Converting Data Files
Zen includes tools that convert Btrieve files to take advantage of features in the latest versions of the Zen engines. The following topics cover the concepts and tools for doing these conversions:
Rebuild Tool Concepts
The Rebuild tool allows you to perform the following operations on MicroKernel data files and dictionary files:
• Convert older file formats to a newer Zen format.
• Convert newer file formats to a format not older than a 6.x format.
• Rebuild a file using the same file format, provided the format is 6.x, 7.x, 8.x, 9.5, or 13.0.
• Add file indexes.
• Change file page size.
• Rebuild files to retain, add, or drop system data and system keys.
• Specify a location and name of the log file used by Rebuild.
If your database uses dictionary files (DDFs), you must rebuild them as well as the data files.
Read further in this section to understand the conceptual aspects of rebuilding data files.
• Log File
For information on using the Rebuild tools, see one of these topics:
Platforms Supported
Rebuild comes in two forms: a 32-bit GUI version for Windows, and command line versions for Linux, macOS, Raspbian, and Windows. See Rebuild Tool GUI Reference and CLI Rebuild Tasks.
Linux, macOS, and Raspbian CLI Rebuild
Rebuild runs as a program, rbldcli, on Linux, macOS, and Raspbian. By default, the program is located in /usr/local/actianzen/bin.
Windows CLI Rebuild
Rebuild runs as a program, rbldcli.exe, on Windows. By default, the program is installed in the Program Files directory.
File Formats
The current database engines remain compatible with some older data and dictionary file formats, but you may want to convert files to the current format to take advantage of current features. The following table lists common reasons for converting from an older to a newer format.
Original File Format | Converted File Format | Reason for Conversion |
|---|---|---|
9.5 | 13.0 | File sizes in the terabytes. Ability to add system data v2. |
9.0 | 9.5 | More than 119 segment keys and files sizes up to 256 GB. |
8.x | 9.x | Add support for file sizes up to 128 GB. |
8.x | 8.x | Remove deleted record space from a file, change the page size, or add system data. |
Pre-8.x | 8.x | Take advantage of insert, update, and delete performance improvements offered by Turbo Write Accelerator. |
7.x | 7.x | Original file does not have a system key. |
Pre-7.x | 7.x | Take advantage of 7.x features and improve general performance. |
Pre-6.0 | 6.x | Take advantage of 6.x features and improve general performance. Use this option only if you are running 6.x engines. |
The file format that results from using the command line Rebuild depends on the -f parameter. If you omit the -f parameter, then Rebuild uses the value for the Create File Version setting in the MicroKernel Engine. For example, if the Create File Version value is 9.5, then running the Rebuild tool on version 9.0 files converts them to 9.5 format.
It is suggested that you back up all the data files you plan to convert before running Rebuild. This is particularly true if you are rebuilding files to the same location as the source files (in which case the rebuilt files replace the source files). Having backup copies allows you to restore the original files if you so desire. To ensure that the backup is successful, you may perform one or more of the following operations:
• Close all data files before running a backup.
• Use continuous operations (only during the backup).
Note: You cannot run Rebuild on a file that is in continuous operation mode.
Temporary Files
On Windows, Rebuild creates temporary files in the directory specified by the TMP system environment variable. By default on Linux, macOS, and Raspbian, Rebuild creates temporary files in the output directory (or in the source directory if the -b option is not used). Therefore, you need enough disk space in the temporary file directory (while Rebuild is running) to potentially accommodate both the original file and the new file. You can specify a different directory for storing these files by using the Output Directory option in the Rebuild GUI version or by using the -b option with the CLI versions.
Normally, Rebuild deletes temporary files when the conversion is complete. However, if a power failure or other serious interruption occurs, Rebuild may not delete the temporary files. If this occurs, you must manually delete the types of temporary files shown in the following table.
Platform | Temporary File Names |
|---|---|
Linux, macOS, Raspbian | _rbldxxxxxx, where xxxxxx is 6 random characters. Caution: Be sure that you do not delete the Rebuild executable, rbldcli. |
Windows | _rbldx, where x is a number. |
Optimizing the Rebuild Process
Rebuild makes Btrieve calls to the database engine. Therefore, the database engine configuration settings and the amount of processing memory affect the performance of the rebuild process, particularly with respect to the amount of time required to rebuild large data files.
