the values stored in different records a word at a time from right to left. Autoincrement keys may be used to automatically assign the next highest value when a record is inserted into a file. Because the values are sorted by absolute value, the number of possible records is roughly half what you would expect given that the data type is signed.
Values that have been deleted from the file are not reused automatically. If you indicate that you want the database engine to assign the next value by entering a zero (0) value in an insert or update, the database simply finds the highest number, adds 1, and inserts the resulting value.
You can initialize the value of a field in all or some records to zero and later add an index of type AUTOINCREMENT. This feature allows you to prepare for an autoincrement key without actually building the index until it is needed.
When you add the index, the MicroKernel changes the zero values in each field appropriately, beginning its numbering with a value equal to the greatest value currently defined in the field, plus one. If nonzero values exist in the field, the MicroKernel does not alter them. However, the MicroKernel returns an error status code if nonzero duplicate values exist in the field.
The MicroKernel maintains the highest previously used autoincrement value associated with each open file containing an autoincrement key. This value is established and increments only when an INSERT operation occurs for a record with ASCII zeros in the autoincrement field. The value is used by all clients so that concurrent changes can take place, taking advantage of key page concurrency.
The next autoincrement value for a file is raised whenever any INSERT occurs that uses the previous autoincrement value. This happens whether or not the INSERT is in a transaction or the change is committed.
However, this value may be lowered during an INSERT if all of the following are true:
•The highest autoincrement value found in the key is lower than the next autoincrement value for the file.
•No other client has a pending transaction affecting the page that contains the highest autoincrement value.
•The key page containing the highest autoincrement value is not already pending by the client doing the INSERT.
In other words, only the first INSERT within a transaction can lower the next available autoincrement value. After that, the next available autoincrement value simply keeps incrementing.
An example helps clarify how an autoincrement value may be lowered. Assume an autoincrement file exists with records 1, 2, 3, and 4. The next available autoincrement value is 5.
Client1 begins a transaction and inserts two new records, raising the next available autoincrement value to 7. (Client1 gets values 5 and 6). Client2 begins a transaction and also inserts two new records. This raises the next available autoincrement value to 9. (Client 2 gets values 7 and 8).
Client1 the deletes records 4, 5, and 6. The next autoincrement value remains the same, since it is adjusted only on INSERT. Client1 then commits. The committed version of the file now contains records 1, 2, and 3.
For Client2, the file contains records 1, 2, 3, 7, and 8 (7 and 8 are not yet committed). Client2 then inserts another record, which becomes record 9. The next available autoincrement value is raised to 10. Client2 deletes records 3, 7, 8, and 9. For Client2, the file now contains only the committed records 1 and 2.
Next Client2 inserts another record, which becomes record 10. The next available autoincrement value is raised to 11. The next autoincrement value is not lowered to 3 since the page containing the change has other changes pending on it.
Client2 then aborts the transaction. The committed version of the file now contains records 1, 2, and 3, but the next available autoincrement value is still 11.
If either client inserts another record, whether or not in a transaction, the next available autoincrement value is lowered to 4. This occurs because all of the conditions required for lowering the value are true.
If a resulting autoincrement value is out of range, a Status Code 5 results. The database engine does not attempt to “wrap” the values and start again from zero. You may, however, insert unused values directly if you know of gaps in the autoincrement sequence where a previously inserted value has been deleted.
Restrictions
The following restrictions apply to keys of type AUTOINCREMENT:
•The key must be defined as unique.
•The key cannot be segmented. However, an autoincrement key can be included as an integer segment of another key, as long as the autoincrement key has been defined as a separate, single key first, and the autoincrement key number is lower than the segmented key number.
•The key cannot overlap another key.
•All keys must be ascending.
The MicroKernel treats autoincrement key values as follows when you insert records into a file:
•If you specify a value of binary 0 for the autoincrement key, the MicroKernel assigns a value to the key based on the following criteria:
•If you are inserting the first record in the file, the MicroKernel assigns the value of 1 to the autoincrement key.
•If records already exist in the file, the MicroKernel assigns the key a value that is one number higher than the highest existing absolute value in the file.
•If you specify a positive, nonzero value for the autoincrement key, the MicroKernel inserts the record into the file and uses the specified value as the key value. If a record containing that value already exists in the file, the MicroKernel returns an error status code and does not insert the record.
