Loading Delimited Text Data from Cloud Data Storage
Introduction to Loading Delimited Text Data
Note: Before using this method, be sure to read Overview of SQL-Based Data Loading.
You can load delimited text data using the following Actian Data Platform loading methods:
The cloud object stores currently supported are AWS S3, Azure Blob Storage, and Google Cloud.
To load data using the COPY VWLOAD statement, you must provide credentials as part of the COPY VWLOAD SQL. For external tables, you must set the credentials in the Actian Data Platform console. For more information, see Set Up Access Credentials for Cloud Storage Accounts.
Delimiter text file switches are defined in Delimiter Text File Switches.
To use the Actian SQL CLI for issuing SQL commands, see Actian SQL CLI.
Loading Delimited Text Data Using COPY VWLOAD (SQL)
Prior to using COPY VWLOAD, it is important that you have read the overview documentation about data loading: Overview of SQL-Based Data Loading.
Note: Before you can access data in cloud object storage, you must set up cloud authentication credentials for your warehouse. See Set Up Access Credentials for Cloud Storage Accounts.
Loading Delimited Text Data from Google Cloud Storage Using COPY VWLOAD
Shown below are some examples of how to load delimited text data stored on Google Cloud using COPY VWLOAD.
Example 1: COPY VWLOAD SQL to load a delimited text file with header row
Here is a sample of the data file stored as a CSV file with header on Google Cloud:
ID,Title,Year,Age,IMDb,RottenTomatoes,Netflix,Hulu,PrimeVideo,Disney,Type
0,Breaking Bad,2008,18+,9.5,96%,1,0,0,0,1
1,Stranger Things,2016,16+,8.8,93%,1,0,0,0,1
2,Money Heist,2017,18+,8.4,91%,1,0,0,0,1
3,Sherlock,2010,16+,9.1,78%,1,0,0,0,1
4,Better Call Saul,2015,18+,8.7,97%,1,0,0,0,1
5,The Office,2005,16+,8.9,81%,1,0,0,0,1
6,Black Mirror,2011,18+,8.8,83%,1,0,0,0,1
7,Supernatural,2005,16+,8.4,93%,1,0,0,0,1
8,Peaky Blinders,2013,18+,8.8,92%,1,0,0,0,1
0,Breaking Bad,2008,18+,9.5,96%,1,0,0,0,1
1,Stranger Things,2016,16+,8.8,93%,1,0,0,0,1
2,Money Heist,2017,18+,8.4,91%,1,0,0,0,1
3,Sherlock,2010,16+,9.1,78%,1,0,0,0,1
4,Better Call Saul,2015,18+,8.7,97%,1,0,0,0,1
5,The Office,2005,16+,8.9,81%,1,0,0,0,1
6,Black Mirror,2011,18+,8.8,83%,1,0,0,0,1
7,Supernatural,2005,16+,8.4,93%,1,0,0,0,1
8,Peaky Blinders,2013,18+,8.8,92%,1,0,0,0,1
DROP TABLE IF EXISTS tvshows;
CREATE TABLE tvshows (
id INTEGER,
title VARCHAR(70),
year INTEGER,
age VARCHAR(5),
imdb FLOAT,
rottentomatoes VARCHAR(5),
netflix INTEGER,
hulu INTEGER,
primevideo INTEGER,
disney INTEGER,
type INTEGER);
COPY tvshows() VWLOAD FROM 'gs://television/data/shows.tbl/tv_shows.csv'
WITH
GCS_EMAIL = 'jane.doe@acme.com',
GCS_PRIVATE_KEY_ID = '1234',
GCS_PRIVATE_KEY = '-----BEGIN PRIVATE KEY-----\n ... ==\n-----END PRIVATE KEY-----\n'
FDELIM=',',
QUOTE='""',
HEADER;
CREATE STATISTICS FOR tvshows;
SELECT * FROM tvshows;
Note: After the data is loaded, we recommend that you run the CREATE STATISTICS command, as shown above. It improves performance, especially for large data sets.