In general, building indexes requires much more time than building data pages. If you have a data file with many indexes, it requires more time to rebuild than would the same file with fewer indexes.
The following items can affect the rebuild processing time:
CPU Speed and Disk Speed
The speed of the central processing unit (CPU) and access speed of the physical storage disk can affect processing time during a rebuild. In general, the faster the speed for both of these, the faster the rebuild process. Disk speed is more critical for rebuilding files that are too large to fit entirely in memory.
Tip... Large files in the gigabyte range may take several hours to convert. If you have more than one database engine available, you may wish to share the rebuild processing among a number of machine CPUs. For example, you could copy some of your files to each machine that has a database engine installed, then after the rebuild process is finished, copy the files back to their original locations.
Amount of Memory
Rebuild is capable of rebuilding a file using two different methods, a default method and an alternative method. See -m<0 | 2> parameter. The method chosen depends on the amount of memory available. For the default method (-m2), Rebuild takes the following steps provided available memory exists:
1. Create a new, empty data file with the same record structure and indexes defined in the source file.
2. Drop all the indexes from the new file.
3. Copy all the data into the new file, without indexes.
4. Add the indexes, using the following process:
a. For a particular key in the source file, read as many key values as possible into a memory buffer using the Extended Step operation.
b. Sort the values in the memory buffer and write the sorted values to a temporary file.
The temporary file now contains several key value sets, each of which has been individually sorted.
5. Merge the sets into index pages, filling each page to capacity. Each index page is added to the data file at the end, extending the file length.
If any failure occurs during this process, such as a failure to open or write the temporary file, Rebuild starts over and uses the alternative method to build the file.
Rebuild uses an alternative method (-m0) when insufficient memory exists to use the default method, or if the default method encounters processing errors.
1. Create a new, empty data file with the same record structure and indexes defined in the source file.
2. Drop all the indexes from the new file.
3. Copy all the data into the new file, without indexes.
4. Add the indexes, in the following sequence:
a. For a particular key in the source file, read one record at a time using the Step Next operation.
b. Extract the key value from the record and insert it into the appropriate place in the index. This necessitates splitting key pages when they get full.
5. Repeat step 4 for each remaining key.
The alternative method is typically much slower than the default method. If you have large data files with many indexes, the difference between the two methods can amount to many hours or even days. The only way to ensure that Rebuild uses the default method is to have enough available memory. Several configuration settings can affect the amount of available memory.
Formulas For Estimating Memory Requirements
The following formulas estimate the optimal and minimum amount of contiguous free memory required to rebuild file indexes using the fast method. The optimal memory amount is enough memory to store all merge blocks in RAM. The minimum amount of memory is enough to store one merge block in RAM.
Key Length = total size of all segments of largest key in the file.
Key Overhead = 8 if key type is not linked duplicate. 12 if key type is linked duplicate.
Record Count = number of records in the file.
Optimal Memory Bytes = (((Key Length + Key Overhead) * Record Count) + 65536) / 0.6
Minimum Memory Bytes = Optimal Memory Bytes / 30
For example, if your file has 8 million records, and the longest key is 20 bytes (not linked duplicate), the preferred amount of memory is 373.5 MB, or ((( 20 + 8 ) * 8,000,000 ) + 65536 ) / 0.6 = 373,442,560 bytes.
The optimal amount of contiguous free memory is 373.5 MB. If you have at least this much free memory available, the Rebuild process takes place entirely in RAM. Because of the 60% allocation limit, the optimal amount of memory is actually the amount required to be free when the rebuild process starts, not the amount that the rebuild process actually uses. Multiply this optimal amount by 0.6 to determine the maximum amount Rebuild actually uses.
The minimum amount of memory is 1/30th of the optimal amount, 12,448,086 bytes, or 12.45 MB.
The divisor 30 is used because the database engine keeps track of no more than 30 merge blocks at once, but only one merge block is required to be in memory at any time. The divisor 0.6 is used because the engine allocates no more than 60% of available physical memory for rebuild processing.