AUTOTIMESTAMP
The AUTOTIMESTAMP key type is an 8-byte unsigned integer for tracking time in nanoseconds based on the Unix epoch. A value of zero prompts the database engine to replace it automatically with the current time when a new record is inserted or the first time an existing record is updated. A nonzero value is allowed and is interpreted as a number of nanoseconds since 1970 UTC.
This key type is available starting in Zen v14 for file formats 9.5 and 13.0. Older database engines that attempt to open a file that has a record that uses this type will return status code 30 for an unrecognized Microkernel file.
The range of AUTOTIMESTAMP values is 1970-01-01 00:00:00.000000000 to 2554-07-21 23:34:33.709551615.
Current Linux and Android system clocks provide true nanosecond resolution. On Windows the highest resolution is septaseconds (10-7 second), and on macOS the highest is microseconds. When an AUTOTIMESTAMP key is written on systems that do not support nanosecond resolution, the value is padded with zeros. Accordingly, inserts or updates on these systems without nanosecond resolution can result in duplicate values. However, if the index is set to be unique and the database engine detects a match with the most recent previously generated time stamp, then it adds 1 nanosecond. Duplication can also result from a manually inserted time stamp value or from the resetting of the system clock. In both of these cases, Insert (2) or Update (3) fails with status code 5.
Inserts and Updates Using AUTOTIMESTAMP
Insert (2) and Update (3) operations handle a zero value for an AUTOTIMESTAMP key by retrieving the current time stamp from the system clock on the database engine server. The engine then uses this value in the current record for every AUTOTIMESTAMP key that contains a zero.
For Insert Extended (40), the engine retrieves a new time stamp value for each specified record in the operation. If the AUTOTIMESTAMP key is unique, the engine avoids time stamp duplication among the records by incrementing the generated value by 1 nanosecond if it matches a previously generated time stamp within the operation. As with Insert (2), the time stamp generated for each record is used for all AUTOTIMESTAMP keys in that record.
When an Update Chunk (53) operation attempts to write to the fixed portion of a record that includes an AUTOTIMESTAMP key, the engine does not retrieve a new time stamp. Instead, the provided key value is accepted as is and placed in the record. Therefore, using an Update Chunk operation with a zero value to update an AUTOTIMESTAMP key results in storing the zero value in the record, which is then interpreted as 1970 UTC. If you wish to update the key with an automatically generated time stamp, use the Update (3) operation to update the fixed portion of a record.
Restrictions
The following restrictions apply when you create a key of type AUTOTIMESTAMP:
•The NOCASE flag cannot be applied to the key.
•NULL_KEY and MANUAL_KEY are not allowed, since the time stamp cannot be excluded from the index.
Usage in Function Executor and Maintenance Tools
The use of AUTOTIMESTAMP keys in Function Executor or the Maintenance tool is similar to AUTOINCREMENT keys. For the files that use them, the key type is listed as Atstamp, which also appears in the output of butil <filename> -stat and is used for the key type in the description file for a butil -create command.
BFLOAT
The BFLOAT key type is a single or double-precision real number. A single-precision real number is stored with a 23-bit mantissa, an 8-bit exponent biased by 128, and a sign bit. The internal layout for a 4-byte float is as follows:
The representation of a double-precision real number is the same as that for a single-precision real number, except that the mantissa is 55 bits instead of 23 bits. The least significant 32 bits are stored in bytes 0 through 3.
The BFLOAT type is commonly used in legacy BASIC applications. Microsoft refers to this data type as MBF (Microsoft Binary Format), and no longer supports this type in the Visual Basic environment. New database definitions should use FLOAT rather than BFLOAT.
STRING
The STRING key type is a sequence of characters ordered from left to right. Each character is represented in ASCII format in a single byte, except when the MicroKernel is determining whether a key value is null. STRING data is expected to be padded with blanks to the full size of the key.
CURRENCY
The CURRENCY key type represents an 8-byte signed quantity, sorted and stored in Intel binary integer format. Therefore, its internal representation is the same as an 8-byte INTEGER data type. The CURRENCY data type has an implied four digit scale of decimal places, which represents the fractional component of the currency data value.