Example 2: COPY VWLOAD SQL to load a delimited text file with no header row and a comma at the end of each record
Here is a sample of the data file stored as a CSV file with no header and delimiter at end of record on Google Cloud:
0,Breaking Bad,2008,18+,9.5,96%,1,0,0,0,1,
1,Stranger Things,2016,16+,8.8,93%,1,0,0,0,1,
2,Money Heist,2017,18+,8.4,91%,1,0,0,0,1,
3,Sherlock,2010,16+,9.1,78%,1,0,0,0,1,
4,Better Call Saul,2015,18+,8.7,97%,1,0,0,0,1,
5,The Office,2005,16+,8.9,81%,1,0,0,0,1,
6,Black Mirror,2011,18+,8.8,83%,1,0,0,0,1,
7,Supernatural,2005,16+,8.4,93%,1,0,0,0,1,
8,Peaky Blinders,2013,18+,8.8,92%,1,0,0,0,1,
1,Stranger Things,2016,16+,8.8,93%,1,0,0,0,1,
2,Money Heist,2017,18+,8.4,91%,1,0,0,0,1,
3,Sherlock,2010,16+,9.1,78%,1,0,0,0,1,
4,Better Call Saul,2015,18+,8.7,97%,1,0,0,0,1,
5,The Office,2005,16+,8.9,81%,1,0,0,0,1,
6,Black Mirror,2011,18+,8.8,83%,1,0,0,0,1,
7,Supernatural,2005,16+,8.4,93%,1,0,0,0,1,
8,Peaky Blinders,2013,18+,8.8,92%,1,0,0,0,1,
DROP TABLE IF EXISTS tvshows;
CREATE TABLE tvshows (
id INTEGER,
title VARCHAR(70),
year INTEGER,
age VARCHAR(5),
imdb FLOAT,
rottentomatoes VARCHAR(5),
netflix INTEGER,
hulu INTEGER,
primevideo INTEGER,
disney INTEGER,
type INTEGER);
COPY tvshows() VWLOAD FROM 'gs://television/data/shows.tbl/tv_shows.csv'
WITH
GCS_EMAIL = 'jane.doe@acme.com',
GCS_PRIVATE_KEY_ID = '1234',
GCS_PRIVATE_KEY = '-----BEGIN PRIVATE KEY-----\n ... ==\n-----END PRIVATE KEY-----\n'
FDELIM=',',
QUOTE='""',
IGNLAST;
CREATE STATISTICS FOR tvshows;
SELECT * FROM tvshows;
Note: After the data is loaded, we recommend that you run the CREATE STATISTICS command, as shown above. It improves performance, especially for large data sets.
Notes:
1. Column names are case insensitive by default.
2. This CSV file (that is, “TV Shows”) was gotten from the Kaggle public datasets.
3. IGNLAST is used when there is a delimiter at the end of the record.
Loading Delimited Text Data from Azure Blob Storage Using COPY VWLOAD
Shown below are some examples of how to load delimited text data stored on Azure Blob storage using COPY VWLOAD.
Example 1: COPY VWLOAD SQL to load a delimited text file with header row
Here is a sample of the data file stored as a CSV file with header on Azure Blob storage:
ID,Title,Year,Age,IMDb,RottenTomatoes,Netflix,Hulu,PrimeVideo,Disney,Type
0,Breaking Bad,2008,18+,9.5,96%,1,0,0,0,1
1,Stranger Things,2016,16+,8.8,93%,1,0,0,0,1
2,Money Heist,2017,18+,8.4,91%,1,0,0,0,1
3,Sherlock,2010,16+,9.1,78%,1,0,0,0,1
4,Better Call Saul,2015,18+,8.7,97%,1,0,0,0,1
5,The Office,2005,16+,8.9,81%,1,0,0,0,1
6,Black Mirror,2011,18+,8.8,83%,1,0,0,0,1
7,Supernatural,2005,16+,8.4,93%,1,0,0,0,1
8,Peaky Blinders,2013,18+,8.8,92%,1,0,0,0,1
0,Breaking Bad,2008,18+,9.5,96%,1,0,0,0,1
1,Stranger Things,2016,16+,8.8,93%,1,0,0,0,1
2,Money Heist,2017,18+,8.4,91%,1,0,0,0,1
3,Sherlock,2010,16+,9.1,78%,1,0,0,0,1
4,Better Call Saul,2015,18+,8.7,97%,1,0,0,0,1
5,The Office,2005,16+,8.9,81%,1,0,0,0,1
6,Black Mirror,2011,18+,8.8,83%,1,0,0,0,1
7,Supernatural,2005,16+,8.4,93%,1,0,0,0,1
8,Peaky Blinders,2013,18+,8.8,92%,1,0,0,0,1
DROP TABLE IF EXISTS tvshows;
CREATE TABLE tvshows (
id INTEGER,
title VARCHAR(70),
year INTEGER,
age VARCHAR(5),
imdb FLOAT,
rottentomatoes VARCHAR(5),
netflix INTEGER,
hulu INTEGER,
primevideo INTEGER,
disney INTEGER,
type INTEGER);
COPY tvshows() VWLOAD FROM 'abfs://tvshows@avtvshowdata.dfs.core.windows.net/tv_shows.csv'
WITH
AZURE_CLIENT_ENDPOINT='https://login.microsoftonline.com/<azure_directory_id>/oauth2/token',
AZURE_CLIENT_ID='<azure_client_id>',
AZURE_CLIENT_SECRET='<azure_client_secret>',
FDELIM=',',
QUOTE='""',
HEADER;
CREATE STATISTICS FOR tvshows;
SELECT * FROM tvshows;
Note: After the data is loaded, we recommend that you run the CREATE STATISTICS command, as shown above. It improves performance, especially for large data sets.