If you do not have the minimum amount of memory available, Rebuild uses the alternative method to rebuild your data file.
Finally, the memory block allocated must meet two additional criteria: blocks required and allocated block size.
Blocks required must be less than or equal to 30, where:
Blocks Required = Round Up (Optimal Memory Bytes / Allocated Block)
Allocated block size must be greater than or equal to:
((2 * Max Keys + 1) * (Key Length + Key Overhead)) * Blocks Required
Assuming a 512-byte page size, and a block of 12.45 MB successfully allocated, the value for blocks required is:
Blocks Required = 373,500,000 / 12,450,000 = 30
The first criteria is met.
The value for allocated block size is:
Max Keys = (512-12) / 28 = 18
(((2 * 18) + 1) * (20 + 8)) * 9 = 9324
Is Allocated Block (12.5 million bytes) larger than 9324 bytes? Yes, so the second criteria is met. The index keys will be written to a temporary file in 12.45 MB pieces, sorted in memory, and then written to the index.
Sort Buffer Size
This setting specifies the maximum amount of memory that the MicroKernel dynamically allocates and deallocates for sorting purposes during run-time creation of indexes.
If the setting is zero (the default), Rebuild calculates a value for optimal memory bytes and allocates memory based on that value. If the memory allocation succeeds, the size of the block allocated must be at least as large as the value defined for minimum memory bytes. See Formulas For Estimating Memory Requirements.
If the setting is a nonzero value, and the value is smaller than the calculated minimum memory bytes, Rebuild uses the value to allocate memory.
Finally, Rebuild compares the amount of memory that it should allocate with 60% of the amount that is actually available. It then attempts to allocate the smaller of the two. If the memory allocation fails, Rebuild keeps attempting to allocate 80% of the last attempted amount. If the memory allocation fails completely (which means the amount of memory is less than the minimum memory bytes), Rebuild uses the alternative method to rebuild the file.
Max MicroKernel Memory Usage
This setting specifies the maximum proportion of total physical memory that the MicroKernel is allowed to consume. L1, L2, and all miscellaneous memory usage by the MicroKernel are included. Usage by the Relational Engine is not included.
If you have large files to rebuild, temporarily set Max MicroKernel Memory Usage to a lower percentage than its default setting. Reset it to your preferred percentage after you complete your rebuilding.
Cache Allocation Size
This setting specifies the size of the Level 1 cache that the MicroKernel allocates. The MicroKernel uses this cache when accessing any data files.
This setting determines how much memory is available to the database engine for accessing data files, not for use when indexes are built.
Increasing Cache Allocation to a high value does not help indexes build faster. In fact, it may slow the process by taking up crucial memory that is now unavailable to Rebuild. When rebuilding large files, decrease the cache value to a low value, such as 20% of your current value but not less than 5 MB. This leaves as much memory as possible available for index rebuilding.
Index Page Size
The page size in your file also affects the speed of index building. If Rebuild uses the alternative method, smaller key pages dramatically increase the time required to build indexes. Key page size has a lesser effect on building indexes if Rebuild uses the default method.
Rebuild can optimize page size for application performance or for disk storage.
To optimize page size for performance in terms of speed of data access, Rebuild uses a default page size of 4096 bytes. This results in larger page sizes in physical storage and slower rebuilding times.
For a discussion of optimizing page size for disk storage, see Choosing a Page Size in Zen Programmer’s Guide.
Assume that your application has 8 million records, a 20-byte key, and uses a page size of 512 bytes. The MicroKernel places between 8 and 18 key values in each index page. This lessens the amount of physical storage required for each page. However, indexing 8 million records creates a B-tree about seven levels deep, with most of the key pages at the seventh level. Performance will be slower.
If you use a page size of 4096 bytes, the database engine places between 72 and 145 key values in each index page. This B-tree is only about four levels deep and requires many fewer pages to be examined when Rebuild inserts each new key value. Performance is increased but so is the requirement for the amount of physical storage.
Number of Indexes
The number of indexes also affects the speed of index building. Generally, the larger the number of indexes, the longer the rebuild process takes. The time required to build the indexes increases exponentially with increasing depth of the B-tree.