DATE
The DATE key type is stored internally as a 4-byte value. The day and the month are each stored in 1-byte binary format. The year is a 2-byte binary number that represents the entire year value. The MicroKernel places the day into the first byte, the month into the second byte, and the year into a two-byte word following the month.
An example of C structure used for date fields would be:
TYPE dateField { char day; char month; integer year; }
The year portion of a date field is expected to be set to the integer representation of the entire year. For example, 2,001 for the year 2001.
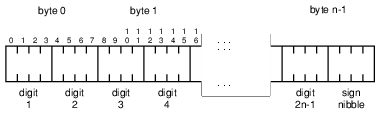
DECIMAL
The DECIMAL key type is stored internally as a packed decimal number with two decimal digits per byte. The internal representation for an n-byte DECIMAL field is as follows:
The decimal point for DECIMAL is implied. No decimal point is stored in the DECIMAL field. Your application is responsible for tracking the location of the decimal point for the value in a DECIMAL field. All values for a DECIMAL key type must have the same number of decimal places for the database engine to collate the key correctly. The DECIMAL type is commonly used in COBOL applications.
An eight-byte decimal can hold 15 digits plus the sign. A ten-byte decimal can hold 19 digits plus the sign. The decimal value is expected to be left-padded with zeros.
The sign nibble is either 0xF or 0xC for positive numbers and 0xD for negative numbers. By default, the Relational Engine and the SDK access methods that use it always write 0xF as the positive sign nibble for a DECIMAL. They can interpret both 0xF and 0xC as being positive on a read operation.
A setting in the registry (Windows Registry and Zen Registry) controls what the database engine uses for the positive sign nibble for a DECIMAL. If you need to change the default positive sign nibble to 0xC, edit the registry as explained below. Note that the Zen ActiveX access method always uses 0xF for the positive sign nibble regardless of the registry setting for CommonCOBOLDecimalSign.
Windows
In Registry Editor, change the value of CommonCOBOLDecimalSign to yes for the following key:
In most Windows systems, the key is under HKEY_LOCAL_MACHINE\SOFTWARE\Actian\Zen. However, its location below HKEY_LOCAL_MACHINE\SOFTWARE can vary depending on the operating system.
Caution Editing the registry is an advanced procedure. If done improperly, the editing could cause your operating system not to boot. If necessary, obtain the services of a qualified technician to perform the editing. Actian Corporation does not accept responsibility for a damaged registry.
Linux and macOS
For Linux 32-bit operating systems, run the psregedit utility as follows:
Caution Precision beyond that supported by the C-language definitions for the FLOAT (4-byte) or DOUBLE (8-byte) data type will be lost. If you require precision to many decimal points, consider using the DECIMAL type.
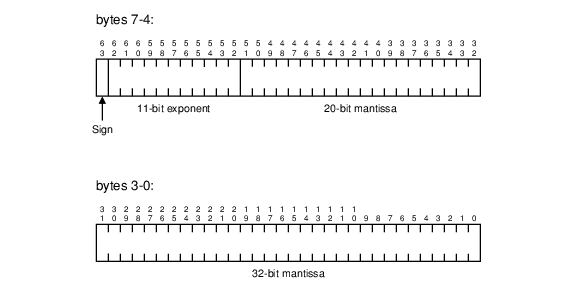
The FLOAT key type is consistent with the IEEE standard for single and double-precision real numbers. The internal format for a 4-byte FLOAT consists of a 23-bit mantissa, an 8-bit exponent biased by 127, and a sign bit, as follows:
A FLOAT key with 8 bytes has a 52-bit mantissa, an 11-bit exponent biased by 1023, and a sign bit. The internal format is as follows:
GUID
The GUID key type is a 16-byte number that is stored internally as a 16-byte binary value. Its extended data type value is 27.
GUIDs are commonly used as globally unique identifiers. The corresponding data type for the Relational Engine is UNIQUEIDENTIFIER.
Note that GUID requires a file format of 9.5 or higher.
GUID Keys
The sort order for the bytes composing the GUID are compared in the following sequence: 10, 11, 12, 13, 14, 15, 8, 9, 6, 7, 4, 5, 0, 1, 2, 3.
The key segment length for a GUID must be 16 bytes. See Key Specification Block in Btrieve API Guide.