Example 2: COPY VWLOAD SQL to load a delimited text file with no header row and a comma at the end of each record
Here is a sample of the data file stored as a CSV file with no header and delimiter at end of record on Azure Blob storage:
0,Breaking Bad,2008,18+,9.5,96%,1,0,0,0,1,
1,Stranger Things,2016,16+,8.8,93%,1,0,0,0,1,
2,Money Heist,2017,18+,8.4,91%,1,0,0,0,1,
3,Sherlock,2010,16+,9.1,78%,1,0,0,0,1,
4,Better Call Saul,2015,18+,8.7,97%,1,0,0,0,1,
5,The Office,2005,16+,8.9,81%,1,0,0,0,1,
6,Black Mirror,2011,18+,8.8,83%,1,0,0,0,1,
7,Supernatural,2005,16+,8.4,93%,1,0,0,0,1,
8,Peaky Blinders,2013,18+,8.8,92%,1,0,0,0,1,
1,Stranger Things,2016,16+,8.8,93%,1,0,0,0,1,
2,Money Heist,2017,18+,8.4,91%,1,0,0,0,1,
3,Sherlock,2010,16+,9.1,78%,1,0,0,0,1,
4,Better Call Saul,2015,18+,8.7,97%,1,0,0,0,1,
5,The Office,2005,16+,8.9,81%,1,0,0,0,1,
6,Black Mirror,2011,18+,8.8,83%,1,0,0,0,1,
7,Supernatural,2005,16+,8.4,93%,1,0,0,0,1,
8,Peaky Blinders,2013,18+,8.8,92%,1,0,0,0,1,
DROP TABLE IF EXISTS tvshows;
CREATE TABLE tvshows (
id INTEGER,
title VARCHAR(70),
year INTEGER,
age VARCHAR(5),
imdb FLOAT,
rottentomatoes VARCHAR(5),
netflix INTEGER,
hulu INTEGER,
primevideo INTEGER,
disney INTEGER,
type INTEGER);
COPY tvshows() VWLOAD FROM 'abfs://tvshows@avtvshowdata.dfs.core.windows.net/tv_shows.csv'
WITH
AZURE_CLIENT_ENDPOINT='https://login.microsoftonline.com/<azure_directory_id>/oauth2/token',
AZURE_CLIENT_ID='<azure_client_id>',
AZURE_CLIENT_SECRET='<azure_client_secret>',
FDELIM=',',
QUOTE='""',
IGNLAST;
CREATE STATISTICS FOR tvshows;
SELECT * FROM tvshows;
Note: After the data is loaded, we recommend that you run the CREATE STATISTICS command, as shown above. It improves performance, especially for large data sets.
Notes:
1. Column names are case insensitive by default.
2. This CSV file (that is, “TV Shows”) was gotten from the Kaggle public datasets.
3. IGNLAST is used when there is a delimiter at the end of the record.
Loading Delimited Text Data from AWS S3 Storage Using COPY VWLOAD
Shown below are some examples of how to load delimited text data stored on AWS S3 storage using COPY VWLOAD.
Example 1: COPY VWLOAD SQL to load a delimited text file with header row
Here is a sample of the data file stored as a CSV file with header on AWS S3 storage:
ID,Title,Year,Age,IMDb,RottenTomatoes,Netflix,Hulu,PrimeVideo,Disney,Type
0,Breaking Bad,2008,18+,9.5,96%,1,0,0,0,1
1,Stranger Things,2016,16+,8.8,93%,1,0,0,0,1
2,Money Heist,2017,18+,8.4,91%,1,0,0,0,1
3,Sherlock,2010,16+,9.1,78%,1,0,0,0,1
4,Better Call Saul,2015,18+,8.7,97%,1,0,0,0,1
5,The Office,2005,16+,8.9,81%,1,0,0,0,1
6,Black Mirror,2011,18+,8.8,83%,1,0,0,0,1
7,Supernatural,2005,16+,8.4,93%,1,0,0,0,1
8,Peaky Blinders,2013,18+,8.8,92%,1,0,0,0,1
0,Breaking Bad,2008,18+,9.5,96%,1,0,0,0,1
1,Stranger Things,2016,16+,8.8,93%,1,0,0,0,1
2,Money Heist,2017,18+,8.4,91%,1,0,0,0,1
3,Sherlock,2010,16+,9.1,78%,1,0,0,0,1
4,Better Call Saul,2015,18+,8.7,97%,1,0,0,0,1
5,The Office,2005,16+,8.9,81%,1,0,0,0,1
6,Black Mirror,2011,18+,8.8,83%,1,0,0,0,1
7,Supernatural,2005,16+,8.4,93%,1,0,0,0,1
8,Peaky Blinders,2013,18+,8.8,92%,1,0,0,0,1
DROP TABLE IF EXISTS tvshows;
CREATE TABLE tvshows (
id INTEGER,
title VARCHAR(70),
year INTEGER,
age VARCHAR(5),
imdb FLOAT,
rottentomatoes VARCHAR(5),
netflix INTEGER,
hulu INTEGER,
primevideo INTEGER,
disney INTEGER,
type INTEGER);
COPY tvshows() VWLOAD FROM 's3a://avtvshows/tv_shows.csv'
WITH
AWS_ACCESS_KEY='<aws_access_key>',
AWS_SECRET_KEY='<aws_secret_key>',
AWS_REGION='<aws_region_name>',
FDELIM=',',
QUOTE='""',
HEADER;
CREATE STATISTICS FOR tvshows;
SELECT * FROM tvshows;
Note: After the data is loaded, we recommend that you run the CREATE STATISTICS command, as shown above. It improves performance, especially for large data sets.