Log File
Information from a rebuild process is appended to a text log file. By default, the log file is placed in the current working directory.
For the CLI Rebuild, the default file name is rbldcli.log on Windows, Linux, macOS, and Raspbian. You may specify a location and name for the log file instead of using the defaults. See the -lfile parameter.
You use a text editor to read the log. The information logged includes the following:
• Start time of the rebuild process
• Parameters specified on the command line
• Status code and error description (if an error occurs)
• File being processed
• Information about the processing (such as page size changes)
• Total records processed
• Total indexes rebuilt (if the -m2 processing method is used)
• End time of the rebuild process
• Status of the process (for example, if the file rebuilt successfully)
Rebuild Tool GUI Reference
This topic describes the objects on the Rebuild tool graphical user interface.
File Options Screen
This screen allows you to add files to the rebuild list. 
GUI Object | Description | Related Information |
|---|---|---|
Selected files | The data and dictionary files listed for rebuilding according to your selections using the Add button. | |
Add button | Adds a data or dictionary file to the list of files to be rebuilt. | |
Remove button | Removes the selected data or dictionary file in the list. | |
Clear button | Clears the entire list of selected data and dictionary files. |
Rebuild Options Screen
This screen allows you to select the options for rebuilding files. Click any area of the image for which you want more information. 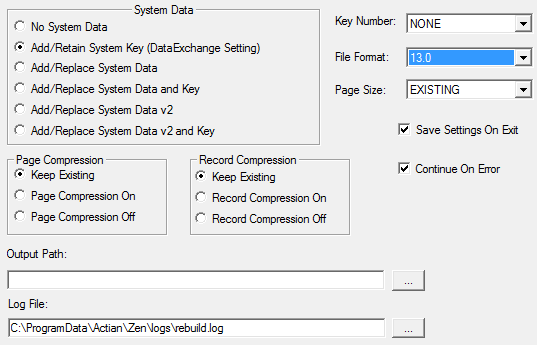
GUI Object | Description | Related Information |
|---|---|---|
System Data | Specifies whether Rebuild is to retain, add, or drop system data and keys. System data is used for transaction durability logging when no user-defined unique data key exists. System data v2 can in addition be used to track record updates. | |
Page Compression | Specifies if you want page compression for the file. The choices are Keep Existing, On, and Off. Keep Existing retains whatever page compression the file contains, if any. | Page compression requires a file format of 9.5 or newer. |
Record Compression | Specifies if you want record compression for the file. The choices are Keep Existing, On, and Off. Keep Existing retains whatever record compression the file contains, if any. | |
Continue on Error | Determines whether Rebuild continues if it encounters an error during the rebuild process. If you select Yes, the tool continues with the next file even if an error occurs. The tool notifies you of non-MicroKernel data files or other errors but continues rebuilding data files. If you select No, the tool halts the rebuild if it encounters an error. This option is useful if you have specified wildcard characters for the rebuilt files. | |
Save Settings on Exit | Saves the current values in this dialog box for use in subsequent Rebuild sessions. | |
Key Number | Specifies the key by which the tool reads when rebuilding a file. If you specify NONE for this option, the tool clones the files, drops the indexes, copies the records into the new files, and rebuilds the indexes. Because this method is faster and creates smaller files than specifying a key number, use it whenever possible. This method may create a new file in which the records are in a different physical order than in the original file. If you specify a key number, the tool clones and copies the files without dropping and replacing indexes. While this method is slower than specifying NONE, it is available in case you do not want to rebuild your indexes. | |
File Format | Previously, Rebuild used the file version in the Create File Version setting in the engine compatibility properties. The current Rebuild tool allows you to set the file version independently of that setting. | |
Page Size | Specifies the page size (in bytes) of the new files. Choose either EXISTING, Optimal (disk space), Optimal (data access), or a size in bytes. If you select EXISTING, the tool uses the existing page size. The tool changes the page size if the original size does not work. For example, assume you have a v5.x file with a page size of 1024 and 24 keys. Because Btrieve 6.0 and later supports only 23 keys for a page size of 1024, the tool automatically selects a new page size for the file and writes an informative message to the status file. | • For optimizing for data access, see Optimizing the Rebuild Process |
Output Path | Specifies an alternate location for the rebuilt files. (The default location is the current directory.) You must specify a directory that already exists. This option lets you rebuild large files on a different server. The MicroKernel and its communications components must be loaded on the server that contains the rebuilt files. Do not use wildcard characters in the path. If the Output Directory location is different than the original file's location, the original file is not deleted during the rebuild. If the output directory is the same as the original file, the original file is deleted upon completion of the rebuild. DefaultDB w/ DB security: Cannot rebuild outside DB's file locations in Maintain Named Databases | |
Log File | Specifies a location for the rebuild log file. (The default location is the current working directory.) Do not use wildcard characters in the path. | • Log File |
Using the Rebuild Tool
The following topics cover the GUI and command line versions of the Rebuild tool:
GUI Rebuild Tasks
To start the GUI Rebuild wizard
Select Tools > Rebuild in the Zen Control Center menu or access Rebuild from the operating system Start menu or Apps screen.