INTEGER
The INTEGER key type is a signed whole number and can contain any number of digits. Internally, INTEGER fields are stored in Intel binary integer format, with the high-order and low-order bytes reversed within a word. The MicroKernel evaluates the key from right to left. The sign must be stored in the high bit of the rightmost byte. The INTEGER type is supported by most development environments.
Table 120 INTEGER Key Type
Length in Bytes
Value Ranges
1
0 – 255
2
-32768 – 32767
4
-2147483648 – 2147483647
8
-9223372036854775808 – 9223372036854775807
LOGICAL
The LOGICAL key type is stored as a 1 or 2-byte value. The MicroKernel collates LOGICAL key types as strings. Doing so allows your application to determine the stored values that represent true or false.
LSTRING
The LSTRING key type has the same characteristics as a regular STRING type, except that the first byte of the string contains the binary representation of the string length. The LSTRING key type is limited to a maximum size of 255 bytes. The length stored in byte 0 of an LSTRING key determines the number of significant bytes. The database engine ignores any values beyond the specified length of the string when sorting or searching for values. The LSTRING type is commonly used in legacy Pascal applications.
MONEY
The MONEY key type has the same internal representation as the DECIMAL type, with an implied two decimal places.
NUMERIC
Each digit of a NUMERIC key type occupies one byte. NUMERIC values are stored as ASCII strings right-aligned with leading zeros. The rightmost byte includes an embedded sign with an EBCDIC value. By default, the sign value for positive NUMERIC data types is an unsigned numeric number.
Optionally, you may specify that you want to shift the value of the sign for positive NUMERIC data types. The following table compares the sign values in the default (unshifted) and shifted states.
Table 121 Comparison of Shifted and Unshifted Sign Values for NUMERICS
Digit
Default (unshifted) Sign Value
Shifted Sign Value
Positive
Negative
Positive
Negative
1
1
J
A
J
2
2
K
B
K
3
3
L
C
L
4
4
M
D
M
5
5
N
E
N
6
6
O
F
O
7
7
P
G
P
8
8
Q
H
Q
9
9
R
I
R
0
0
}
{
}
Enabling the Shifted Format
You must manually specify a setting on the machine running the Zen database engine to enable the shifted format. The setting DBCobolNumeric must be set to yes. The rest of this topic summarizes use of this setting on Windows 32-bit, Linux, and macOS platforms.
Windows 32-Bit
Using the Registry Editor, add the DBCobolNumeric setting as a string value to the following key:
In most Windows systems, the key is HKEY_LOCAL_MACHINE\SOFTWARE\Actian\Zen, but its location under HKEY_LOCAL_MACHINE\SOFTWARE varies depending on the operating system.
Caution If the Windows registry is edited improperly, Windows may be unable to start. Only a trained IT person should do the editing. Actian Corporation does not accept responsibility for a damaged Windows registry.
Stop and restart the database engine or the engine services.
Linux and macOS
Add the DBCobolNumeric setting to bti.ini below the [Database Names] entry:
[Database Names] DBCobolNumeric=yes
By default, bti.ini is located in the /usr/local/actianzen/etc directory.
Stop and restart the database engine.
Consistent Sign Values for Positive NUMERIC Data
You may already have positive NUMERIC data with the sign value in the default (unshifted) format. If you set DBCobolNumeric to yes and continue adding data to the same table, mixed formats result. Leaving your data with mixed formats for the sign value is not recommended.
To correct or prevent a condition of mixed formats, use the UPDATE statement to update NUMERIC columns to themselves. For example, suppose that table t1 contains column c1 that is a NUMERIC data type. After you set DBCobolNumeric to yes, update c1 as follows: UPDATE TABLE t1 SET c1 = c1.
NUMERICSA
The NUMERICSA key type (sometimes called NUMERIC SIGNED ASCII) is a COBOL data type identical to NUMERIC, except that the embedded sign has an ASCII instead of an EBCDIC value.
Table 122 Sign Values for NUMERICSA
Digit
Default Sign Value
Positive
Negative
1
1 or Q
q
2
2 or R
r
3
3 or S
s
4
4 or T
t
5
5 or U
u
6
6 or V
v
7
7 or W
w
8
8 or X
x
9
9 or Y
y
0
0 or P
p
NUMERICSLB
The NUMERICSLB key type (sometimes called SIGN LEADING with COBOL compiler option -dcb) is a COBOL data type that has values resembling those of the NUMERIC data type. NUMERICSLB values are stored as ASCII strings and right justified with leading zeros.