Example 2: COPY VWLOAD SQL to load a delimited text file with no header row and a comma at the end of each record
Here is a sample of the data file stored as a CSV file with no header and delimiter at end of record on AWS S3 storage:
0,Breaking Bad,2008,18+,9.5,96%,1,0,0,0,1,
1,Stranger Things,2016,16+,8.8,93%,1,0,0,0,1,
2,Money Heist,2017,18+,8.4,91%,1,0,0,0,1,
3,Sherlock,2010,16+,9.1,78%,1,0,0,0,1,
4,Better Call Saul,2015,18+,8.7,97%,1,0,0,0,1,
5,The Office,2005,16+,8.9,81%,1,0,0,0,1,
6,Black Mirror,2011,18+,8.8,83%,1,0,0,0,1,
7,Supernatural,2005,16+,8.4,93%,1,0,0,0,1,
8,Peaky Blinders,2013,18+,8.8,92%,1,0,0,0,1,
1,Stranger Things,2016,16+,8.8,93%,1,0,0,0,1,
2,Money Heist,2017,18+,8.4,91%,1,0,0,0,1,
3,Sherlock,2010,16+,9.1,78%,1,0,0,0,1,
4,Better Call Saul,2015,18+,8.7,97%,1,0,0,0,1,
5,The Office,2005,16+,8.9,81%,1,0,0,0,1,
6,Black Mirror,2011,18+,8.8,83%,1,0,0,0,1,
7,Supernatural,2005,16+,8.4,93%,1,0,0,0,1,
8,Peaky Blinders,2013,18+,8.8,92%,1,0,0,0,1,
DROP TABLE IF EXISTS tvshows;
CREATE TABLE tvshows (
id INTEGER,
title VARCHAR(70),
year INTEGER,
age VARCHAR(5),
imdb FLOAT,
rottentomatoes VARCHAR(5),
netflix INTEGER,
hulu INTEGER,
primevideo INTEGER,
disney INTEGER,
type INTEGER);
COPY tvshows() VWLOAD FROM 's3a://avtvshows/tv_shows2.csv'
WITH
AWS_ACCESS_KEY='<aws_access_key>',
AWS_SECRET_KEY='<aws_secret_key>',
AWS_REGION='<aws_region_name>',
FDELIM=',',
QUOTE='""'
IGNLAST;
CREATE STATISTICS FOR tvshows;
SELECT * FROM tvshows;
Note: After the data is loaded, we recommend that you run the CREATE STATISTICS command, as shown above. It improves performance, especially for large data sets.
Loading Delimited Text Data from External Tables (SQL)
Note: Before you can access external tables in your SQL, you must set up cloud authentication credentials for your warehouse. See Grant Access to Warehouse or Database for External Tables Access.
For more information about external tables, see Using External Tables.
External tables use Apache Spark underneath to reference and load external data into the Actian warehouse. This in turn has been wrapped in a native Actian Data Platform SQL command to aid ease of use.
Loading Delimited Text Data from Google Cloud Storage Using External Tables
Shown below are some examples of how to load delimited text data stored on Google Cloud storage using external tables.