To rebuild a file or files
1. After you click Next at the Rebuild welcome screen, the Select Files screen appears.
2. Click Add and select the data or dictionary file you want to rebuild. You can select more than one file to rebuild at a time.
Figure 1 Select Files Dialog Box
Rebuild deletes the original file after rebuilding it if the file is being rebuilt in the same directory. If the new file is in a different directory, the original file is not deleted.
3. Click Next after you have added the desired file or files.
4. Specify the rebuild options. See Rebuild Options Screen.
5. Click Next to begin the rebuild process.
Rebuild reports the processing information. When the rebuild process finishes, its success or failure is displayed and View Log File is enabled.
6. To display the results, click View Log File. The contents of the log file display in the default text editor for the operating system.
Rebuild writes to the log file for every file it attempts to convert. If you disabled the Continue on Error setting, the log file contains the information up to the point of the error. If the rebuild was not successful, the status file contains error messages explaining why the rebuild failed.
7. Click Finish when you have finished rebuilding files and viewing the log file.
CLI Rebuild Tasks
The Rebuild command line tool is named rbldcli.exe on Windows and rbldcli on Linux, macOS, and Raspbian. The following topics cover command line syntax and typical Rebuild tasks:
Command Line Parameters
The parameter specifies the settings used with the tool. You may use the parameters in any order. Precede each parameter with a hyphen (-). Do not place a space after the hyphen or after the single-letter parameter and the parameter value.
Note: On Linux, macOS, and Raspbian, the parameters are case-sensitive.
Parameter is defined as follows:
-c | Instructs Rebuild to continue with the next data or dictionary file if an error occurs. The tool notifies you of non-MicroKernel data files or errors with MicroKernel files, but continues rebuilding data files. The errors are written to the log file. See Log File. Tip: This parameter is particularly useful if you specify wildcard characters (*.*) for a mixed set of files. Mixed set means a combination of MicroKernel files and non-MicroKernel files. Rebuild reports an error for each non-MicroKernel file (or any errors on MicroKernel files), but continues processing. |
-d | If you specify -d, Rebuild converts pre-6.0 supplemental indexes (which allow duplicates) to 6.x, 7.x, or 8.x indexes with linked-duplicatable keys. If you omit this parameter, Rebuild preserves the indexes as repeating-duplicatable keys. If you access your data files only through the MicroKernel Engine and your files have a relatively large number of duplicate keys, you can use the -d option to enhance the performance of the Get Next and Get Previous operations. |
-m<0 | 2> | The "m" parameter stands for "method." Rebuild selects a processing method whether you specify this parameter or not. If you omit this parameter, Rebuild does the following: • Uses -m2 as the default method if sufficient memory is available. • Uses the alternative method-m0 if memory is insufficient. See Amount of Memory for how the amount of memory affects the method chosen. |
0 | Clones and copies the data or dictionary file without dropping and replacing indexes. This method is slower than the -m2 method. It is available in case you do not want to rebuild your indexes. A file built with the -m0 creates a file where each key page is about 55% to 65% full. The file is more optimized for writing and less for reading. If you can afford the extra rebuild time, which can be considerable depending on the situation, you might want to rebuild a file optimized for writing. See also Optimizing the Rebuild Process. |
2 | Clones the data or dictionary file, drops the indexes, copies the records into the new file, and rebuilds the indexes. This method is faster and creates smaller files than the -m0 method. The -m2 method may create a file in which records differ in physical order from the original file. A file built with the -m2 method has key pages that are 100% full. This optimizes the file for reading. |