Table 123 Sign Values for NUMERICSLB
Digit
Default Sign Value
Positive
Negative
1
1
A
2
2
B
3
3
C
4
4
D
5
5
E
6
6
F
7
7
G
8
8
H
9
9
I
0
0
@
NUMERICSLS
The NUMERICSLS key type (sometimes called SIGN LEADING SEPARATE) is a COBOL data type that has values resembling those of the NUMERIC data type. NUMERICSLS values are stored as ASCII strings and left justified with leading zeros. However, the leftmost byte of a NUMERICSLS string is either “+” (ASCII 0x2B) or “-” (ASCII 0x2D). This differs from NUMERIC values that embed the sign in the rightmost byte along with the value of that byte.
NUMERICSTB
The NUMERICSTB key type (sometimes called SIGN TRAILING with COBOL compiler option -dcb) is a COBOL data type that has values resembling those of the NUMERIC data type. NUMERICSTB values are stored as ASCII strings and right justified with leading zeros.
Table 124 Sign Values for NUMERICSTB
Digit
Default Sign Value
Positive
Negative
1
1
A
2
2
B
3
3
C
4
4
D
5
5
E
6
6
F
7
7
G
8
8
H
9
9
I
0
0
@
NUMERICSTS
The NUMERICSTS key type (sometimes called SIGN TRAILING SEPARATE) is a COBOL data type that has values resembling those of the NUMERIC data type. NUMERICSTS values are stored as ASCII strings and right justified with leading zeros. However, the rightmost byte of a NUMERICSTS string is either “+” (ASCII 0x2B) or “-” (ASCII 0x2D). This differs from NUMERIC values that embed the sign in the rightmost byte along with the value of that byte.
TIME
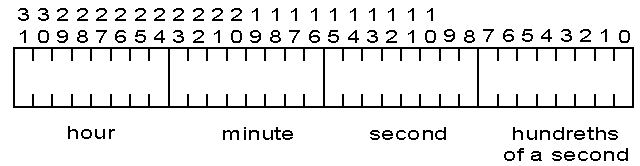
The TIME key type is stored internally as a 4-byte value. Hundredths of a second, second, minute, and hour values are each stored in 1-byte binary format. The MicroKernel places the hundredths of a second value in the first byte, followed respectively by the second, minute, and hour values. The data format is hh:mm:ss.nn. Supported values range from 00:00:00.00 to 23:59:59.99.
TIMESTAMP
The TIMESTAMP key type represents a time and date value. In SQL applications, use this data type to stamp a record with the current time and date of the last update to the record. TIMESTAMP values are stored in 8-byte unsigned values representing septaseconds (10^-7 second) since January 1, 0001 in a Gregorian calendar, Coordinated Universal Time (UTC). Supported values range from 0001-01-01 00:00:00.0000000 to 9999-12-31 23:59:59.9999999.
Unlike AUTOTIMESTAMP, a value of zero is not automatically replaced with the current time when a new record is inserted or the first time an existing record is updated.
Note According to the ODBC standard, scalar functions such as CURRENT_TIMESTAMP() or NOW() ignore the portion of the data type that represents fractional seconds. It is important to note that when these functions are used, Zen does not ignore fractional seconds and displays three digits for milliseconds.
TIMESTAMP supports time and data values made up of the following components: year, month, day, hour, minute, second, and millisecond. The following table indicates the range of valid values for each of these components.
YEAR
0001 to 9999
MONTH
01 to 12
DAY
01 to 31, constrained by the value of MONTH and YEAR in the Gregorian calendar.
HOUR
00 to 23
MINUTE
00 to 59
SECOND
00 to 59
MILLISECOND
000 to 999. Default setting. Scale can be set to a value of 0 to 7 (septaseconds).
Each TIMESTAMP value contains a complete date and time value with the maximum scale supported by the local operating system, filled if needed with trailing zeros. When this value is returned, it uses the scale set for the time stamp. For example, the value is returned in milliseconds when the scale is 3 and microseconds when it is 6.