Example 1: Delimited text file with a header row
Here is a sample of the data file stored as a CSV file with a header row on Google Cloud storage:
ID,Title,Year,Age,IMDb,RottenTomatoes,Netflix,Hulu,Prime Video,Disney,Type
0,Breaking Bad,2008,18+,9.5,96%,1,0,0,0,1
1,Stranger Things,2016,16+,8.8,93%,1,0,0,0,1
2,Money Heist,2017,18+,8.4,91%,1,0,0,0,1
3,Sherlock,2010,16+,9.1,78%,1,0,0,0,1
4,Better Call Saul,2015,18+,8.7,97%,1,0,0,0,1
5,The Office,2005,16+,8.9,81%,1,0,0,0,1
6,Black Mirror,2011,18+,8.8,83%,1,0,0,0,1
7,Supernatural,2005,16+,8.4,93%,1,0,0,0,1
8,Peaky Blinders,2013,18+,8.8,92%,1,0,0,0,1
0,Breaking Bad,2008,18+,9.5,96%,1,0,0,0,1
1,Stranger Things,2016,16+,8.8,93%,1,0,0,0,1
2,Money Heist,2017,18+,8.4,91%,1,0,0,0,1
3,Sherlock,2010,16+,9.1,78%,1,0,0,0,1
4,Better Call Saul,2015,18+,8.7,97%,1,0,0,0,1
5,The Office,2005,16+,8.9,81%,1,0,0,0,1
6,Black Mirror,2011,18+,8.8,83%,1,0,0,0,1
7,Supernatural,2005,16+,8.4,93%,1,0,0,0,1
8,Peaky Blinders,2013,18+,8.8,92%,1,0,0,0,1
DROP TABLE IF EXISTS tvshows_ext;
CREATE EXTERNAL TABLE tvshows_ext(
id INTEGER,
title VARCHAR(70),
year INTEGER,
age VARCHAR(5),
imdb FLOAT,
rottentomatoes VARCHAR(5),
netflix INTEGER,
hulu INTEGER,
primevideo INTEGER,
disney INTEGER,
type INTEGER) using spark
WITH
reference='gs://avtvshows/tv_shows.csv', format='csv',
options=('header'='true', 'quote'='"', 'nullValue'='null', 'sep'=',');
DROP TABLE IF EXISTS tvshows;
CREATE TABLE tvshows AS SELECT * FROM tvshows_ext;
CREATE STATISTICS FOR tvshows;
SELECT * FROM tvshows;
Note: After the data is loaded, we recommend that you run the CREATE STATISTICS command, as shown above. It improves performance, especially for large data sets.
Notes:
1. If you have multiple files to load and they all have the same schema/columns, you can use a wildcard in your file(s) reference. Example: 'gs://avtvshows/tv_shows*.csv'. You may also use wildcards in folder names in buckets.
Example 2: Delimited text file with no header row
Here is a sample of the data file stored as a CSV file with no header row on Google Cloud Storage:
0,Breaking Bad,2008,18+,9.5,96%,1,0,0,0,1
1,Stranger Things,2016,16+,8.8,93%,1,0,0,0,1
2,Money Heist,2017,18+,8.4,91%,1,0,0,0,1
3,Sherlock,2010,16+,9.1,78%,1,0,0,0,1
4,Better Call Saul,2015,18+,8.7,97%,1,0,0,0,1
5,The Office,2005,16+,8.9,81%,1,0,0,0,1
6,Black Mirror,2011,18+,8.8,83%,1,0,0,0,1
7,Supernatural,2005,16+,8.4,93%,1,0,0,0,1
8,Peaky Blinders,2013,18+,8.8,92%,1,0,0,0,1
9,Avatar: The Last Airbender,2005,7+,9.2,100%,1,0,0,0,1
1,Stranger Things,2016,16+,8.8,93%,1,0,0,0,1
2,Money Heist,2017,18+,8.4,91%,1,0,0,0,1
3,Sherlock,2010,16+,9.1,78%,1,0,0,0,1
4,Better Call Saul,2015,18+,8.7,97%,1,0,0,0,1
5,The Office,2005,16+,8.9,81%,1,0,0,0,1
6,Black Mirror,2011,18+,8.8,83%,1,0,0,0,1
7,Supernatural,2005,16+,8.4,93%,1,0,0,0,1
8,Peaky Blinders,2013,18+,8.8,92%,1,0,0,0,1
9,Avatar: The Last Airbender,2005,7+,9.2,100%,1,0,0,0,1
DROP TABLE IF EXISTS tvshows_ext;
CREATE EXTERNAL TABLE tvshows_ext (
id INTEGER,
title VARCHAR(70),
year INTEGER,
age VARCHAR(5),
imdb FLOAT,
rottentomatoes VARCHAR(5),
netflix INTEGER,
hulu INTEGER,
primevideo INTEGER,
disney INTEGER,
type INTEGER) using spark
WITH
reference='gs://avtvshows/tv_shows2.csv',
format='csv',
options=('header'='false', 'quote'='"','nullValue'='null', 'sep'=',',
'schema'='id integer,
title string,
year integer,
age string,
imdb double,
rottentomatoes string,
netflix integer,
hulu integer,
primevideo integer,
disney integer,
type integer');
DROP TABLE IF EXISTS tvshows;
CREATE TABLE tvshows AS SELECT * FROM tvshows_ext;
CREATE STATISTICS FOR tvshows;
SELECT * FROM tvshows;
Note: After the data is loaded, we recommend that you run the CREATE STATISTICS command, as shown above. It improves performance, especially for large data sets.
Loading Delimited Text Data from Azure Blob Storage Using External Tables
Shown below are some examples of how to load delimited text data stored on Azure Blob storage using external tables.