-p<D | P | bytes> | • Optimizes page size for disk storage or processing, or specifies a specific page size to use for the rebuilt file. • If you omit this parameter, Rebuild uses the page size from the source file. If the source page size does not work for the current database engine, Rebuild changes the page size and displays an informative message explaining the change. (For example, older file formats, such as 5.x, supported a page size of 1024 with 24 keys. File format 8.x supports only 23 keys for a page size of 1024, so Rebuild would select a different page size if building an 8.x file.) • The database engine may ignore the page size specified and automatically upgrade the page size. For example, for the 9.5 file format, odd page sizes such as 1536 and 3072 are not supported. The database engine automatically upgrades to the next valid page size because that page size is more efficient. For older file formats, the database engine may upgrade the page size based on additional conditions. See also Index Page Size. |
D | Optimizes page size for disk storage. See Choosing a Page Size in Zen Programmer’s Guide. |
P | Optimizes for processing (that is, for your application accessing its data). For -pP, Rebuild uses a default page size of 4096 bytes. |
bytes | Specifies the page size (in bytes) for the new file. For file versions before 9.0, valid values are 512, 1024, 1536, 2048, 2560, 3072, 3584, and 4096. For file version 9.0, the values are the same, with the addition of 8192. For file version 9.5, valid values are 1024, 2048, 4096, 8192, and 16384. For file version 13.0, valid values are 4096, 8192, and 16384. |
-bdirectoryname | Specifies an alternate location for the rebuilt file (which may also be a location on a different server). The default location is the directory where the data file is located. You must specify a location that already exists. Rebuild does not create a directory for you. The directory also must be on a machine that is running the database engine. You may use either a fully qualified path or a relative path. Do not use wildcard characters in directoryname. On your local server, the MicroKernel database engine and the Message Router must be loaded. On a remote server, the MicroKernel database engine and communications components must be loaded. If you omit this parameter, the rebuilt file replaces the original data file. A copy of the original file is not retained. If you specify this parameter, the rebuilt file is placed in the specified location and the original file is retained. An exception to this is if the specified location already contains data files with the same names. Rebuild fails if the alternate location you specify contains files with the same names as the source files. For example, suppose you want to rebuild mydata.mkd, which is in a directory named folder1. You want to place the rebuilt file into a directory named folder2. If mydata.mkd also exists in folder2 (perhaps unknown to you), Rebuild fails and informs you to check the log file. Note: Ensure that you have create file permission for the location you specify (or for the location of the source file if you omit the parameter). |
-knumber | Specifies the key number that Rebuild reads from the source file and uses to sort the rebuilt file. If you omit this parameter, Rebuild reads the source file in physical order and creates the rebuilt file in physical order. See also Optimizing the Rebuild Process. |
-s[D | K | 2D | 2K] | Rebuilds the file retaining existing system data and keys from the source file, or adding them if not present. If you omit this parameter, Rebuild does not retain any system data or key in the rebuilt file. |
D | Rebuilds the file with new system data. System data will not be indexed. |
K | Rebuilds the file with new system data. System data will be indexed. |
2D | Rebuilds the file with new system data v2. System data will not be indexed. For 13.0 format files only. |
2K | Rebuilds the file with new system data v2. System data will be indexed. For 13.0 format files only. |
-lfile | Specifies a file name, and optionally a path location, for the Rebuild log file. The default file name is rbldcli.log on Windows, Linux, macOS, and Raspbian. The default location is the current working directory. The following conditions apply: • The path location must already exist. Rebuild does not create the path location. • If you specify a path location without a file name, Rebuild ignores this parameter and uses the default file name and location. • If you specify a file name without a path location, Rebuild uses the default location. • You must have read and write file permission for the location you specify. Rebuild uses the default location if it cannot create the log file because of file permission. See also Log File. |
-pagecompresson | Turns on page compression for file provided the following conditions are true: • The version of the database engine is 9.5 or later. • The setting for Create File Version is 0950 (9.5) or later. |