You provide the value of a TIMESTAMP in local time and the Relational Engine converts it to Coordinated Universal Time (UTC) before storing it in a record. When you request a TIMESTAMP value, the Relational Engine returns it converted back to local time.
Caution It is critical that you correctly set time zone information on the computer where the database engine runs. If you move across time zones or change time zone information, the returned data will change when it is converted from UTC to local time. The local time and UTC conversions occur in the Relational Engine using the time zone information where the Relational Engine is running. The time zone information for sessions that are in time zones different from the Relational Engine engine are not used in the local time and UTC conversions.
Because time stamp data is converted to UTC before it is stored, the TIMESTAMP type is inappropriate for use with local time and local date data that reference events external to the database itself, particularly in time zones where seasonal time changes take place, such as Daylight Savings Time in the United States.
For example, assume it is October 15, and you enter a time stamp value to track an appointment on November 15 at 10 a.m. Assume you are in the U. S. Central Time Zone. When the Relational Engine stores the value, it converts it to UTC using current local time information (UTC-5 hours for CDT). So it stores the hour value 15. Assume, on November 1, you check the time of your appointment. Your computer is now in Standard Time, because of the switch that occurred in October, so the conversion is (UTC-6 hours). When you extract the appointment time, it will show 9 a.m. local time (15 UTC - 6 CST), which is not the correct appointment time.
The same type of issue will occur if a database engine is moved from one time zone to another.
Because the Relational Engine does not convert DATE and TIME values to UTC, you should almost always use DATE and TIME columns to record external data. The only reason to use a TIMESTAMP column is a need for the specific ability to determine the sequential time order of records entered into the database.
Usage in Function Executor and Maintenance Tools
The use of TIMESTAMP keys in Function Executor or the Maintenance tools is similar to AUTOINCREMENT keys. For the files that use them, the key type is listed as Tstamp, which also appears in the output of butil <filename> -stat and is used for the key type in the description file for a butil -create command.
TIMESTAMP2
The TIMESTAMP2 key type tracks time in nanoseconds based on the Unix epoch. In SQL applications, use this data type to stamp a record with the current time and date of the last update to the record. Values are stored in 8-byte unsigned values representing nanoseconds (10^-9 second) since January 1, 1970 in a Gregorian calendar, Coordinated Universal Time (UTC). Supported values range from 1970-01-01 00:00:00.000000000 to 2554-07-21 23:34:33.709551615.
Unlike AUTOTIMESTAMP, a value of zero is not automatically replaced with the current time when a new record is inserted or the first time an existing record is updated.
This key type is available starting in Zen v14 SP1 for file formats 9.5 and 13.0. Older database engines that attempt to open a file that has a record that uses this type will return status code 30 for an unrecognized Microkernel file.
Note According to the ODBC standard, scalar functions such as CURRENT_TIMESTAMP() or NOW() ignore the portion of the data type that represents fractional seconds. It is important to note that when these functions are used, Zen does not ignore fractional seconds and displays nine digits for nanoseconds.
TIMESTAMP2 supports time and data values made up of the following components: year, month, day, hour, minute, second, and nanosecond. The following table indicates the range of valid values for each of these components.
YEAR
1970 to 2554
MONTH
01 to 12
DAY
01 to 31, constrained by the value of MONTH and YEAR in the Gregorian calendar.
HOUR
00 to 23
MINUTE
00 to 59
SECOND
00 to 59
NANOSECOND
000000000 to 999999999. Default setting.
Each TIMESTAMP2 value contains a complete date and time value with the maximum scale supported by the local operating system, filled if needed with trailing zeros. When this value is returned, it uses the scale set for the time stamp. For example, the value is returned in milliseconds when the scale is 3 and microseconds when it is 6.
You provide the value of a TIMESTAMP2 in local time and the Relational Engine converts it to Coordinated Universal Time (UTC) before storing it in a record. When you request a TIMESTAMP2 value, the Relational Engine returns it converted back to local time.
Caution It is critical that you correctly set time zone information on the computer where the database engine runs. If you move across time zones or change time zone information, the returned data will change when it is converted from UTC to local time. The local time and UTC conversions occur in the Relational Engine using the time zone information where the Relational Engine is running. The time zone information for sessions that are in time zones different from the Relational Engine engine are not used in the local time and UTC conversions.