Example 1: CSV file with header row
Here is a sample of the data file stored as a CSV file with a header row on Azure Blob storage:
ID,Title,Year,Age,IMDb,RottenTomatoes,Netflix,Hulu,PrimeVideo,Disney,Type
0,Breaking Bad,2008,18+,9.5,96%,1,0,0,0,1
1,Stranger Things,2016,16+,8.8,93%,1,0,0,0,1
2,Money Heist,2017,18+,8.4,91%,1,0,0,0,1
3,Sherlock,2010,16+,9.1,78%,1,0,0,0,1
4,Better Call Saul,2015,18+,8.7,97%,1,0,0,0,1
5,The Office,2005,16+,8.9,81%,1,0,0,0,1
6,Black Mirror,2011,18+,8.8,83%,1,0,0,0,1
7,Supernatural,2005,16+,8.4,93%,1,0,0,0,1
8,Peaky Blinders,2013,18+,8.8,92%,1,0,0,0,1
0,Breaking Bad,2008,18+,9.5,96%,1,0,0,0,1
1,Stranger Things,2016,16+,8.8,93%,1,0,0,0,1
2,Money Heist,2017,18+,8.4,91%,1,0,0,0,1
3,Sherlock,2010,16+,9.1,78%,1,0,0,0,1
4,Better Call Saul,2015,18+,8.7,97%,1,0,0,0,1
5,The Office,2005,16+,8.9,81%,1,0,0,0,1
6,Black Mirror,2011,18+,8.8,83%,1,0,0,0,1
7,Supernatural,2005,16+,8.4,93%,1,0,0,0,1
8,Peaky Blinders,2013,18+,8.8,92%,1,0,0,0,1
DROP TABLE IF EXISTS tvshows_ext;
CREATE EXTERNAL TABLE tvshows_ext(
id INTEGER,
title VARCHAR(70),
year INTEGER,
age VARCHAR(5),
imdb FLOAT,
rottentomatoes VARCHAR(5),
netflix INTEGER,
hulu INTEGER,
primevideo INTEGER,
disney INTEGER,
type INTEGER) using spark
WITH
reference='abfs://tvshows@avtvshowdata.dfs.core.windows.net/tv_shows.csv', format='csv',
options=('header'='true', 'quote'='"', 'nullValue'='null', 'sep'=',');
DROP TABLE IF EXISTS tvshows;
CREATE TABLE tvshows AS SELECT * FROM tvshows_ext;
CREATE STATISTICS FOR tvshows;
SELECT * FROM tvshows;
Note: After the data is loaded, we recommend that you run the CREATE STATISTICS command, as shown above. It improves performance, especially for large data sets.
Notes:
1. Before doing the CTAS or load operation (CREATE TABLE <Actian Data Platform_table_name> as SELECT * FROM <external_table_name> ) ensure you can do a SELECT * FROM that external table.
2. Column names are case insensitive by default.
3. If that does not work, narrow down the offending column or columns in incremental steps by doing SELECT <column1> FROM <external table>, and adding more columns as you go to find the offending column or columns.
4. Not only can filenames use wildcards but with Azure Blob storage, you can use wildcards for Object Store virtual folders and filenames. For example, the following CSV files from 2011:
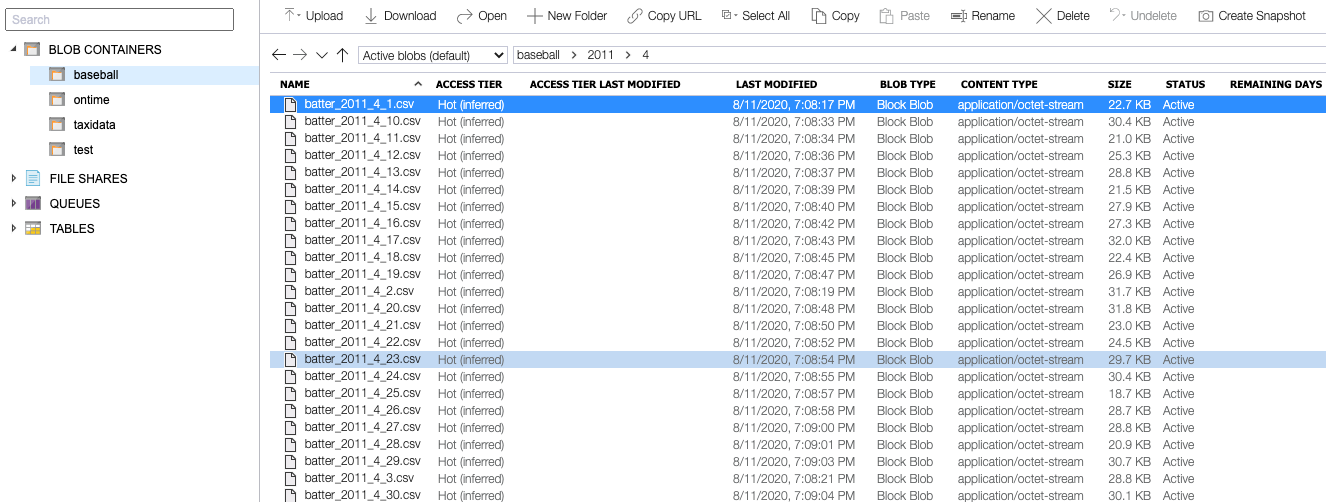
could be referenced with:
abfs://baseball@eastusontime.dfs.core.windows.net/2011/*/batter*.csv
where baseball is the container, eastusontime.dfs.core.windows.net is the storage account, 2011 is the virtual folder for the year, * is a wildcard for the month, and batter*.csv refers to the filenames. Note that when using wildcards, you cannot load files with duplicate names; for example, you could not have batter_2011_4_1.csv in multiple virtual directories.