-pagecompressoff | |
-recordcompresson | Turns on record compression for file. |
-recordcompressoff | |
-f<6 | 7 | 8 | 9 | 95 | 13> | Specifies a file format for the rebuilt data or dictionary file. File formats supported are versions 6.x, 7.x, 8.x, and 9.x. The following example rebuilds a file in 9.0 format: rbldcli -f9 file_path\class.mkd The following example rebuilds a file in 9.5 format: rbldcli -f95 file_path\class.mkd If omitted, Rebuild uses the value set for the MicroKernel Create File Version configuration setting. Note1: If you specify a file format newer than the version supported by the current database engine, Rebuild uses the highest supported file format of that engine. Rebuild reports no error or message for this. Note2: Rebuild does not convert data types in indexes. If you rebuild a file to an older file format for use with an older database engine, ensure that the engine supports the data types used. You must manually adjust data types as required by your application and by the database engine. Example1. Your data file contains index fields that use the WZSTRING data type. If you rebuild the data file to a 6.x file format, the WZSTRING data type is not converted. You would be unable to use the data file with a Btrieve 6.15 engine. That engine does not support the WZSTRING data type. Example 2. Your data file contains true NULLs. You rebuild the data file to a 7.x file format. The true NULLs are not converted. You would be unable to use the data file with the Zen 7 engine. That engine does not support true NULLs. |
-uiduname | Specifies the name of the user authorized to access a database with security enabled. |
-pwdpword | Specifies the password for the user identified by uname. Pword must be supplied if uname is specified. |
-dbdbname | Specifies the name of the database on which security is enabled. |
File and @command_file are defined as follows:
file | Specifies the data and dictionary files to convert. If the source file is not in the current working directory, include the location, either as a fully qualified path or as a relative path. You may use the asterisk (*) wildcard character in the file name to specify multiple files. Note: If the original file contains an owner name, Rebuild applies the owner name and level to the rebuilt file. |
@command_file | Specifies a command file for Rebuild to execute. You may include multiple entries in one command file. Each entry in the command file contains the command line parameters (if any) and the set of files to convert, followed by <end> or [end]. When specifying the files to convert, use full directory names. You may use the asterisk (*) wildcard character in the file names. The following is an example of a Rebuild command file: –c d:\mydir\*.* <end> –c –p1024 e:\dir\*.* <end> –m0 –k0 d:\ssql\*.* <end> |
To run Rebuild on Linux, macOS, and Raspbian
1. Ensure that the account under which you are logged in has permission to run Zen utilities.
By default, you must be logged in as user zen-svc to run utilities. User zen-svc has no password and can be accessed only through the root account by using the su command. To use utilities from accounts other than zen-svc, you must first make modifications to the .bash_profile. See Zen Account Management on Linux, macOS, and Raspbian in Getting Started with Zen.
2. Change directory to /usr/local/actianzen/bin directory.
3. Type one of the following commands at the prompt:
rbldcli [–parameter ...] file
or
rbldcli @command_file
Example Usage
The following example continues on error, sets a page size of 4096 bytes, and places the rebuilt files in a different directory on the server.
rbldcli -c -p4096 -b/usr/local/actianzen/tmp /usr/local/actianzen/data/Demodata/*.mkd
To run Rebuild on Windows
1. Open a command prompt on the system where Zen is installed.
2. Optionally, change to the \bin directory where you installed the program files. This is not required if the location is in the Path system variable.
3. Enter one of the following commands at the prompt:
rbldcli [–parameter ...] file
or
rbldcli @command_file
Example Usage
The following example continues on error, sets a page size of 4096 bytes, and places the rebuilt files in a different directory on the server.
rbldcli -c -p4096 -bc:\dbtemp c:\datafiles\*.mkd
To see your progress while rebuilding files
Rebuild reports on the screen the number of records processed per file, incrementing 50 records at a time. In addition, Rebuild writes information to a text log file. See Log File.
Last modified date: 10/31/2023