Because time stamp data is converted to UTC before it is stored, the TIMESTAMP2 type is inappropriate for use with local time and local date data that reference events external to the database itself, particularly in time zones where seasonal time changes take place (such as Daylight Savings Time in the United States).
For example, assume it is October 15, and you enter a time stamp value to track an appointment on November 15 at 10 a.m. Assume you are in the U. S. Central Time Zone. When the Relational Engine stores the value, it converts it to UTC using current local time information (UTC-5 hours for CDT). So it stores the hour value 15. Assume, on November 1, you check the time of your appointment. Your computer is now in Standard Time, because of the switch that occurred in October, so the conversion is (UTC-6 hours). When you extract the appointment time, it will show 9 a.m. local time (15 UTC - 6 CST), which is not the correct appointment time.
The same type of issue will occur if a database engine is moved from one time zone to another.
Because the Relational Engine does not convert DATE and TIME values to UTC, you should almost always use DATE and TIME columns to record external data. The only reason to use a TIMESTAMP2 column is a need for the specific ability to determine the sequential time order of records entered into the database.
Usage in Function Executor and Maintenance Tools
The use of TIMESTAMP2 keys in Function Executor or the Maintenance tools is similar to AUTOINCREMENT keys. For the files that use them, the key type is listed as TS2, which also appears in the output of butil <filename> -stat and is used for the key type in the description file for a butil -create command.
UNSIGNED BINARY
UNSIGNED BINARY keys can be any number of bytes up to the maximum key length of 255. UNSIGNED keys are compared byte-for-byte from the most significant byte to the least significant byte. The first byte of the key is the least significant byte. The last byte of the key is the most significant.
The database engine sorts UNSIGNED BINARY keys as unsigned INTEGER keys. The differences are that an INTEGER has a sign bit, while an UNSIGNED BINARY type does not, and an UNSIGNED BINARY key can be longer than 4 bytes.
WSTRING
WSTRING is a Unicode string that is not null-terminated. The length of the string is determined by the field length.
WZSTRING
WZSTRING is a Unicode string that is double null-terminated. The length of this string is determined by the position of the Unicode NULL (two null bytes) within the field. This corresponds to the ZSTRING type supported in Btrieve.
ZSTRING
The ZSTRING key type corresponds to a C string. It has the same characteristics as a regular string type except that a ZSTRING type is terminated by a binary 0. The MicroKernel ignores any values beyond the first binary 0 it encounters in the ZSTRING, except when the MicroKernel is determining whether a key value is null.
The maximum length of a ZSTRING type is 255 bytes, including the null terminator character. If used as a key for a nullable column, only the first 254 bytes of the string are used in the key. This minor limitation occurs because the key is limited to 255 bytes total length, and one byte is occupied by the null indicator for the column, leaving only 254 bytes for the key value.
Non-Key Data Types
This topic discusses the internal storage formats of data types that cannot be indexed (used as Btrieve keys).
BLOB
The Binary Large Object (BLOB) type provides support for binary data fields up to 2 GB in size. This type consists of 2 parts:
•an 8-byte header in the fixed-length portion of the record. The header contains a 4-byte integer that identifies the offset to the beginning of the data in the variable-length portion of the record, and a 4-byte integer that specifies the size of the data.
•the binary data itself is stored within the variable-length portion of the record. The size of all BLOB and CLOB fields must sum to 2 GB or less, because the offset pointer into the variable-length portion of the record is limited to 2 GB maximum offset. To store the maximum BLOB size of 2 GB, you may have only 1 BLOB or CLOB field defined in the record.
The Character Large Object (CLOB) type provides support for character data fields up to 2 GB in size. This type consists of 2 parts:
•An 8-byte header in the fixed-length portion of the record. The header contains a 4-byte integer that identifies the offset to the beginning of the data in the variable-length portion of the record, and a 4-byte integer that specifies the size of the data in bytes.
•The character data itself is stored within the variable-length portion of the record. The size of all BLOB and CLOB fields must sum to 2 GB or less, because the offset pointer into the variable-length portion of the record is limited to 2 GB maximum offset. To store the maximum BLOB size of 2 GB, you may have only 1 BLOB or CLOB field defined in the record.