5. To see the available CSV options, see Delimiter Text File Switches.
Example 2: CSV file with no header row
Here is a sample of the data file stored as a CSV file with no header row on Azure Blob storage:
0,Breaking Bad,2008,18+,9.5,96%,1,0,0,0,1
1,Stranger Things,2016,16+,8.8,93%,1,0,0,0,1
2,Money Heist,2017,18+,8.4,91%,1,0,0,0,1
3,Sherlock,2010,16+,9.1,78%,1,0,0,0,1
4,Better Call Saul,2015,18+,8.7,97%,1,0,0,0,1
5,The Office,2005,16+,8.9,81%,1,0,0,0,1
6,Black Mirror,2011,18+,8.8,83%,1,0,0,0,1
7,Supernatural,2005,16+,8.4,93%,1,0,0,0,1
8,Peaky Blinders,2013,18+,8.8,92%,1,0,0,0,1
9,Avatar: The Last Airbender,2005,7+,9.2,100%,1,0,0,0,1
1,Stranger Things,2016,16+,8.8,93%,1,0,0,0,1
2,Money Heist,2017,18+,8.4,91%,1,0,0,0,1
3,Sherlock,2010,16+,9.1,78%,1,0,0,0,1
4,Better Call Saul,2015,18+,8.7,97%,1,0,0,0,1
5,The Office,2005,16+,8.9,81%,1,0,0,0,1
6,Black Mirror,2011,18+,8.8,83%,1,0,0,0,1
7,Supernatural,2005,16+,8.4,93%,1,0,0,0,1
8,Peaky Blinders,2013,18+,8.8,92%,1,0,0,0,1
9,Avatar: The Last Airbender,2005,7+,9.2,100%,1,0,0,0,1
DROP TABLE IF EXISTS tvshows_ext;
CREATE EXTERNAL TABLE tvshows_ext (
id integer,
title varchar(70),
year integer,
age varchar(5),
imdb float,
rottentomatoes varchar(5),
netflix integer,
hulu integer,
primevideo integer,
disney integer,
type integer) using spark
WITH
reference='abfs://data@avtvshows.dfs.core.windows.net/tv_shows2.csv',
format='csv',
options=('header'='false', 'quote'='"','nullValue'='null', 'sep'=',',
'schema'='id integer,
title string,
year integer,
age string,
imdb double,
rottentomatoes string,
netflix integer,
hulu integer,
primevideo integer,
disney integer,
type integer');
DROP TABLE IF EXISTS tvshows;
CREATE TABLE tvshows AS SELECT * FROM tvshows_ext;
CREATE STATISTICS FOR tvshows;
SELECT * FROM tvshows;
Note: After the data is loaded, we recommend that you run the CREATE STATISTICS command, as shown above. It improves performance, especially for large data sets.
Notes:
1. When the target CSV file has no header row, you must use the schema option to map Actian Data Platform datatypes to Spark data types.
3. The schema option does not allow for columns with spaces, so you need to ensure column names have no spaces.
Loading Delimited Text Data from AWS S3 Storage Using External Tables
Shown below are some examples of how to load delimited text data stored on Amazon S3 storage using external tables.
Example 1: Delimited text file with a header row
Here is a sample of the data file stored as a CSV file with a header row on AWS S3 storage:
ID,Title,Year,Age,IMDb,RottenTomatoes,Netflix,Hulu,Prime Video,Disney,Type
0,Breaking Bad,2008,18+,9.5,96%,1,0,0,0,1
1,Stranger Things,2016,16+,8.8,93%,1,0,0,0,1
2,Money Heist,2017,18+,8.4,91%,1,0,0,0,1
3,Sherlock,2010,16+,9.1,78%,1,0,0,0,1
4,Better Call Saul,2015,18+,8.7,97%,1,0,0,0,1
5,The Office,2005,16+,8.9,81%,1,0,0,0,1
6,Black Mirror,2011,18+,8.8,83%,1,0,0,0,1
7,Supernatural,2005,16+,8.4,93%,1,0,0,0,1
8,Peaky Blinders,2013,18+,8.8,92%,1,0,0,0,1
0,Breaking Bad,2008,18+,9.5,96%,1,0,0,0,1
1,Stranger Things,2016,16+,8.8,93%,1,0,0,0,1
2,Money Heist,2017,18+,8.4,91%,1,0,0,0,1
3,Sherlock,2010,16+,9.1,78%,1,0,0,0,1
4,Better Call Saul,2015,18+,8.7,97%,1,0,0,0,1
5,The Office,2005,16+,8.9,81%,1,0,0,0,1
6,Black Mirror,2011,18+,8.8,83%,1,0,0,0,1
7,Supernatural,2005,16+,8.4,93%,1,0,0,0,1
8,Peaky Blinders,2013,18+,8.8,92%,1,0,0,0,1
DROP TABLE IF EXISTS tvshows_ext;
CREATE EXTERNAL TABLE tvshows_ext(
id INTEGER,
title VARCHAR(70),
year INTEGER,
age VARCHAR(5),
imdb FLOAT,
rottentomatoes VARCHAR(5),
netflix INTEGER,
hulu INTEGER,
primevideo INTEGER,
disney INTEGER,
type INTEGER) using spark
WITH
reference='s3a://avtvshows/tv_shows.csv', format='csv',
options=('header'='true', 'quote'='"', 'nullValue'='null', 'sep'=',');
DROP TABLE IF EXISTS tvshows;
CREATE TABLE tvshows AS SELECT * FROM tvshows_ext;
CREATE STATISTICS FOR tvshows;
SELECT * FROM tvshows;
Note: After the data is loaded, we recommend that you run the CREATE STATISTICS command, as shown above. It improves performance, especially for large data sets.
Notes:
1. If you have multiple files to load and they all have the same schema/columns, you can use a wildcard in your file(s) reference. Example: 's3a://avtvshows/tv_shows*.csv'. You may also use wildcards in folder names in buckets.
Example 2: Delimited text file with no header row
Here is a sample of the data file stored as a CSV file with no header row on AWS S3 storage:
0,Breaking Bad,2008,18+,9.5,96%,1,0,0,0,1
1,Stranger Things,2016,16+,8.8,93%,1,0,0,0,1
2,Money Heist,2017,18+,8.4,91%,1,0,0,0,1
3,Sherlock,2010,16+,9.1,78%,1,0,0,0,1
4,Better Call Saul,2015,18+,8.7,97%,1,0,0,0,1
5,The Office,2005,16+,8.9,81%,1,0,0,0,1
6,Black Mirror,2011,18+,8.8,83%,1,0,0,0,1
7,Supernatural,2005,16+,8.4,93%,1,0,0,0,1
8,Peaky Blinders,2013,18+,8.8,92%,1,0,0,0,1
9,Avatar: The Last Airbender,2005,7+,9.2,100%,1,0,0,0,1
1,Stranger Things,2016,16+,8.8,93%,1,0,0,0,1
2,Money Heist,2017,18+,8.4,91%,1,0,0,0,1
3,Sherlock,2010,16+,9.1,78%,1,0,0,0,1
4,Better Call Saul,2015,18+,8.7,97%,1,0,0,0,1
5,The Office,2005,16+,8.9,81%,1,0,0,0,1
6,Black Mirror,2011,18+,8.8,83%,1,0,0,0,1
7,Supernatural,2005,16+,8.4,93%,1,0,0,0,1
8,Peaky Blinders,2013,18+,8.8,92%,1,0,0,0,1
9,Avatar: The Last Airbender,2005,7+,9.2,100%,1,0,0,0,1
DROP TABLE IF EXISTS tvshows_ext;
CREATE EXTERNAL TABLE tvshows_ext (
id INTEGER,
title VARCHAR(70),
year INTEGER,
age VARCHAR(5),
imdb FLOAT,
rottentomatoes VARCHAR(5),
netflix INTEGER,
hulu INTEGER,
primevideo INTEGER,
disney INTEGER,
type INTEGER) using spark
WITH
reference='s3a://avtvshows/tv_shows2.csv',
format='csv',
options=('header'='false', 'quote'='"','nullValue'='null', 'sep'=',',
'schema'='id integer,
title string,
year integer,
age string,
imdb double,
rottentomatoes string,
netflix integer,
hulu integer,
primevideo integer,
disney integer,
type integer');
DROP TABLE IF EXISTS tvshows;
CREATE TABLE tvshows AS SELECT * FROM tvshows_ext;
CREATE STATISTICS FOR tvshows;
SELECT * FROM tvshows;
Note: After the data is loaded, we recommend that you run the CREATE STATISTICS command, as shown above. It improves performance, especially for large data sets.
Last modified date: 06/02/2026